 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRAPDOOR: Repurposing backdoors to detect dataset bias in machine learning-based genomic analysis
Paper and Code
Aug 14, 2021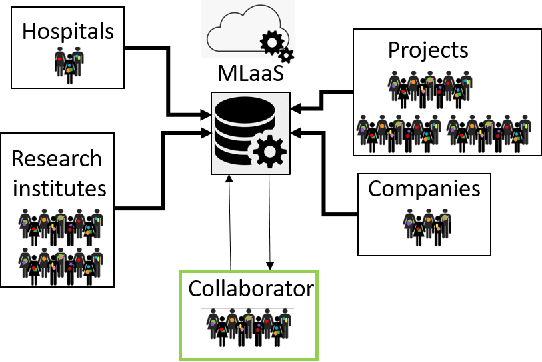

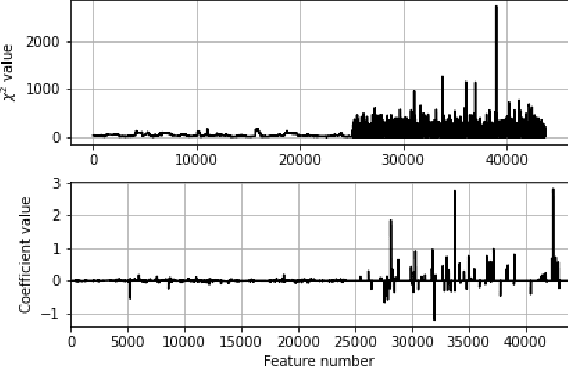
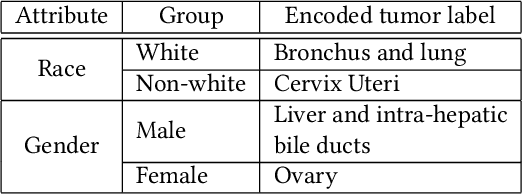
Machine Learning (ML) has achieved unprecedented performance in several applications including image, speech, text, and data analysis. Use of ML to understand underlying patterns in gene mutations (genomics) has far-reaching results, not only in overcoming diagnostic pitfalls, but also in designing treatments for life-threatening diseases like cancer. Success and sustainability of ML algorithms depends on the quality and diversity of data collected and used for training. Under-representation of groups (ethnic groups, gender groups, etc.) in such a dataset can lead to inaccurate predictions for certain groups, which can further exacerbate systemic discrimination issues. In this work, we propose TRAPDOOR, a methodology for identification of biased datasets by repurposing a technique that has been mostly proposed for nefarious purposes: Neural network backdoors. We consider a typical collaborative learning setting of the genomics supply chain, where data may come from hospitals, collaborative projects, or research institutes to a central cloud without awareness of bias against a sensitive group. In this context, we develop a methodology to leak potential bias information of the collective data without hampering the genuine performance using ML backdooring catered for genomic applications. Using a real-world cancer dataset, we analyze the dataset with the bias that already existed towards white individuals and also introduced biases in datasets artificially, and our experimental result show that TRAPDOOR can detect the presence of dataset bias with 100% accuracy, and furthermore can also extract the extent of bias by recovering the percentage with a small error.