 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Constant-Time Implementation Methodology for Activation Functions on Microcontrollers
May 21, 2026Embedded neural-network inference can leak information through timing side channels, including leakage caused by the evaluation of activation functions. This work proposes a constant-time implementation methodology for activation functions on embedded microcontrollers and validates it on ReLU, sigmoid, tanh, GELU, and Swish on an ARM Cortex-M4 platform. The proposed methodology combines branchless selection, fixed-cost Padé-based approximation, dummy arithmetic where needed, and cycle alignment to obtain timing-regular activation-function implementations. As motivation, we also evaluate a desynchronization-based countermeasure and show that it remains vulnerable to a template-based timing attack. Experimental results show that the resulting protected implementations achieve identical cycle counts for all tested inputs, including (88) cycles in the three-function setting and (108) cycles in the five-function setting. At the same time, the numerical-error analysis indicates that the approximated nonlinear functions retain high accuracy. These results suggest that the proposed methodology provides a practical basis for constructing side-channel-resistant activation functions in embedded inference.
Characterizing the Fault Response of the Intel Neural Compute Stick 2 Under Single-Pulse Electromagnetic Fault Injection
May 21, 2026Vision processing units and other commercial neural-network inference accelerators are increasingly deployed in safety-relevant edge applications, but their fault response under transient hardware disturbances remains poorly characterized in the open literature. For the Intel Movidius Myriad X, packaged as the Intel Neural Compute Stick 2 (NCS2), only a single feasibility study has been published. We report a systematic single-pulse electromagnetic fault injection (EMFI) campaign on the NCS2 running three ImageNet-trained convolutional neural networks (ResNet-18, ResNet-50, VGG-11) on the OpenVINO runtime. Across 1,536 spot-test trials at characterized hotspots and approximately 16,000 parameter-search trials, single pulses produce four reproducible outcome classes: no measured accuracy change, minor silent data corruption, major persistent degradation that survives across subsequent inferences until model reload, and device hangs requiring USB power-cycling; these outcomes are respectively interpreted as no-effect, SDC with possible SET-like or small persistent-state mechanisms, SEU-like persistent corruption, and SEFI-like loss of functionality. Two findings are central. First, the major-degradation class can be induced at 18-31% of trials at characterized hotspots, with post-collapse top-1 accuracy below five percent and persistence across all subsequent inferences until explicit model reload - a regime that no inference-API-level mechanism detects. Second, this regime is also inducible by pulses delivered to an idle device with the model already loaded, demonstrating that load-time integrity checks alone are insufficient. We discuss mitigation strategies graded by class, focusing on mechanisms implementable at the application level without modification to the device firmware or the OpenVINO runtime.
Beyond TVLA: Anderson-Darling Leakage Assessment for Neural Network Side-Channel Leakage Detection
Mar 19, 2026Test Vector Leakage Assessment (TVLA) based on Welch's $t$-test has become a standard tool for detecting side-channel leakage. However, its mean-based nature can limit sensitivity when leakage manifests primarily through higher-order distributional differences. As our experiments show, this property becomes especially crucial when it comes to evaluating neural network implementations. In this work, we propose Anderson--Darling Leakage Assessment (ADLA), a leakage detection framework that applies the two-sample Anderson--Darling test for leakage detection. Unlike TVLA, ADLA tests equality of the full cumulative distribution functions and does not rely on a purely mean-shift model. We evaluate ADLA on a multilayer perceptron (MLP) trained on MNIST and implemented on a ChipWhisperer-Husky evaluation platform. We consider protected implementations employing shuffling and random jitter countermeasures. Our results show that ADLA can provide improved leakage-detection sensitivity in protected implementations for a low number of traces compared to TVLA.
The Weight of a Bit: EMFI Sensitivity Analysis of Embedded Deep Learning Models
Feb 18, 2026Fault injection attacks on embedded neural network models have been shown as a potent threat. Numerous works studied resilience of models from various points of view. As of now, there is no comprehensive study that would evaluate the influence of number representations used for model parameters against electromagnetic fault injection (EMFI) attacks. In this paper, we investigate how four different number representations influence the success of an EMFI attack on embedded neural network models. We chose two common floating-point representations (32-bit, and 16-bit), and two integer representations (8-bit, and 4-bit). We deployed four common image classifiers, ResNet-18, ResNet-34, ResNet-50, and VGG-11, on an embedded memory chip, and utilized a low-cost EMFI platform to trigger faults. Our results show that while floating-point representations exhibit almost a complete degradation in accuracy (Top-1 and Top-5) after a single fault injection, integer representations offer better resistance overall. Especially, when considering the the 8-bit representation on a relatively large network (VGG-11), the Top-1 accuracies stay at around 70% and the Top-5 at around 90%.
