 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiDAn: A Coherence Optimization Approach for Backdoor Attack Detection and Mitigation in Deep Neural Networks
Paper and Code
Mar 26, 2022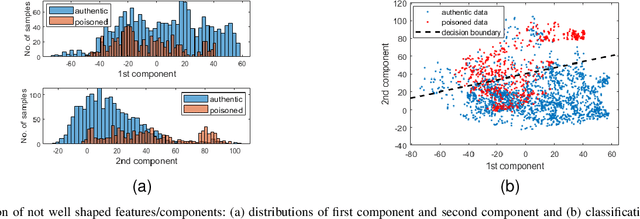
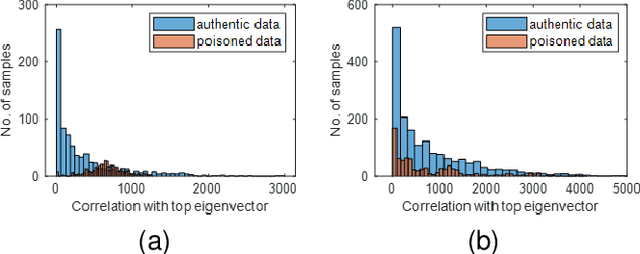
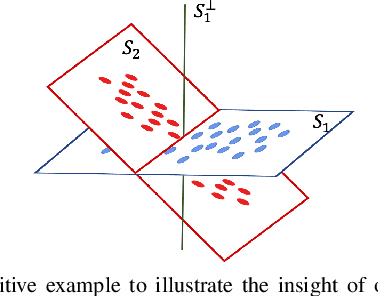
Backdoor attacks impose a new threat in Deep Neural Networks (DNNs), where a backdoor is inserted into the neural network by poisoning the training dataset, misclassifying inputs that contain the adversary trigger. The major challenge for defending against these attacks is that only the attacker knows the secret trigger and the target class. The problem is further exacerbated by the recent introduction of "Hidden Triggers", where the triggers are carefully fused into the input, bypassing detection by human inspection and causing backdoor identification through anomaly detection to fail. To defend against such imperceptible attacks, in this work we systematically analyze how representations, i.e., the set of neuron activations for a given DNN when using the training data as inputs, are affected by backdoor attacks. We propose PiDAn, an algorithm based on coherence optimization purifying the poisoned data. Our analysis shows that representations of poisoned data and authentic data in the target class are still embedded in different linear subspaces, which implies that they show different coherence with some latent spaces. Based on this observation, the proposed PiDAn algorithm learns a sample-wise weight vector to maximize the projected coherence of weighted samples, where we demonstrate that the learned weight vector has a natural "grouping effect" and is distinguishable between authentic data and poisoned data. This enables the systematic detection and mitigation of backdoor attacks. Based on our theoretical analysis and experimental results, we demonstrate the effectiveness of PiDAn in defending against backdoor attacks that use different settings of poisoned samples on GTSRB and ILSVRC2012 datasets. Our PiDAn algorithm can detect more than 90% infected classes and identify 95% poisoned samples.