 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Model-Aided Hierarchical Deep Reinforcement Learning for Blockage-Aware Link in RIS-Assisted Networks
Feb 09, 2026Reconfigurable intelligent surface (RIS) technology has the potential to significantly enhance the spectral efficiency (SE) of 6G wireless networks. However, practical deployment remains constrained by challenges in accurate channel estimation and control optimization under dynamic conditions. This paper presents a foundation model-aided hierarchical deep reinforcement learning (FM-HDRL) framework designed for joint beamforming and phase-shift optimization in RIS-assisted wireless networks. To implement this, we first fine-tune a pre-trained large wireless model (LWM) to translate raw channel data into low-dimensional, context-aware channel state information (CSI) embeddings. Next, these embeddings are combined with user location information and blockage status to select the optimal communication path. The resulting features are then fed into an HDRL model, assumed to be implemented at a centralized controller, which jointly optimizes the base station (BS) beamforming vectors and the RIS phase-shift configurations to maximize SE. Simulation results demonstrate that the proposed FM-HDRL framework consistently outperforms baseline methods in terms of convergence speed, spectral efficiency, and scalability. According to the simulation results, our proposed method improves 7.82% SE compared to the FM-aided deep reinforcement learning (FM-DRL) approach and a substantial enhancement of about 48.66% relative to the beam sweeping approach.
Multi-Modal Data-Enhanced Foundation Models for Prediction and Control in Wireless Networks: A Survey
Jan 06, 2026Foundation models (FMs) are recognized as a transformative breakthrough that has started to reshape the future of artificial intelligence (AI) across both academia and industry. The integration of FMs into wireless networks is expected to enable the development of general-purpose AI agents capable of handling diverse network management requests and highly complex wireless-related tasks involving multi-modal data. Inspired by these ideas, this work discusses the utilization of FMs, especially multi-modal FMs in wireless networks. We focus on two important types of tasks in wireless network management: prediction tasks and control tasks. In particular, we first discuss FMs-enabled multi-modal contextual information understanding in wireless networks. Then, we explain how FMs can be applied to prediction and control tasks, respectively. Following this, we introduce the development of wireless-specific FMs from two perspectives: available datasets for development and the methodologies used. Finally, we conclude with a discussion of the challenges and future directions for FM-enhanced wireless networks.
Foundation Model-Aided Hierarchical Control for Robust RIS-Assisted Near-Field Communications
Jan 06, 2026The deployment of extremely large aperture arrays (ELAAs) in sixth-generation (6G) networks could shift communication into the near-field communication (NFC) regime. In this regime, signals exhibit spherical wave propagation, unlike the planar waves in conventional far-field systems. Reconfigurable intelligent surfaces (RISs) can dynamically adjust phase shifts to support NFC beamfocusing, concentrating signal energy at specific spatial coordinates. However, effective RIS utilization depends on both rapid channel state information (CSI) estimation and proactive blockage mitigation, which occur on inherently different timescales. CSI varies at millisecond intervals due to small-scale fading, while blockage events evolve over seconds, posing challenges for conventional single-level control algorithms. To address this issue, we propose a dual-transformer (DT) hierarchical framework that integrates two specialized transformer models within a hierarchical deep reinforcement learning (HDRL) architecture, referred to as the DT-HDRL framework. A fast-timescale transformer processes ray-tracing data for rapid CSI estimation, while a vision transformer (ViT) analyzes visual data to predict impending blockages. In HDRL, the high-level controller selects line-of-sight (LoS) or RIS-assisted non-line-of-sight (NLoS) transmission paths and sets goals, while the low-level controller optimizes base station (BS) beamfocusing and RIS phase shifts using instantaneous CSI. This dual-timescale coordination maximizes spectral efficiency (SE) while ensuring robust performance under dynamic conditions. Simulation results demonstrate that our approach improves SE by approximately 18% compared to single-timescale baselines, while the proposed blockage predictor achieves an F1-score of 0.92, providing a 769 ms advance warning window in dynamic scenarios.
Foundation Model-Aided Deep Reinforcement Learning for RIS-Assisted Wireless Communication
Jun 11, 2025Reconfigurable intelligent surfaces (RIS) have emerged as a promising technology for enhancing wireless communication by dynamically controlling signal propagation in the environment. However, their efficient deployment relies on accurate channel state information (CSI), which leads to high channel estimation overhead due to their passive nature and the large number of reflective elements. In this work, we solve this challenge by proposing a novel framework that leverages a pre-trained open-source foundation model (FM) named large wireless model (LWM) to process wireless channels and generate versatile and contextualized channel embeddings. These embeddings are then used for the joint optimization of the BS beamforming and RIS configurations. To be more specific, for joint optimization, we design a deep reinforcement learning (DRL) model to automatically select the BS beamforming vector and RIS phase-shift matrix, aiming to maximize the spectral efficiency (SE). This work shows that a pre-trained FM for radio signal understanding can be fine-tuned and integrated with DRL for effective decision-making in wireless networks. It highlights the potential of modality-specific FMs in real-world network optimization. According to the simulation results, the proposed method outperforms the DRL-based approach and beam sweeping-based approach, achieving 9.89% and 43.66% higher SE, respectively.