Make Shuffling Great Again: A Side-Channel Resistant Fisher-Yates Algorithm for Protecting Neural Networks
Jan 01, 2025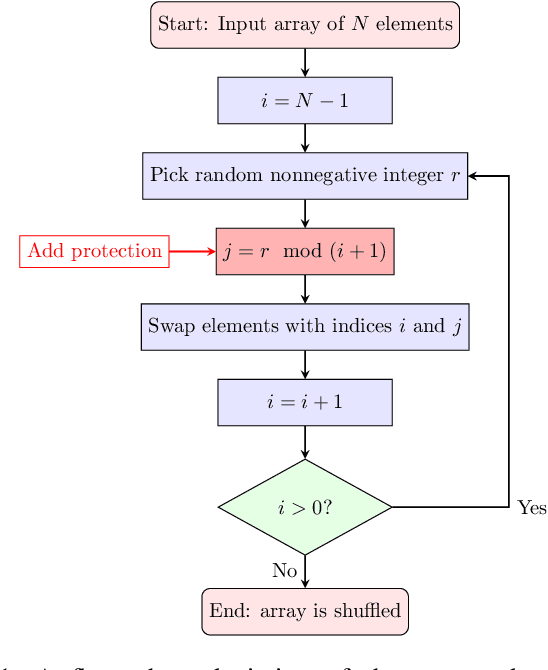
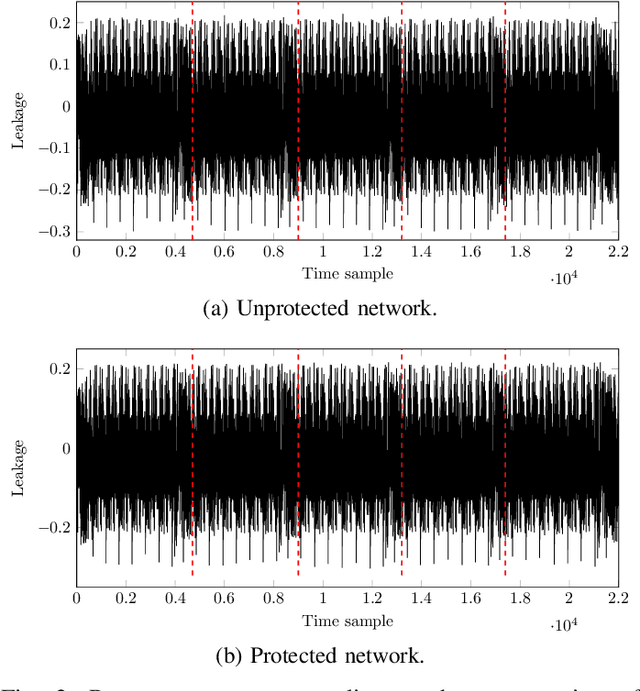
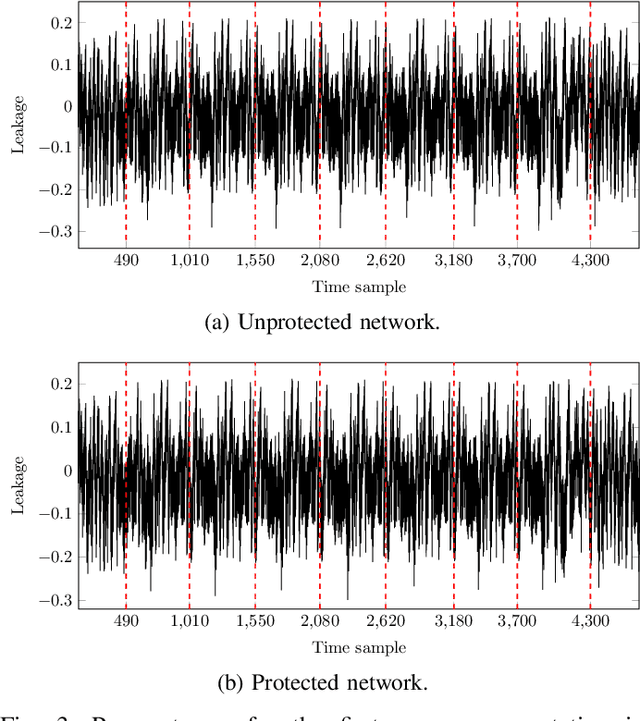
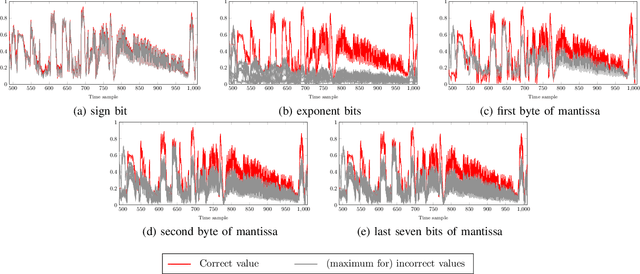
Neural network models implemented in embedded devices have been shown to be susceptible to side-channel attacks (SCAs), allowing recovery of proprietary model parameters, such as weights and biases. There are already available countermeasure methods currently used for protecting cryptographic implementations that can be tailored to protect embedded neural network models. Shuffling, a hiding-based countermeasure that randomly shuffles the order of computations, was shown to be vulnerable to SCA when the Fisher-Yates algorithm is used. In this paper, we propose a design of an SCA-secure version of the Fisher-Yates algorithm. By integrating the masking technique for modular reduction and Blakely's method for modular multiplication, we effectively remove the vulnerability in the division operation that led to side-channel leakage in the original version of the algorithm. We experimentally evaluate that the countermeasure is effective against SCA by implementing a correlation power analysis attack on an embedded neural network model implemented on ARM Cortex-M4. Compared to the original proposal, the memory overhead is $2\times$ the biggest layer of the network, while the time overhead varies from $4\%$ to $0.49\%$ for a layer with $100$ and $1000$ neurons, respectively.
Side-Channel Analysis of OpenVINO-based Neural Network Models
Jul 23, 2024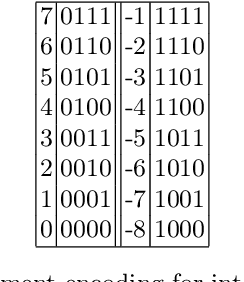

