 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Detection through Replicated Execution of Outsourced Training
Mar 31, 2025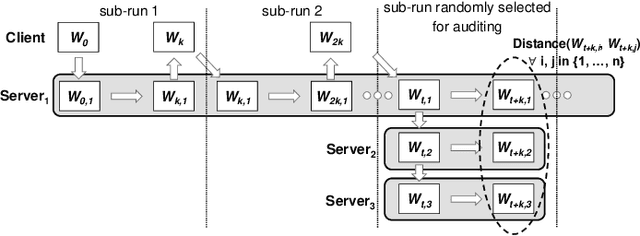
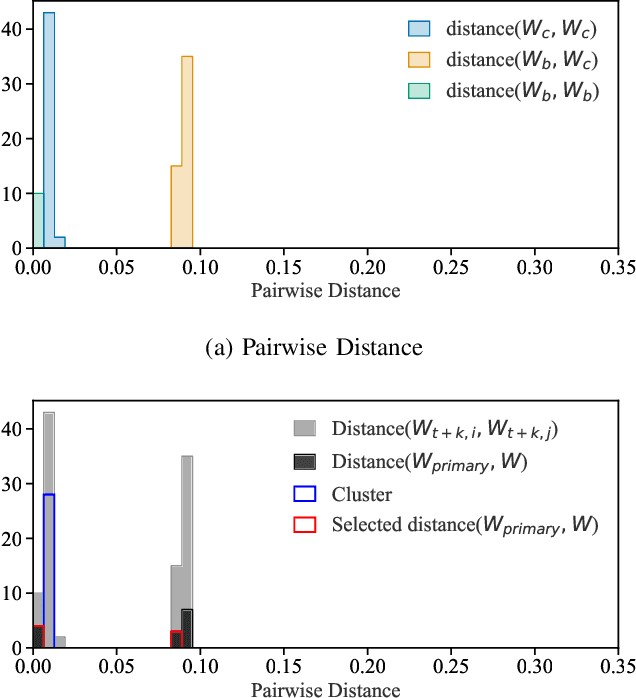
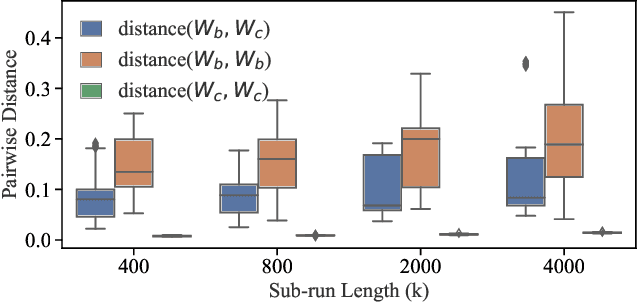
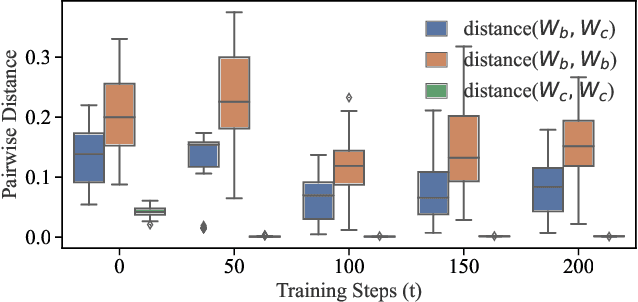
It is common practice to outsource the training of machine learning models to cloud providers. Clients who do so gain from the cloud's economies of scale, but implicitly assume trust: the server should not deviate from the client's training procedure. A malicious server may, for instance, seek to insert backdoors in the model. Detecting a backdoored model without prior knowledge of both the backdoor attack and its accompanying trigger remains a challenging problem. In this paper, we show that a client with access to multiple cloud providers can replicate a subset of training steps across multiple servers to detect deviation from the training procedure in a similar manner to differential testing. Assuming some cloud-provided servers are benign, we identify malicious servers by the substantial difference between model updates required for backdooring and those resulting from clean training. Perhaps the strongest advantage of our approach is its suitability to clients that have limited-to-no local compute capability to perform training; we leverage the existence of multiple cloud providers to identify malicious updates without expensive human labeling or heavy computation. We demonstrate the capabilities of our approach on an outsourced supervised learning task where $50\%$ of the cloud providers insert their own backdoor; our approach is able to correctly identify $99.6\%$ of them. In essence, our approach is successful because it replaces the signature-based paradigm taken by existing approaches with an anomaly-based detection paradigm. Furthermore, our approach is robust to several attacks from adaptive adversaries utilizing knowledge of our detection scheme.
Fairness Feedback Loops: Training on Synthetic Data Amplifies Bias
Mar 12, 2024



Model-induced distribution shifts (MIDS) occur as previous model outputs pollute new model training sets over generations of models. This is known as model collapse in the case of generative models, and performative prediction or unfairness feedback loops for supervised models. When a model induces a distribution shift, it also encodes its mistakes, biases, and unfairnesses into the ground truth of its data ecosystem. We introduce a framework that allows us to track multiple MIDS over many generations, finding that they can lead to loss in performance, fairness, and minoritized group representation, even in initially unbiased datasets. Despite these negative consequences, we identify how models might be used for positive, intentional, interventions in their data ecosystems, providing redress for historical discrimination through a framework called algorithmic reparation (AR). We simulate AR interventions by curating representative training batches for stochastic gradient descent to demonstrate how AR can improve upon the unfairnesses of models and data ecosystems subject to other MIDS. Our work takes an important step towards identifying, mitigating, and taking accountability for the unfair feedback loops enabled by the idea that ML systems are inherently neutral and objective.