 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Decentralized Certified Unlearning
Dec 09, 2025Machine unlearning (MU) seeks to remove the influence of specified data from a trained model in response to privacy requests or data poisoning. While certified unlearning has been analyzed in centralized and server-orchestrated federated settings (via guarantees analogous to differential privacy, DP), the decentralized setting -- where peers communicate without a coordinator remains underexplored. We study certified unlearning in decentralized networks with fixed topologies and propose RR-DU, a random-walk procedure that performs one projected gradient ascent step on the forget set at the unlearning client and a geometrically distributed number of projected descent steps on the retained data elsewhere, combined with subsampled Gaussian noise and projection onto a trust region around the original model. We provide (i) convergence guarantees in the convex case and stationarity guarantees in the nonconvex case, (ii) $(\varepsilon,δ)$ network-unlearning certificates on client views via subsampled Gaussian Rényi DP (RDP) with segment-level subsampling, and (iii) deletion-capacity bounds that scale with the forget-to-local data ratio and quantify the effect of decentralization (network mixing and randomized subsampling) on the privacy-utility trade-off. Empirically, on image benchmarks (MNIST, CIFAR-10), RR-DU matches a given $(\varepsilon,δ)$ while achieving higher test accuracy than decentralized DP baselines and reducing forget accuracy to random guessing ($\approx 10\%$).
ReVeil: Unconstrained Concealed Backdoor Attack on Deep Neural Networks using Machine Unlearning
Feb 17, 2025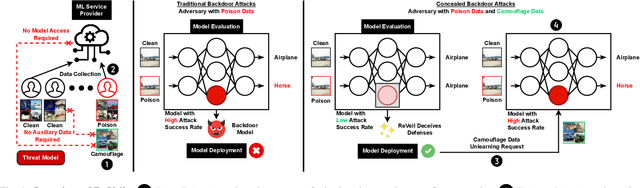

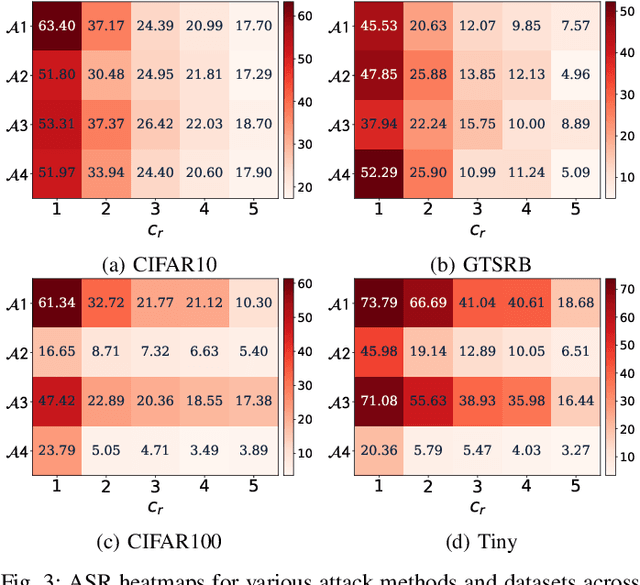
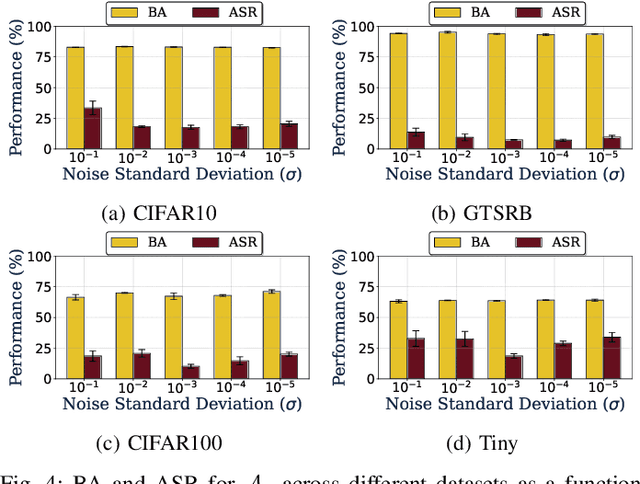
Backdoor attacks embed hidden functionalities in deep neural networks (DNN), triggering malicious behavior with specific inputs. Advanced defenses monitor anomalous DNN inferences to detect such attacks. However, concealed backdoors evade detection by maintaining a low pre-deployment attack success rate (ASR) and restoring high ASR post-deployment via machine unlearning. Existing concealed backdoors are often constrained by requiring white-box or black-box access or auxiliary data, limiting their practicality when such access or data is unavailable. This paper introduces ReVeil, a concealed backdoor attack targeting the data collection phase of the DNN training pipeline, requiring no model access or auxiliary data. ReVeil maintains low pre-deployment ASR across four datasets and four trigger patterns, successfully evades three popular backdoor detection methods, and restores high ASR post-deployment through machine unlearning.