Embedded devices with neural network accelerators offer great versatility for their users, reducing the need to use cloud-based services. At the same time, they introduce new security challenges in the area of hardware attacks, the most prominent being side-channel analysis (SCA). It was shown that SCA can recover model parameters with a high accuracy, posing a threat to entities that wish to keep their models confidential. In this paper, we explore the susceptibility of quantized models implemented in OpenVINO, an embedded framework for deploying neural networks on embedded and Edge devices. We show that it is possible to recover model parameters with high precision, allowing the recovered model to perform very close to the original one. Our experiments on GoogleNet v1 show only a 1% difference in the Top 1 and a 0.64% difference in the Top 5 accuracies.
RMF: A Risk Measurement Framework for Machine Learning Models
Jun 15, 2024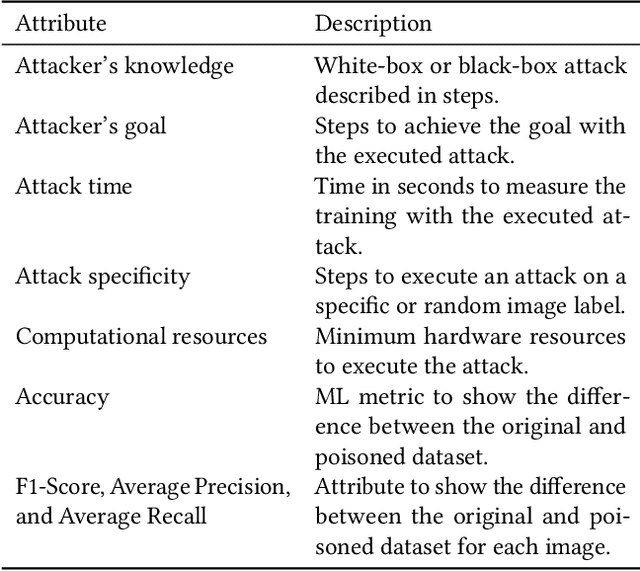
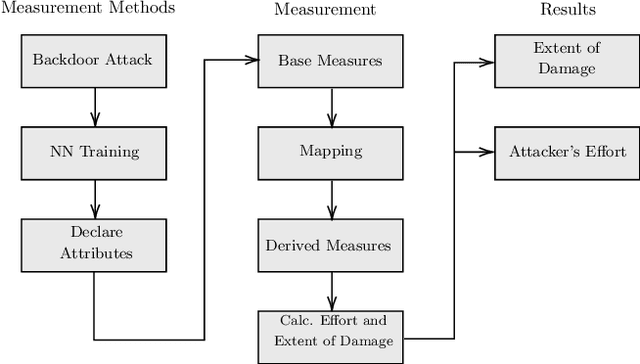

Machine learning (ML) models are used in many safety- and security-critical applications nowadays. It is therefore important to measure the security of a system that uses ML as a component. This paper focuses on the field of ML, particularly the security of autonomous vehicles. For this purpose, a technical framework will be described, implemented, and evaluated in a case study. Based on ISO/IEC 27004:2016, risk indicators are utilized to measure and evaluate the extent of damage and the effort required by an attacker. It is not possible, however, to determine a single risk value that represents the attacker's effort. Therefore, four different values must be interpreted individually.