Conditional Denoising Diffusion for ISAC Enhanced Channel Estimation in Cell-Free 6G
Jun 07, 2025Cell-free Integrated Sensing and Communication (ISAC) aims to revolutionize 6th Generation (6G) networks. By combining distributed access points with ISAC capabilities, it boosts spectral efficiency, situational awareness, and communication reliability. Channel estimation is a critical step in cell-free ISAC systems to ensure reliable communication, but its performance is usually limited by challenges such as pilot contamination and noisy channel estimates. This paper presents a novel framework leveraging sensing information as a key input within a Conditional Denoising Diffusion Model (CDDM). In this framework, we integrate CDDM with a Multimodal Transformer (MMT) to enhance channel estimation in ISAC-enabled cell-free systems. The MMT encoder effectively captures inter-modal relationships between sensing and location data, enabling the CDDM to iteratively denoise and refine channel estimates. Simulation results demonstrate that the proposed approach achieves significant performance gains. As compared with Least Squares (LS) and Minimum Mean Squared Error (MMSE) estimators, the proposed model achieves normalized mean squared error (NMSE) improvements of 8 dB and 9 dB, respectively. Moreover, we achieve a 27.8% NMSE improvement compared to the traditional denoising diffusion model (TDDM), which does not incorporate sensing channel information. Additionally, the model exhibits higher robustness against pilot contamination and maintains high accuracy under challenging conditions, such as low signal-to-noise ratios (SNRs). According to the simulation results, the model performs well for users near sensing targets by leveraging the correlation between sensing and communication channels.
Backdoor Detection through Replicated Execution of Outsourced Training
Mar 31, 2025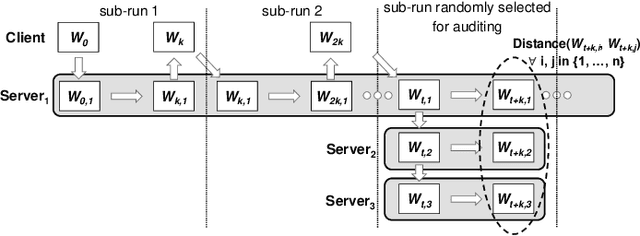
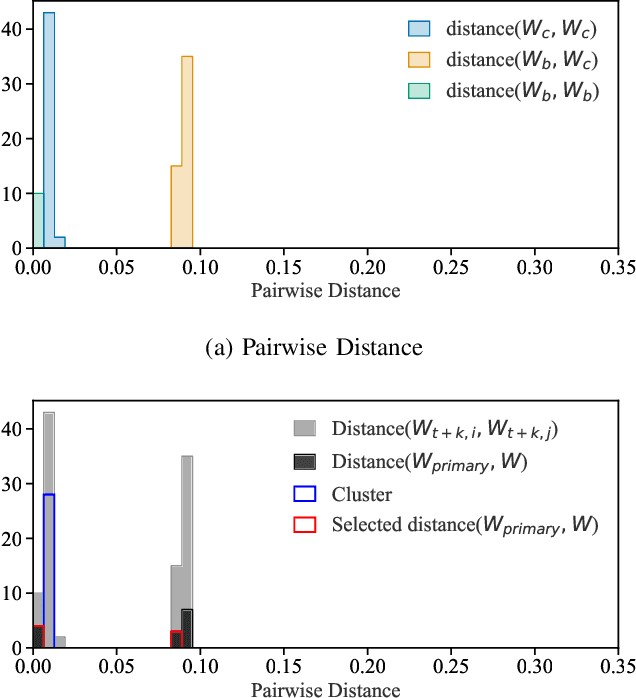
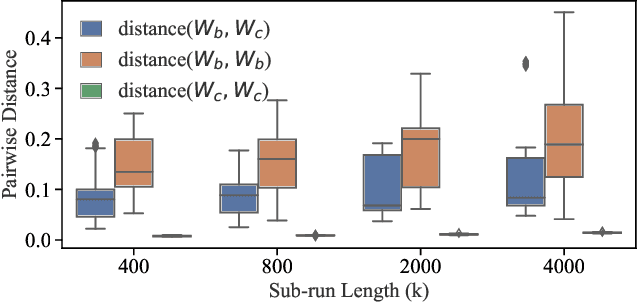
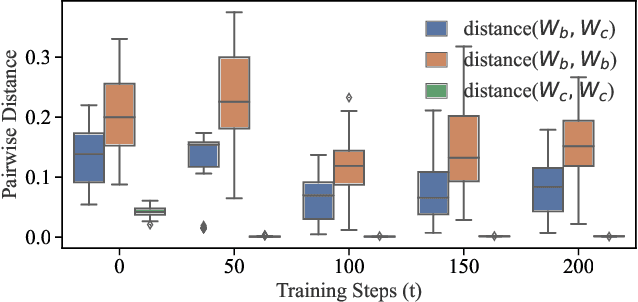
It is common practice to outsource the training of machine learning models to cloud providers. Clients who do so gain from the cloud's economies of scale, but implicitly assume trust: the server should not deviate from the client's training procedure. A malicious server may, for instance, seek to insert backdoors in the model. Detecting a backdoored model without prior knowledge of both the backdoor attack and its accompanying trigger remains a challenging problem. In this paper, we show that a client with access to multiple cloud providers can replicate a subset of training steps across multiple servers to detect deviation from the training procedure in a similar manner to