 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResisting Adversarial Attacks in Deep Neural Networks using Diverse Decision Boundaries
Aug 18, 2022
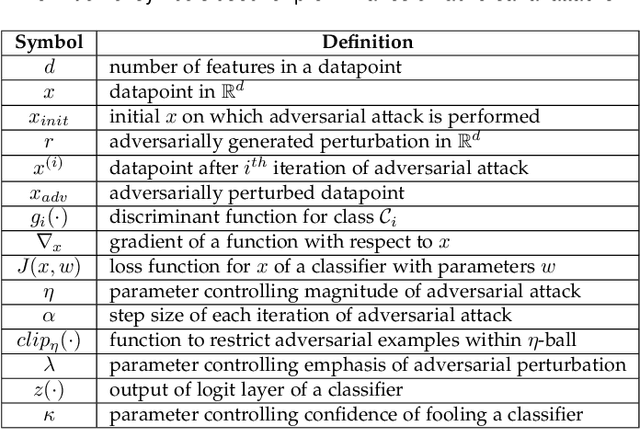


The security of deep learning (DL) systems is an extremely important field of study as they are being deployed in several applications due to their ever-improving performance to solve challenging tasks. Despite overwhelming promises, the deep learning systems are vulnerable to crafted adversarial examples, which may be imperceptible to the human eye, but can lead the model to misclassify. Protections against adversarial perturbations on ensemble-based techniques have either been shown to be vulnerable to stronger adversaries or shown to lack an end-to-end evaluation. In this paper, we attempt to develop a new ensemble-based solution that constructs defender models with diverse decision boundaries with respect to the original model. The ensemble of classifiers constructed by (1) transformation of the input by a method called Split-and-Shuffle, and (2) restricting the significant features by a method called Contrast-Significant-Features are shown to result in diverse gradients with respect to adversarial attacks, which reduces the chance of transferring adversarial examples from the original to the defender model targeting the same class. We present extensive experimentations using standard image classification datasets, namely MNIST, CIFAR-10 and CIFAR-100 against state-of-the-art adversarial attacks to demonstrate the robustness of the proposed ensemble-based defense. We also evaluate the robustness in the presence of a stronger adversary targeting all the models within the ensemble simultaneously. Results for the overall false positives and false negatives have been furnished to estimate the overall performance of the proposed methodology.
PARL: Enhancing Diversity of Ensemble Networks to Resist Adversarial Attacks via Pairwise Adversarially Robust Loss Function
Dec 09, 2021
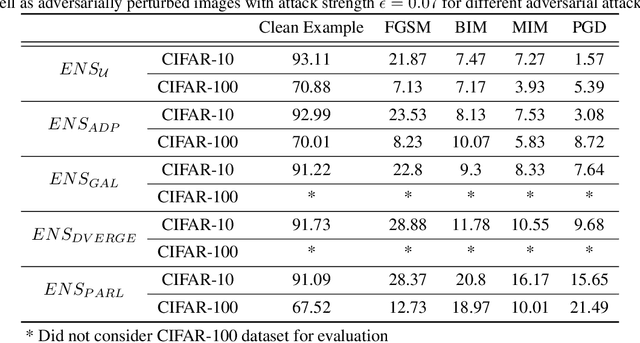
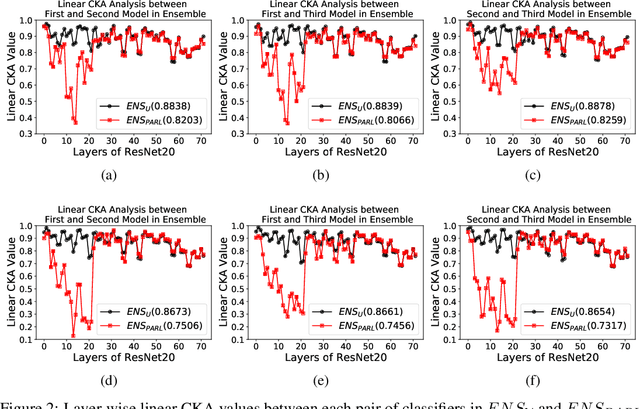

The security of Deep Learning classifiers is a critical field of study because of the existence of adversarial attacks. Such attacks usually rely on the principle of transferability, where an adversarial example crafted on a surrogate classifier tends to mislead the target classifier trained on the same dataset even if both classifiers have quite different architecture. Ensemble methods against adversarial attacks demonstrate that an adversarial example is less likely to mislead multiple classifiers in an ensemble having diverse decision boundaries. However, recent ensemble methods have either been shown to be vulnerable to stronger adversaries or shown to lack an end-to-end evaluation. This paper attempts to develop a new ensemble methodology that constructs multiple diverse classifiers using a Pairwise Adversarially Robust Loss (PARL) function during the training procedure. PARL utilizes gradients of each layer with respect to input in every classifier within the ensemble simultaneously. The proposed training procedure enables PARL to achieve higher robustness against black-box transfer attacks compared to previous ensemble methods without adversely affecting the accuracy of clean examples. We also evaluate the robustness in the presence of white-box attacks, where adversarial examples are crafted using parameters of the target classifier. We present extensive experiments using standard image classification datasets like CIFAR-10 and CIFAR-100 trained using standard ResNet20 classifier against state-of-the-art adversarial attacks to demonstrate the robustness of the proposed ensemble methodology.