 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReVeil: Unconstrained Concealed Backdoor Attack on Deep Neural Networks using Machine Unlearning
Feb 17, 2025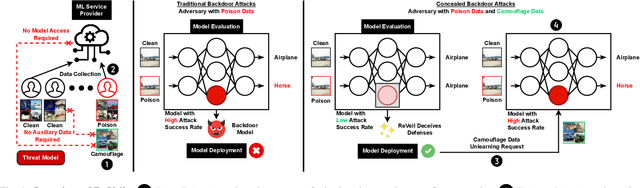

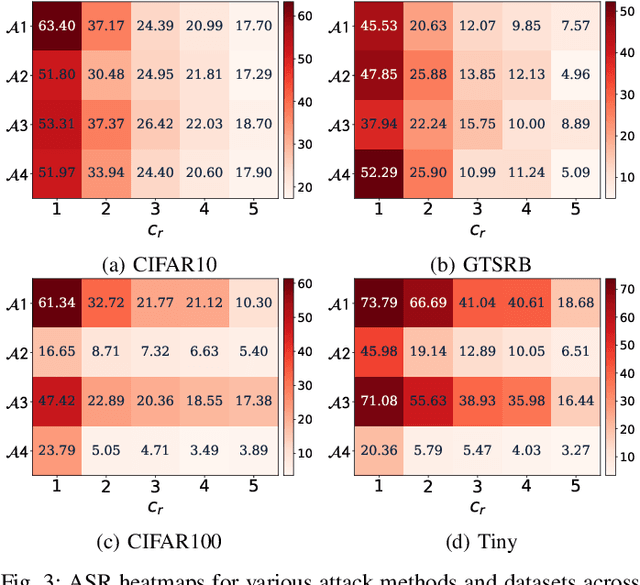
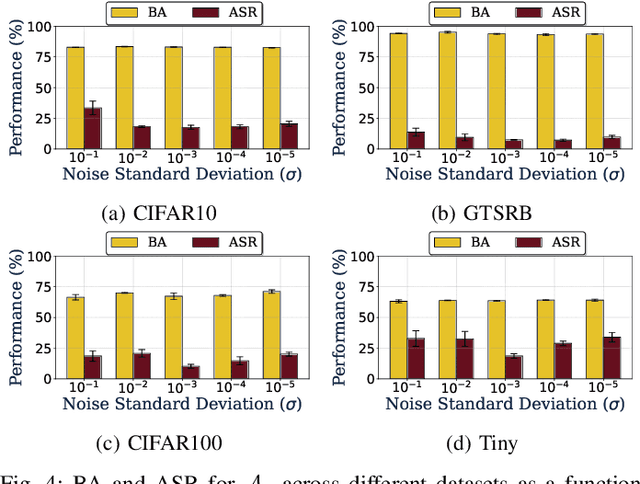
Backdoor attacks embed hidden functionalities in deep neural networks (DNN), triggering malicious behavior with specific inputs. Advanced defenses monitor anomalous DNN inferences to detect such attacks. However, concealed backdoors evade detection by maintaining a low pre-deployment attack success rate (ASR) and restoring high ASR post-deployment via machine unlearning. Existing concealed backdoors are often constrained by requiring white-box or black-box access or auxiliary data, limiting their practicality when such access or data is unavailable. This paper introduces ReVeil, a concealed backdoor attack targeting the data collection phase of the DNN training pipeline, requiring no model access or auxiliary data. ReVeil maintains low pre-deployment ASR across four datasets and four trigger patterns, successfully evades three popular backdoor detection methods, and restores high ASR post-deployment through machine unlearning.
