 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMIR: A Streamlined Platform for Personalized Agent Tuning in Domain Expertise
Paper and Code
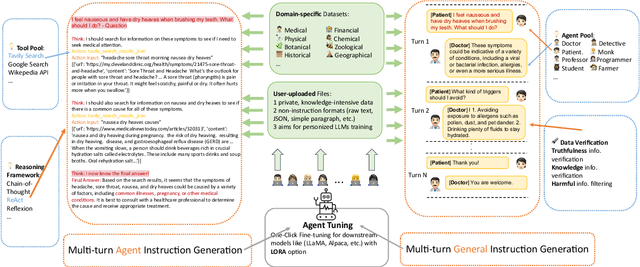
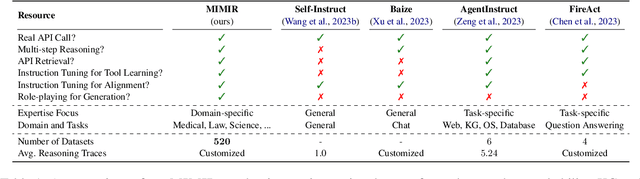
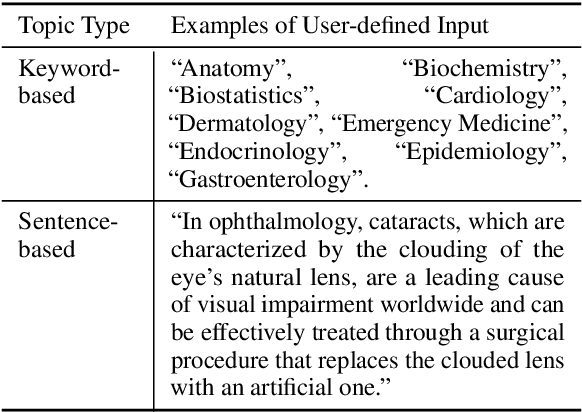

Recently, large language models (LLMs) have evolved into interactive agents, proficient in planning, tool use, and task execution across a wide variety of tasks. However, without specific agent tuning, open-source models like LLaMA currently struggle to match the efficiency of GPT- 4, particularly given the scarcity of agent-tuning datasets for fine-tuning. In response, we introduce \textsc{Mimir}: a streamlined platform offering a customizable pipeline that enables users to leverage both private knowledge and publicly available, legally compliant datasets at scale for \textbf{personalized agent tuning}. Additionally, \textsc{Mimir} supports the generation of general instruction-tuning datasets from the same input. This dual capability ensures that language agents developed through the platform possess both specific agent abilities and general competencies. \textsc{Mimir} integrates these features into a cohesive end-to-end platform, facilitating everything from the uploading of personalized files to one-click agent fine-tuning.