 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMPot: Automated LLM-based Industrial Protocol and Physical Process Emulation for ICS Honeypots
May 09, 2024Industrial Control Systems (ICS) are extensively used in critical infrastructures ensuring efficient, reliable, and continuous operations. However, their increasing connectivity and addition of advanced features make them vulnerable to cyber threats, potentially leading to severe disruptions in essential services. In this context, honeypots play a vital role by acting as decoy targets within ICS networks, or on the Internet, helping to detect, log, analyze, and develop mitigations for ICS-specific cyber threats. Deploying ICS honeypots, however, is challenging due to the necessity of accurately replicating industrial protocols and device characteristics, a crucial requirement for effectively mimicking the unique operational behavior of different industrial systems. Moreover, this challenge is compounded by the significant manual effort required in also mimicking the control logic the PLC would execute, in order to capture attacker traffic aiming to disrupt critical infrastructure operations. In this paper, we propose LLMPot, a novel approach for designing honeypots in ICS networks harnessing the potency of Large Language Models (LLMs). LLMPot aims to automate and optimize the creation of realistic honeypots with vendor-agnostic configurations, and for any control logic, aiming to eliminate the manual effort and specialized knowledge traditionally required in this domain. We conducted extensive experiments focusing on a wide array of parameters, demonstrating that our LLM-based approach can effectively create honeypot devices implementing different industrial protocols and diverse control logic.
HowkGPT: Investigating the Detection of ChatGPT-generated University Student Homework through Context-Aware Perplexity Analysis
Jun 07, 2023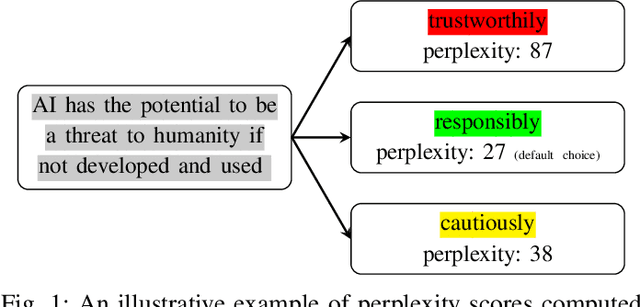
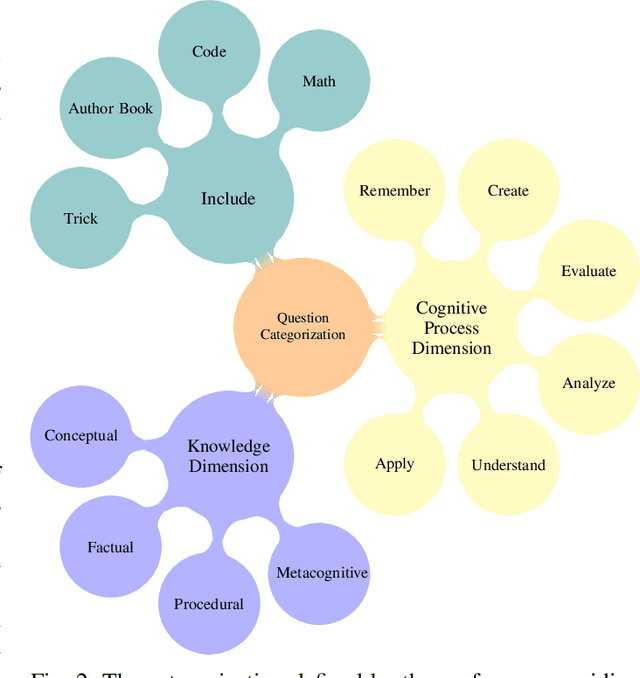
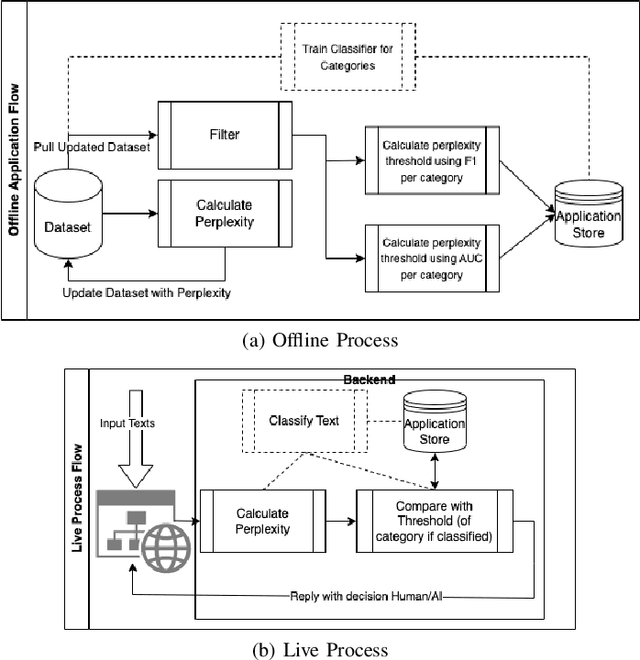
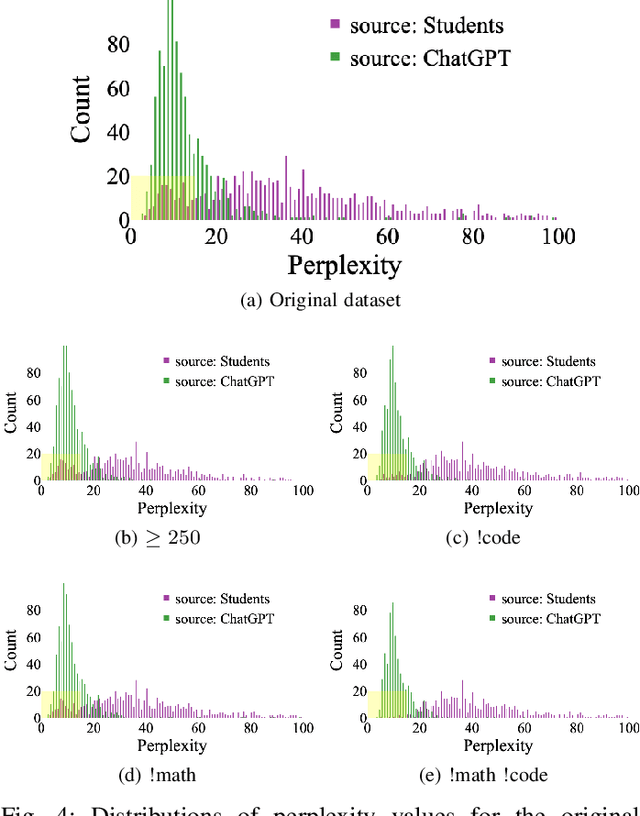
As the use of Large Language Models (LLMs) in text generation tasks proliferates, concerns arise over their potential to compromise academic integrity. The education sector currently tussles with distinguishing student-authored homework assignments from AI-generated ones. This paper addresses the challenge by introducing HowkGPT, designed to identify homework assignments generated by AI. HowkGPT is built upon a dataset of academic assignments and accompanying metadata [17] and employs a pretrained LLM to compute perplexity scores for student-authored and ChatGPT-generated responses. These scores then assist in establishing a threshold for discerning the origin of a submitted assignment. Given the specificity and contextual nature of academic work, HowkGPT further refines its analysis by defining category-specific thresholds derived from the metadata, enhancing the precision of the detection. This study emphasizes the critical need for effective strategies to uphold academic integrity amidst the growing influence of LLMs and provides an approach to ensuring fair and accurate grading in educational institutions.