LLMPot: Automated LLM-based Industrial Protocol and Physical Process Emulation for ICS Honeypots
May 09, 2024Industrial Control Systems (ICS) are extensively used in critical infrastructures ensuring efficient, reliable, and continuous operations. However, their increasing connectivity and addition of advanced features make them vulnerable to cyber threats, potentially leading to severe disruptions in essential services. In this context, honeypots play a vital role by acting as decoy targets within ICS networks, or on the Internet, helping to detect, log, analyze, and develop mitigations for ICS-specific cyber threats. Deploying ICS honeypots, however, is challenging due to the necessity of accurately replicating industrial protocols and device characteristics, a crucial requirement for effectively mimicking the unique operational behavior of different industrial systems. Moreover, this challenge is compounded by the significant manual effort required in also mimicking the control logic the PLC would execute, in order to capture attacker traffic aiming to disrupt critical infrastructure operations. In this paper, we propose LLMPot, a novel approach for designing honeypots in ICS networks harnessing the potency of Large Language Models (LLMs). LLMPot aims to automate and optimize the creation of realistic honeypots with vendor-agnostic configurations, and for any control logic, aiming to eliminate the manual effort and specialized knowledge traditionally required in this domain. We conducted extensive experiments focusing on a wide array of parameters, demonstrating that our LLM-based approach can effectively create honeypot devices implementing different industrial protocols and diverse control logic.
Stealing the Invisible: Unveiling Pre-Trained CNN Models through Adversarial Examples and Timing Side-Channels
Feb 19, 2024Machine learning, with its myriad applications, has become an integral component of numerous technological systems. A common practice in this domain is the use of transfer learning, where a pre-trained model's architecture, readily available to the public, is fine-tuned to suit specific tasks. As Machine Learning as a Service (MLaaS) platforms increasingly use pre-trained models in their backends, it's crucial to safeguard these architectures and understand their vulnerabilities. In this