 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
POINTS: Improving Your Vision-language Model with Affordable Strategies
Sep 07, 2024In recent years, vision-language models have made significant strides, excelling in tasks like optical character recognition and geometric problem-solving. However, several critical issues remain: 1) Proprietary models often lack transparency about their architectures, while open-source models need more detailed ablations of their training strategies. 2) Pre-training data in open-source works is under-explored, with datasets added empirically, making the process cumbersome. 3) Fine-tuning often focuses on adding datasets, leading to diminishing returns. To address these issues, we propose the following contributions: 1) We trained a robust baseline model using the latest advancements in vision-language models, introducing effective improvements and conducting comprehensive ablation and validation for each technique. 2) Inspired by recent work on large language models, we filtered pre-training data using perplexity, selecting the lowest perplexity data for training. This approach allowed us to train on a curated 1M dataset, achieving competitive performance. 3) During visual instruction tuning, we used model soup on different datasets when adding more datasets yielded marginal improvements. These innovations resulted in a 9B parameter model that performs competitively with state-of-the-art models. Our strategies are efficient and lightweight, making them easily adoptable by the community.
EfficientRAG: Efficient Retriever for Multi-Hop Question Answering
Aug 08, 2024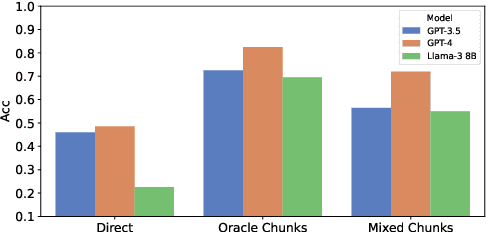
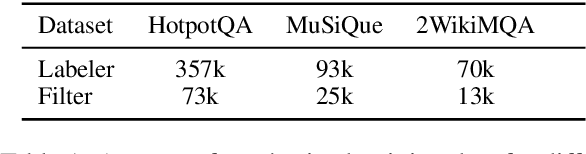
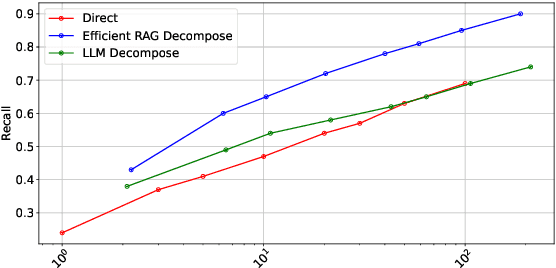
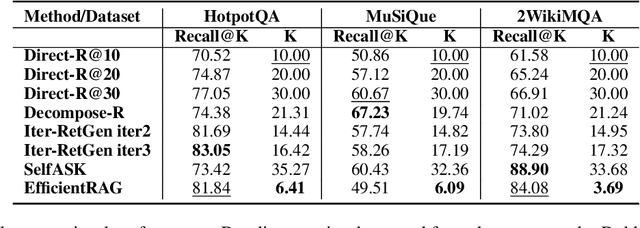
Retrieval-augmented generation (RAG) methods encounter difficulties when addressing complex questions like multi-hop queries. While iterative retrieval methods improve performance by gathering additional information, current approaches often rely on multiple calls of large language models (LLMs). In this paper, we introduce EfficientRAG, an efficient retriever for multi-hop question answering. EfficientRAG iteratively generates new queries without the need for LLM calls at each iteration and filters out irrelevant information. Experimental results demonstrate that EfficientRAG surpasses existing RAG methods on three open-domain multi-hop question-answering datasets.
Enforcing Paraphrase Generation via Controllable Latent Diffusion
Apr 13, 2024Paraphrase generation aims to produce high-quality and diverse utterances of a given text. Though state-of-the-art generation via the diffusion model reconciles generation quality and diversity, textual diffusion suffers from a truncation issue that hinders efficiency and quality control. In this work, we propose \textit{L}atent \textit{D}iffusion \textit{P}araphraser~(LDP), a novel paraphrase generation by modeling a controllable diffusion process given a learned latent space. LDP achieves superior generation efficiency compared to its diffusion counterparts. It facilitates only input segments to enforce paraphrase semantics, which further improves the results without external features. Experiments show that LDP achieves improved and diverse paraphrase generation compared to baselines. Further analysis shows that our method is also helpful to other similar text generations and domain adaptations. Our code and data are available at https://github.com/NIL-zhuang/ld4pg.