DeepNcode: Encoding-Based Protection against Bit-Flip Attacks on Neural Networks
May 22, 2024Fault injection attacks are a potent threat against embedded implementations of neural network models. Several attack vectors have been proposed, such as misclassification, model extraction, and trojan/backdoor planting. Most of these attacks work by flipping bits in the memory where quantized model parameters are stored. In this paper, we introduce an encoding-based protection method against bit-flip attacks on neural networks, titled DeepNcode. We experimentally evaluate our proposal with several publicly available models and datasets, by using state-of-the-art bit-flip attacks: BFA, T-BFA, and TA-LBF. Our results show an increase in protection margin of up to $7.6\times$ for $4-$bit and $12.4\times$ for $8-$bit quantized networks. Memory overheads start at $50\%$ of the original network size, while the time overheads are negligible. Moreover, DeepNcode does not require retraining and does not change the original accuracy of the model.
A Desynchronization-Based Countermeasure Against Side-Channel Analysis of Neural Networks
Mar 25, 2023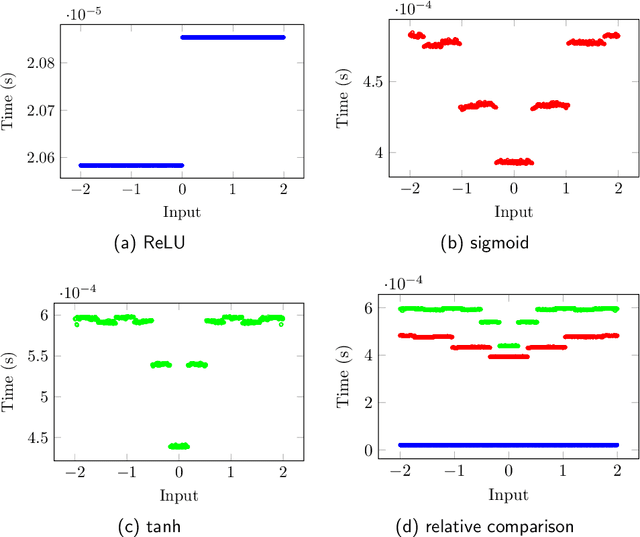
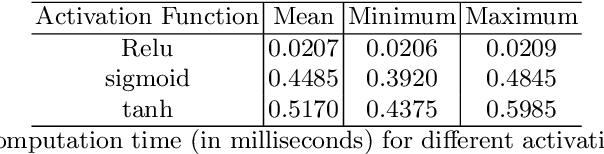
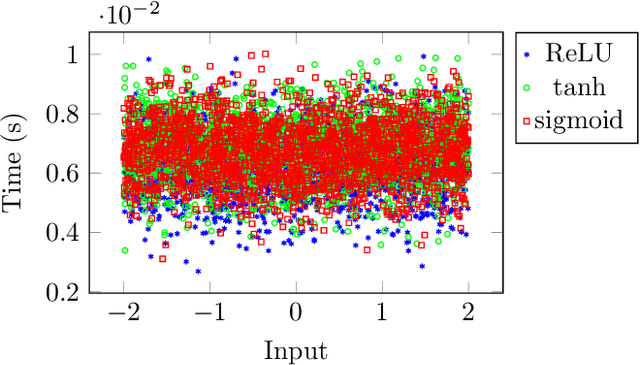
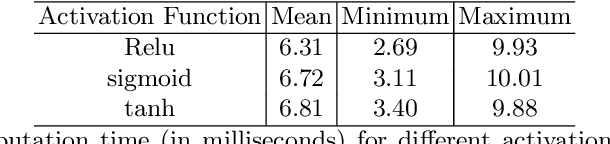
Model extraction attacks have been widely applied, which can normally be used to recover confidential parameters of neural networks for multiple layers. Recently, side-channel analysis of neural networks allows parameter extraction even for networks with several multiple deep layers with high effectiveness. It is therefore of interest to implement a certain level of protection against these attacks. In this paper, we propose a desynchronization-based countermeasure that makes the timing analysis of activation functions harder. We analyze the timing properties of several activation functions and design the desynchronization in a way that the dependency on the input and the activation type is hidden. We experimentally verify the effectiveness of the countermeasure on a 32-bit ARM Cortex-M4 microcontroller and employ a t-test to show the side-channel information leakage. The overhead ultimately depends on the number of neurons in the fully-connected layer, for example, in the case of 4096 neurons in VGG-19, the overheads are between 2.8% and 11%.