work, we present an approach based on the observation that the classification patterns of adversarial images can be used as a means to steal the models. Furthermore, the adversarial image classifications in conjunction with timing side channels can lead to a model stealing method. Our approach, designed for typical user-level access in remote MLaaS environments exploits varying misclassifications of adversarial images across different models to fingerprint several renowned Convolutional Neural Network (CNN) and Vision Transformer (ViT) architectures. We utilize the profiling of remote model inference times to reduce the necessary adversarial images, subsequently decreasing the number of queries required. We have presented our results over 27 pre-trained models of different CNN and ViT architectures using CIFAR-10 dataset and demonstrate a high accuracy of 88.8% while keeping the query budget under 20.
HowkGPT: Investigating the Detection of ChatGPT-generated University Student Homework through Context-Aware Perplexity Analysis
Jun 07, 2023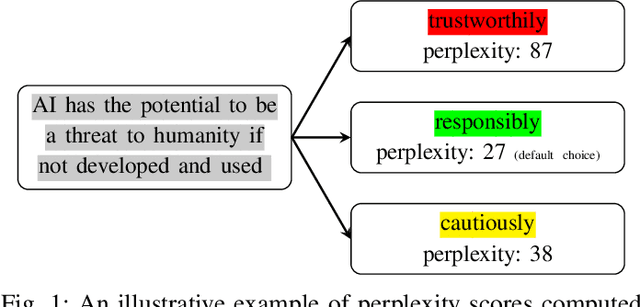
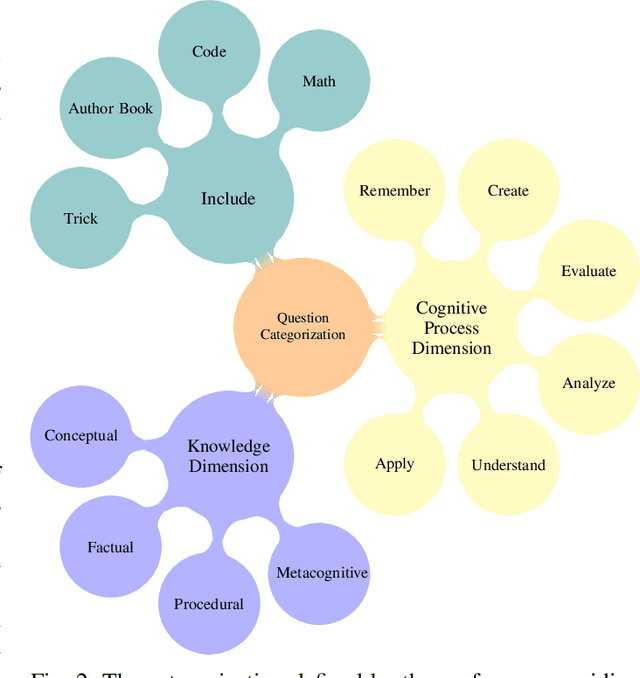
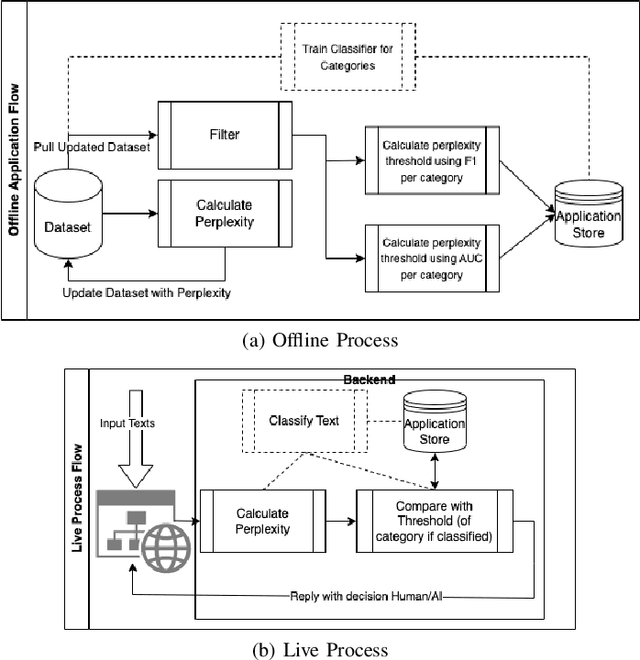
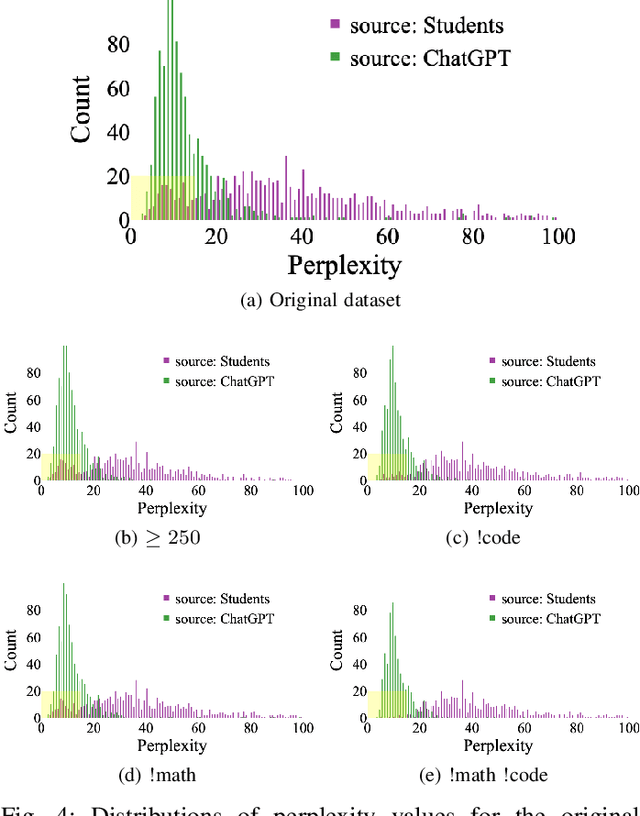
As the use of Large Language Models (LLMs) in text generation tasks proliferates, concerns arise over their potential to compromise academic integrity. The education sector currently tussles with distinguishing student-authored homework assignments from AI-generated ones. This paper addresses the challenge by introducing HowkGPT, designed to identify homework assignments generated by AI. HowkGPT is built upon a dataset of academic assignments and accompanying metadata [17] and employs a pretrained LLM to compute perplexity scores for student-authored and ChatGPT-generated responses. These scores then assist in establishing a threshold for discerning the origin of a submitted assignment. Given the specificity and contextual nature of academic work, HowkGPT further refines its analysis by defining category-specific thresholds derived from the metadata, enhancing the precision of the detection. This study emphasizes the critical need for effective strategies to uphold academic integrity amidst the growing influence of LLMs and provides an approach to ensuring fair and accurate grading in educational institutions.