differential testing. Assuming some cloud-provided servers are benign, we identify malicious servers by the substantial difference between model updates required for backdooring and those resulting from clean training. Perhaps the strongest advantage of our approach is its suitability to clients that have limited-to-no local compute capability to perform training; we leverage the existence of multiple cloud providers to identify malicious updates without expensive human labeling or heavy computation. We demonstrate the capabilities of our approach on an outsourced supervised learning task where $50\%$ of the cloud providers insert their own backdoor; our approach is able to correctly identify $99.6\%$ of them. In essence, our approach is successful because it replaces the signature-based paradigm taken by existing approaches with an anomaly-based detection paradigm. Furthermore, our approach is robust to several attacks from adaptive adversaries utilizing knowledge of our detection scheme.
Beam Selection in ISAC using Contextual Bandit with Multi-modal Transformer and Transfer Learning
Mar 11, 2025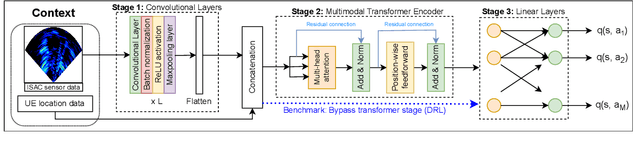
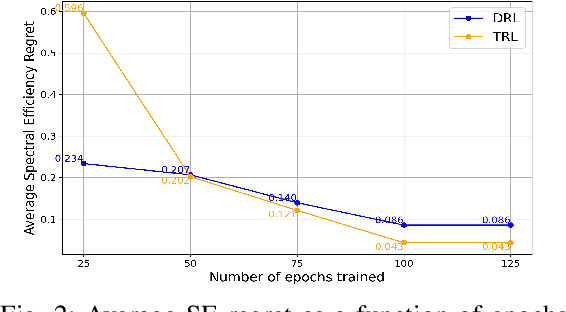
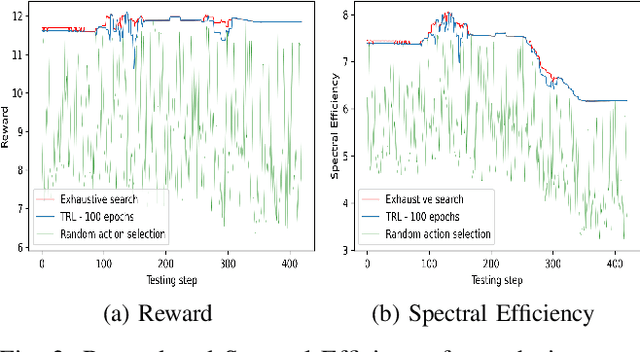
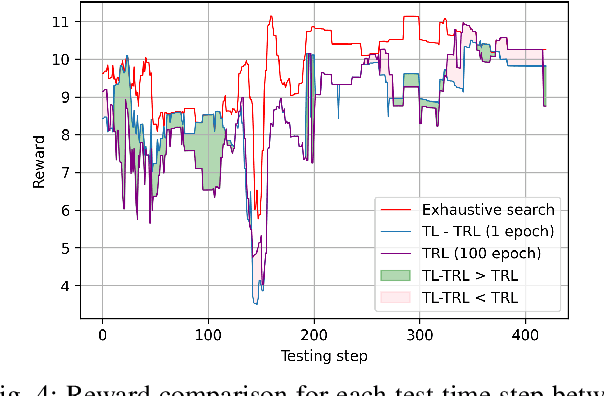
Sixth generation (6G) wireless technology is anticipated to introduce Integrated Sensing and Communication (ISAC) as a transformative paradigm. ISAC unifies wireless communication and RADAR or other forms of sensing to optimize spectral and hardware resources. This paper presents a pioneering framework that leverages ISAC sensing data to enhance beam selection processes in complex indoor environments. By integrating multi-modal transformer models with a multi-agent contextual bandit algorithm, our approach utilizes ISAC sensing data to improve communication performance and achieves high spectral efficiency (SE). Specifically, the multi-modal transformer can capture inter-modal relationships, enhancing model generalization across diverse scenarios. Experimental evaluations on the DeepSense 6G dataset demonstrate that our model outperforms traditional deep reinforcement learning (DRL) methods, achieving superior beam prediction accuracy and adaptability. In the single-user scenario, we achieve an average SE regret improvement of 49.6% as compared to DRL. Furthermore, we employ transfer reinforcement learning to reduce training time and improve model performance in multi-user environments. In the multi-user scenario, this approach enhances the average SE regret, which is a measure to demonstrate how far the learned policy is from the optimal SE policy, by 19.7% compared to training from scratch, even when the latter is trained 100 times longer.