Call Me When Necessary: LLMs can Efficiently and Faithfully Reason over Structured Environments
Mar 13, 2024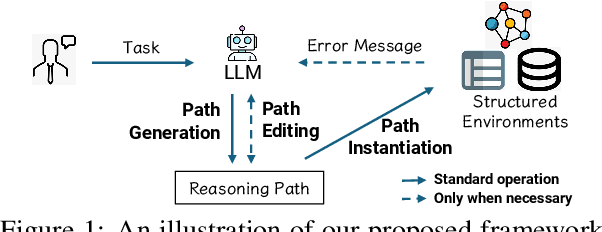
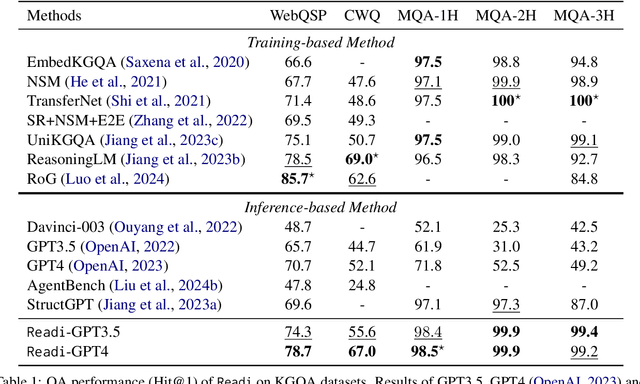
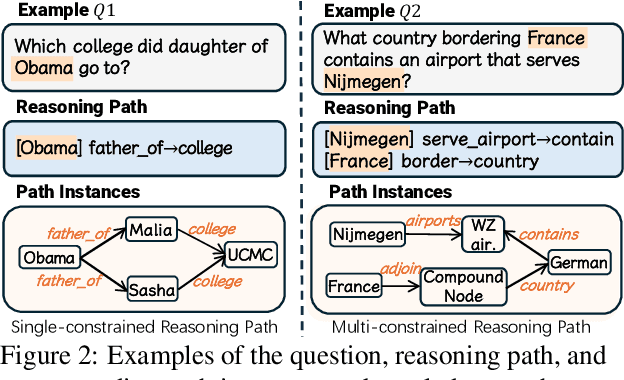
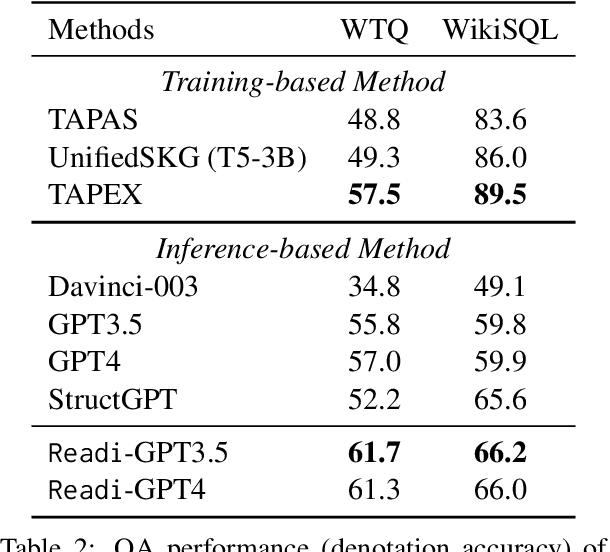
Large Language Models (LLMs) have shown potential in reasoning over structured environments, e.g., knowledge graph and table. Such tasks typically require multi-hop reasoning, i.e., match natural language utterance with instances in the environment. Previous methods leverage LLMs to incrementally build a reasoning path, where the LLMs either invoke tools or pick up schemas by step-by-step interacting with the environment. We propose Reasoning-Path-Editing (Readi), a novel framework where LLMs can efficiently and faithfully reason over structured environments. In Readi, LLMs initially generate a reasoning path given a query, and edit the path only when necessary. We instantiate the path on structured environments and provide feedback to edit the path if anything goes wrong. Experimental results on three KGQA datasets and two TableQA datasets show the effectiveness of Readi, significantly surpassing all LLM-based methods (by 9.1% on WebQSP, 12.4% on MQA-3H and 10.9% on WTQ), comparable with state-of-the-art fine-tuned methods (67% on CWQ and 74.7% on WebQSP) and substantially boosting the vanilla LLMs (by 14.9% on CWQ). Our code will be available upon publication.