Get Rid Of Your Trail: Remotely Erasing Backdoors in Federated Learning
Apr 20, 2023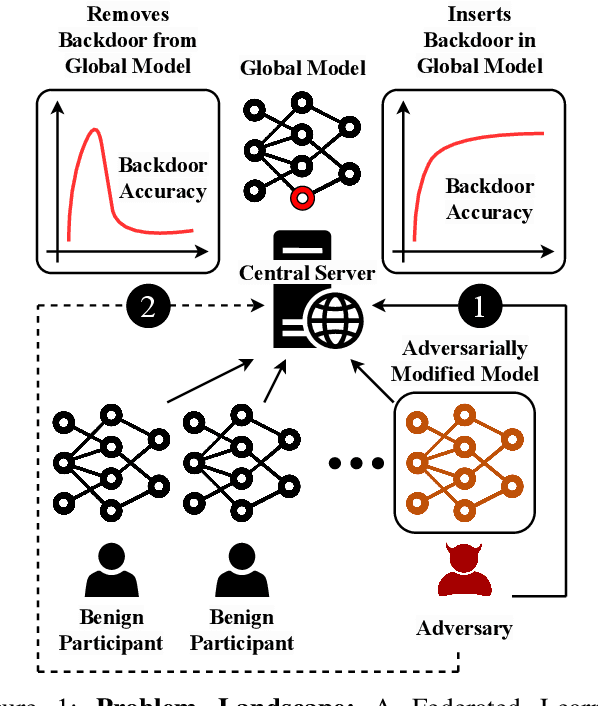
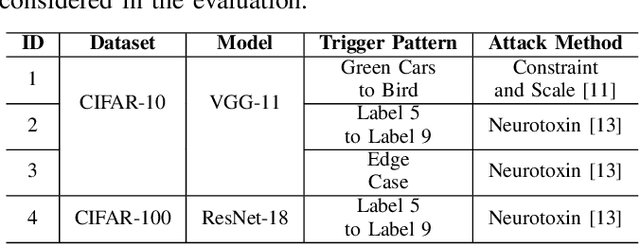
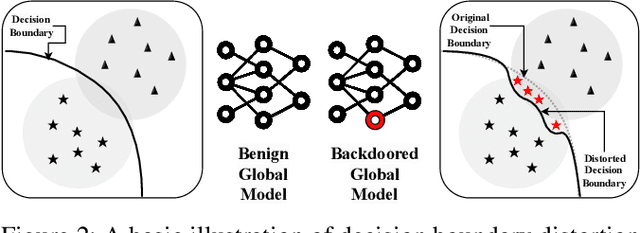
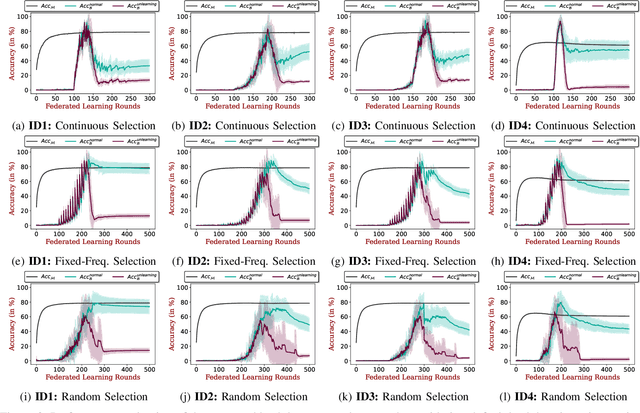
Federated Learning (FL) enables collaborative deep learning training across multiple participants without exposing sensitive personal data. However, the distributed nature of FL and the unvetted participants' data makes it vulnerable to backdoor attacks. In these attacks, adversaries inject malicious functionality into the centralized model during training, leading to intentional misclassifications for specific adversary-chosen inputs. While previous research has demonstrated successful injections of persistent backdoors in FL, the persistence also poses a challenge, as their existence in the centralized model can prompt the central aggregation server to take preventive measures to penalize the adversaries. Therefore, this paper proposes a methodology that enables adversaries to effectively remove backdoors from the centralized model upon achieving their objectives or upon suspicion of possible detection. The proposed approach extends the concept of machine unlearning and presents strategies to preserve the performance of the centralized model and simultaneously prevent over-unlearning of information unrelated to backdoor patterns, making the adversaries stealthy while removing backdoors. To the best of our knowledge, this is the first work that explores machine unlearning in FL to remove backdoors to the benefit of adversaries. Exhaustive evaluation considering image classification scenarios demonstrates the efficacy of the proposed method in efficient backdoor removal from the centralized model, injected by state-of-the-art attacks across multiple configurations.
