 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratizing LLMs for Low-Resource Languages by Leveraging their English Dominant Abilities with Linguistically-Diverse Prompts
Paper and Code
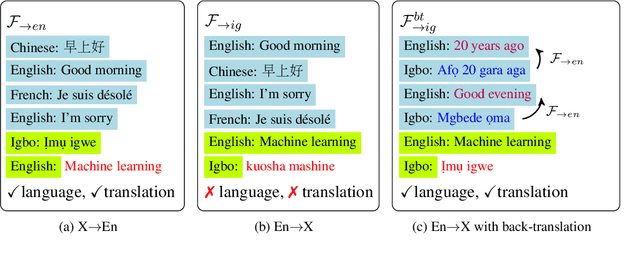
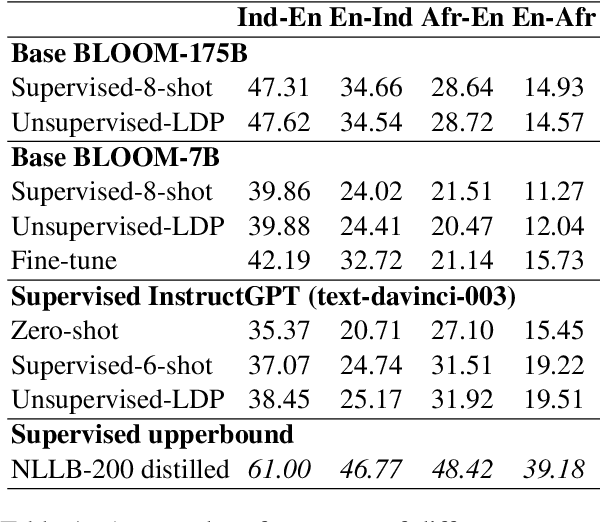

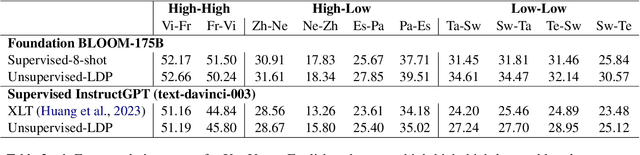
Large language models (LLMs) are known to effectively perform tasks by simply observing few exemplars. However, in low-resource languages, obtaining such hand-picked exemplars can still be challenging, where unsupervised techniques may be necessary. Moreover, competent generative capabilities of LLMs are observed only in high-resource languages, while their performances among under-represented languages fall behind due to pre-training data imbalance. To elicit LLMs' ability onto low-resource languages without any supervised data, we propose to assemble synthetic exemplars from a diverse set of high-resource languages to prompt the LLMs to translate from any language into English. These prompts are then used to create intra-lingual exemplars to perform tasks in the target languages. Our unsupervised prompting method performs on par with supervised few-shot learning in LLMs of different sizes for translations between English and 13 Indic and 21 African low-resource languages. We also show that fine-tuning a 7B model on data generated from our method helps it perform competitively with a 175B model. In non-English translation tasks, our method even outperforms supervised prompting by up to 3 chrF++ in many low-resource languages. When evaluated on zero-shot multilingual summarization, our method surpasses other English-pivoting baselines by up to 4 ROUGE-L and is also favored by GPT-4.