Generative AI-enabled Blockage Prediction for Robust Dual-Band mmWave Communication
Jan 20, 2025



In mmWave wireless networks, signal blockages present a significant challenge due to the susceptibility to environmental moving obstructions. Recently, the availability of visual data has been leveraged to enhance blockage prediction accuracy in mmWave networks. In this work, we propose a Vision Transformer (ViT)-based approach for visual-aided blockage prediction that intelligently switches between mmWave and Sub-6 GHz frequencies to maximize network throughput and maintain reliable connectivity. Given the computational demands of processing visual data, we implement our solution within a hierarchical fog-cloud computing architecture, where fog nodes collaborate with cloud servers to efficiently manage computational tasks. This structure incorporates a generative AI-based compression technique that significantly reduces the volume of visual data transmitted between fog nodes and cloud centers. Our proposed method is tested with the real-world DeepSense 6G dataset, and according to the simulation results, it achieves a blockage prediction accuracy of 92.78% while reducing bandwidth usage by 70.31%.
Multi-Modal Transformer and Reinforcement Learning-based Beam Management
Oct 22, 2024


Beam management is an important technique to improve signal strength and reduce interference in wireless communication systems. Recently, there has been increasing interest in using diverse sensing modalities for beam management. However, it remains a big challenge to process multi-modal data efficiently and extract useful information. On the other hand, the recently emerging multi-modal transformer (MMT) is a promising technique that can process multi-modal data by capturing long-range dependencies. While MMT is highly effective in handling multi-modal data and providing robust beam management, integrating reinforcement learning (RL) further enhances their adaptability in dynamic environments. In this work, we propose a two-step beam management method by combining MMT with RL for dynamic beam index prediction. In the first step, we divide available beam indices into several groups and leverage MMT to process diverse data modalities to predict the optimal beam group. In the second step, we employ RL for fast beam decision-making within each group, which in return maximizes throughput. Our proposed framework is tested on a 6G dataset. In this testing scenario, it achieves higher beam prediction accuracy and system throughput compared to both the MMT-only based method and the RL-only based method.
Generative AI-in-the-loop: Integrating LLMs and GPTs into the Next Generation Networks
Jun 06, 2024In recent years, machine learning (ML) techniques have created numerous opportunities for intelligent mobile networks and have accelerated the automation of network operations. However, complex network tasks may involve variables and considerations even beyond the capacity of traditional ML algorithms. On the other hand, large language models (LLMs) have recently emerged, demonstrating near-human-level performance in cognitive tasks across various fields. However, they remain prone to hallucinations and often lack common sense in basic tasks. Therefore, they are regarded as assistive tools for humans. In this work, we propose the concept of "generative AI-in-the-loop" and utilize the semantic understanding, context awareness, and reasoning abilities of LLMs to assist humans in handling complex or unforeseen situations in mobile communication networks. We believe that combining LLMs and ML models allows both to leverage their respective capabilities and achieve better results than either model alone. To support this idea, we begin by analyzing the capabilities of LLMs and compare them with traditional ML algorithms. We then explore potential LLM-based applications in line with the requirements of next-generation networks. We further examine the integration of ML and LLMs, discussing how they can be used together in mobile networks. Unlike existing studies, our research emphasizes the fusion of LLMs with traditional ML-driven next-generation networks and serves as a comprehensive refinement of existing surveys. Finally, we provide a case study to enhance ML-based network intrusion detection with synthesized data generated by LLMs. Our case study further demonstrates the advantages of our proposed idea.