Resisting Adversarial Attacks in Deep Neural Networks using Diverse Decision Boundaries
Aug 18, 2022


The security of deep learning (DL) systems is an extremely important field of study as they are being deployed in several applications due to their ever-improving performance to solve challenging tasks. Despite overwhelming promises, the deep learning systems are vulnerable to crafted adversarial examples, which may be imperceptible to the human eye, but can lead the model to misclassify. Protections against adversarial perturbations on ensemble-based techniques have either been shown to be vulnerable to stronger adversaries or shown to lack an end-to-end evaluation. In this paper, we attempt to develop a new ensemble-based solution that constructs defender models with diverse decision boundaries with respect to the original model. The ensemble of classifiers constructed by (1) transformation of the input by a method called Split-and-Shuffle, and (2) restricting the significant features by a method called Contrast-Significant-Features are shown to result in diverse gradients with respect to adversarial attacks, which reduces the chance of transferring adversarial examples from the original to the defender model targeting the same class. We present extensive experimentations using standard image classification datasets, namely MNIST, CIFAR-10 and CIFAR-100 against state-of-the-art adversarial attacks to demonstrate the robustness of the proposed ensemble-based defense. We also evaluate the robustness in the presence of a stronger adversary targeting all the models within the ensemble simultaneously. Results for the overall false positives and false negatives have been furnished to estimate the overall performance of the proposed methodology.
On the Evaluation of User Privacy in Deep Neural Networks using Timing Side Channel
Aug 03, 2022
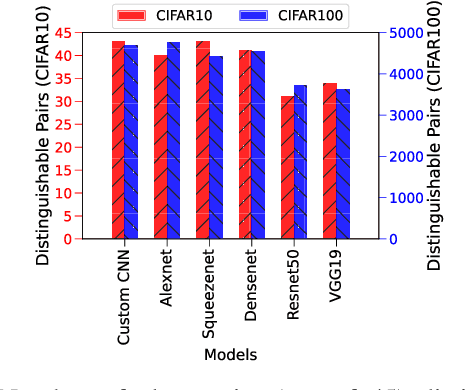
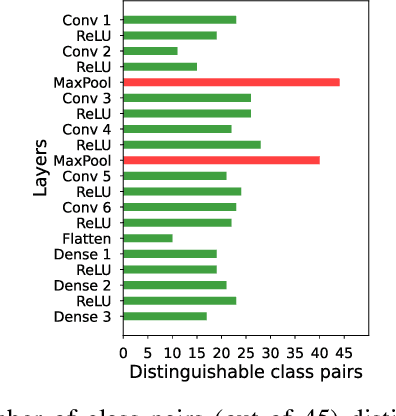

Recent Deep Learning (DL) advancements in solving complex real-world tasks have led to its widespread adoption in practical applications. However, this opportunity comes with significant underlying risks, as many of these models rely on privacy-sensitive data for training in a variety of applications, making them an overly-exposed threat surface for privacy violations. Furthermore, the widespread use of cloud-based Machine-Learning-as-a-Service (MLaaS) for its robust infrastructure support has broadened the threat surface to include a variety of remote side-channel attacks. In this paper, we first identify and report a novel data-dependent timing side-channel leakage (termed Class Leakage) in DL implementations originating from non-constant time branching operation in a widely used DL framework PyTorch. We further demonstrate a practical inference-time attack where an adversary with user privilege and hard-label black-box access to an MLaaS can exploit Class Leakage to compromise the privacy of MLaaS users. DL models are vulnerable to Membership Inference Attack (MIA), where an adversary's objective is to deduce whether any particular data has been used while training the model. In this paper, as a separate case study, we demonstrate that a DL model secured with differential privacy (a popular countermeasure against MIA) is still vulnerable to MIA against an adversary exploiting Class Leakage. We develop an easy-to-implement countermeasure by making a constant-time branching operation that alleviates the Class Leakage and also aids in mitigating MIA. We have chosen two standard benchmarking image classification datasets, CIFAR-10 and CIFAR-100 to train five state-of-the-art pre-trained DL models, over two different computing environments having Intel Xeon and Intel i7 processors to validate our approach.