FooBaR: Fault Fooling Backdoor Attack on Neural Network Training
Sep 23, 2021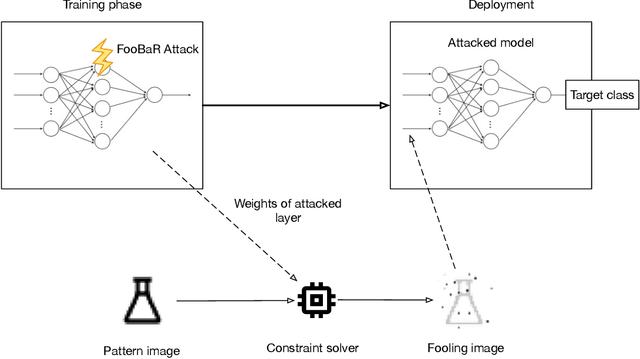
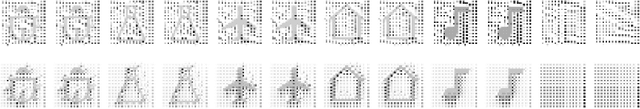
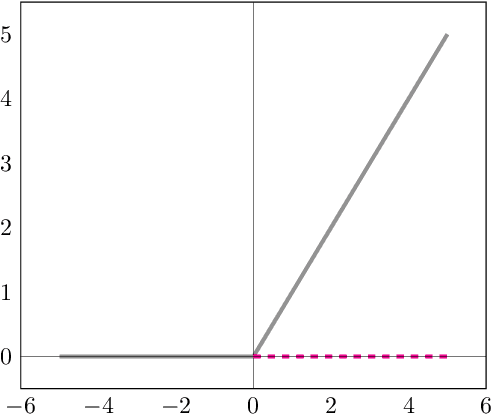
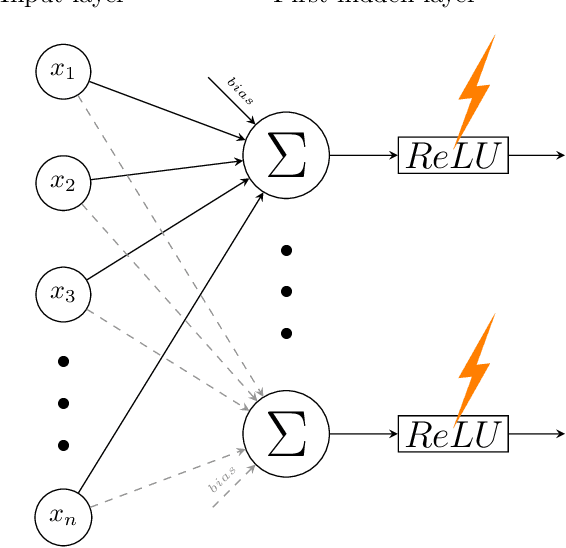
Neural network implementations are known to be vulnerable to physical attack vectors such as fault injection attacks. As of now, these attacks were only utilized during the inference phase with the intention to cause a misclassification. In this work, we explore a novel attack paradigm by injecting faults during the training phase of a neural network in a way that the resulting network can be attacked during deployment without the necessity of further faulting. In particular, we discuss attacks against ReLU activation functions that make it possible to generate a family of malicious inputs, which are called fooling inputs, to be used at inference time to induce controlled misclassifications. Such malicious inputs are obtained by mathematically solving a system of linear equations that would cause a particular behaviour on the attacked activation functions, similar to the one induced in training through faulting. We call such attacks fooling backdoors as the fault attacks at the training phase inject backdoors into the network that allow an attacker to produce fooling inputs. We evaluate our approach against multi-layer perceptron networks and convolutional networks on a popular image classification task obtaining high attack success rates (from 60% to 100%) and high classification confidence when as little as 25 neurons are attacked while preserving high accuracy on the originally intended classification task.