LLMPot: Automated LLM-based Industrial Protocol and Physical Process Emulation for ICS Honeypots
May 09, 2024Industrial Control Systems (ICS) are extensively used in critical infrastructures ensuring efficient, reliable, and continuous operations. However, their increasing connectivity and addition of advanced features make them vulnerable to cyber threats, potentially leading to severe disruptions in essential services. In this context, honeypots play a vital role by acting as decoy targets within ICS networks, or on the Internet, helping to detect, log, analyze, and develop mitigations for ICS-specific cyber threats. Deploying ICS honeypots, however, is challenging due to the necessity of accurately replicating industrial protocols and device characteristics, a crucial requirement for effectively mimicking the unique operational behavior of different industrial systems. Moreover, this challenge is compounded by the significant manual effort required in also mimicking the control logic the PLC would execute, in order to capture attacker traffic aiming to disrupt critical infrastructure operations. In this paper, we propose LLMPot, a novel approach for designing honeypots in ICS networks harnessing the potency of Large Language Models (LLMs). LLMPot aims to automate and optimize the creation of realistic honeypots with vendor-agnostic configurations, and for any control logic, aiming to eliminate the manual effort and specialized knowledge traditionally required in this domain. We conducted extensive experiments focusing on a wide array of parameters, demonstrating that our LLM-based approach can effectively create honeypot devices implementing different industrial protocols and diverse control logic.
Get Rid Of Your Trail: Remotely Erasing Backdoors in Federated Learning
Apr 20, 2023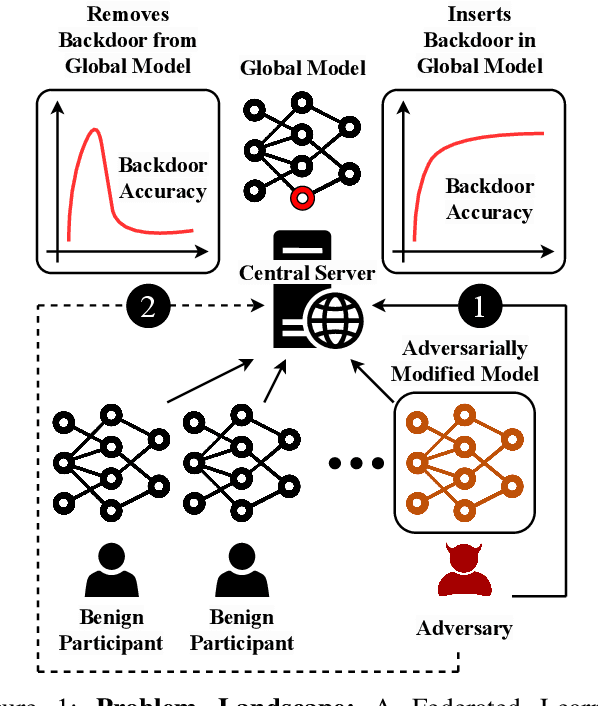
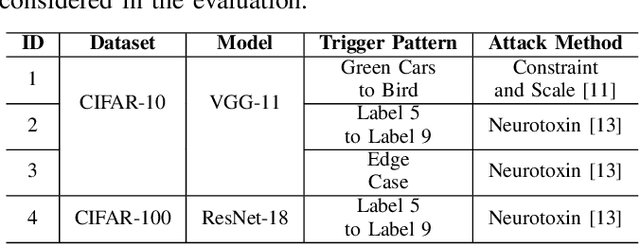
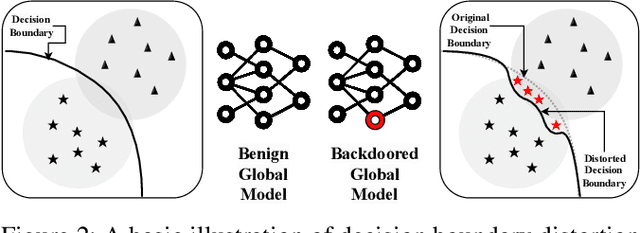
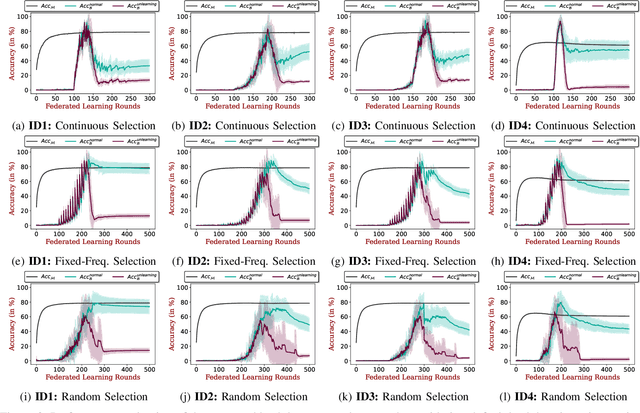
Federated Learning (FL) enables collaborative deep learning training across multiple participants without exposing sensitive personal data. However, the distributed nature of FL and the unvetted participants' data makes it vulnerable to backdoor attacks. In these attacks, adversaries inject malicious functionality into the centralized model during training, leading to intentional misclassifications for specific adversary-chosen inputs. While previous research has demonstrated successful injections of persistent backdoors in FL, the persistence also poses a challenge, as their existence in the centralized model can prompt the central aggregation server to take preventive measures to penalize the adversaries. Therefore, this paper proposes a methodology that enables adversaries to effectively remove backdoors from the centralized model upon achieving their objectives or upon suspicion of possible detection. The proposed approach extends the concept of machine unlearning and presents strategies to preserve the performance of the centralized model and simultaneously prevent over-unlearning of information unrelated to backdoor patterns, making the adversaries stealthy while removing backdoors. To the best of our knowledge, this is the first work that explores machine unlearning in FL to remove backdoors to the benefit of adversaries. Exhaustive evaluation considering image classification scenarios demonstrates the efficacy of the proposed method in efficient backdoor removal from the centralized model, injected by state-of-the-art attacks across multiple configurations.