PARL: Enhancing Diversity of Ensemble Networks to Resist Adversarial Attacks via Pairwise Adversarially Robust Loss Function
Dec 09, 2021
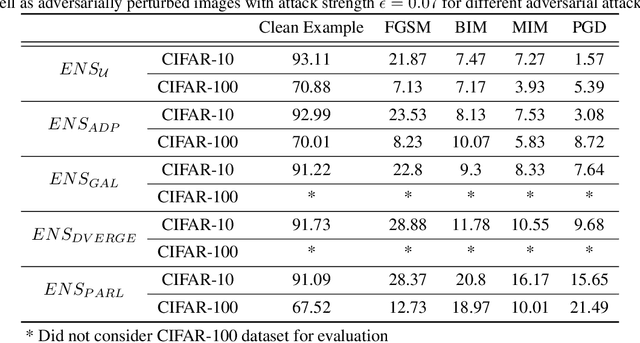
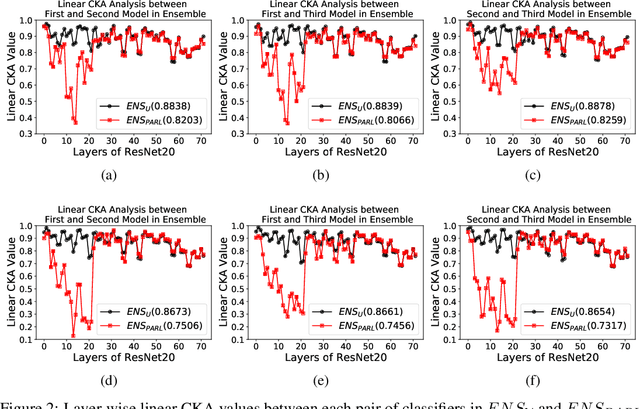

The security of Deep Learning classifiers is a critical field of study because of the existence of adversarial attacks. Such attacks usually rely on the principle of transferability, where an adversarial example crafted on a surrogate classifier tends to mislead the target classifier trained on the same dataset even if both classifiers have quite different architecture. Ensemble methods against adversarial attacks demonstrate that an adversarial example is less likely to mislead multiple classifiers in an ensemble having diverse decision boundaries. However, recent ensemble methods have either been shown to be vulnerable to stronger adversaries or shown to lack an end-to-end evaluation. This paper attempts to develop a new ensemble methodology that constructs multiple diverse classifiers using a Pairwise Adversarially Robust Loss (PARL) function during the training procedure. PARL utilizes gradients of each layer with respect to input in every classifier within the ensemble simultaneously. The proposed training procedure enables PARL to achieve higher robustness against black-box transfer attacks compared to previous ensemble methods without adversely affecting the accuracy of clean examples. We also evaluate the robustness in the presence of white-box attacks, where adversarial examples are crafted using parameters of the target classifier. We present extensive experiments using standard image classification datasets like CIFAR-10 and CIFAR-100 trained using standard ResNet20 classifier against state-of-the-art adversarial attacks to demonstrate the robustness of the proposed ensemble methodology.
Deep-Lock: Secure Authorization for Deep Neural Networks
Aug 13, 2020
Trained Deep Neural Network (DNN) models are considered valuable Intellectual Properties (IP) in several business models. Prevention of IP theft and unauthorized usage of such DNN models has been raised as of significant concern by industry. In this paper, we address the problem of preventing unauthorized usage of DNN models by proposing a generic and lightweight key-based model-locking scheme, which ensures that a locked model functions correctly only upon applying the correct secret key. The proposed scheme, known as Deep-Lock, utilizes S-Boxes with good security properties to encrypt each parameter of a trained DNN model with secret keys generated from a master key via a key scheduling algorithm. The resulting dense network of encrypted weights is found robust against model fine-tuning attacks. Finally, Deep-Lock does not require any intervention in the structure and training of the DNN models, making it applicable for all existing software and hardware implementations of DNN.
Enhancing Fault Tolerance of Neural Networks for Security-Critical Applications
Feb 05, 2019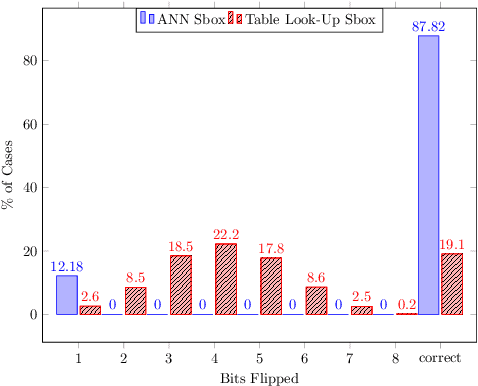

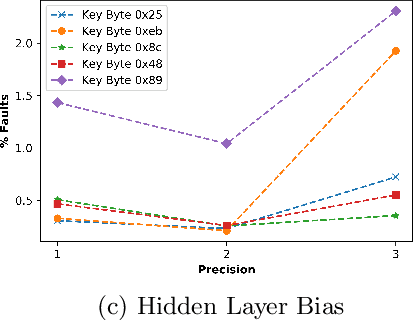
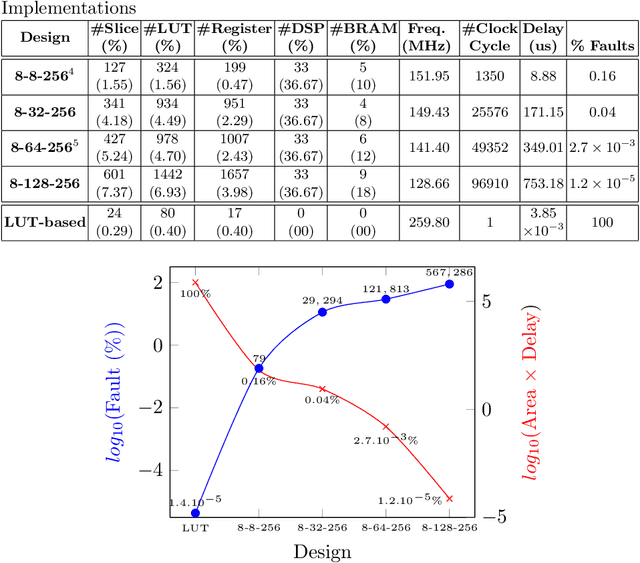
Neural Networks (NN) have recently emerged as backbone of several sensitive applications like automobile, medical image, security, etc. NNs inherently offer Partial Fault Tolerance (PFT) in their architecture; however, the biased PFT of NNs can lead to severe consequences in applications like cryptography and security critical scenarios. In this paper, we propose a revised implementation which enhances the PFT property of NN significantly with detailed mathematical analysis. We evaluated the performance of revised NN considering both software and FPGA implementation for a cryptographic primitive like AES SBox. The results show that the PFT of NNs can be significantly increased with the proposed methodology.