 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Circuit Pre-Synthesis: Learning Local Edits to Reduce $T$-count
Jan 27, 2026Compiling quantum circuits into Clifford+$T$ gates is a central task for fault-tolerant quantum computing using stabilizer codes. In the near term, $T$ gates will dominate the cost of fault tolerant implementations, and any reduction in the number of such expensive gates could mean the difference between being able to run a circuit or not. While exact synthesis is exponentially hard in the number of qubits, local synthesis approaches are commonly used to compile large circuits by decomposing them into substructures. However, composing local methods leads to suboptimal compilations in key metrics such as $T$-count or circuit depth, and their performance strongly depends on circuit representation. In this work, we address this challenge by proposing \textsc{Q-PreSyn}, a strategy that, given a set of local edits preserving circuit equivalence, uses a RL agent to identify effective sequences of such actions and thereby obtain circuit representations that yield a reduced $T$-count upon synthesis. Experimental results of our proposed strategy, applied on top of well-known synthesis algorithms, show up to a $20\%$ reduction in $T$-count on circuits with up to 25 qubits, without introducing any additional approximation error prior to synthesis.
Integrated Encoding and Quantization to Enhance Quanvolutional Neural Networks
Oct 08, 2024
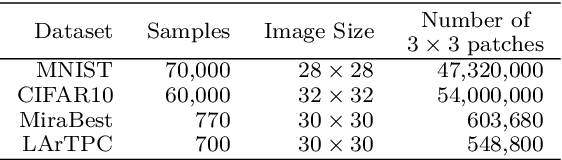


Image processing is one of the most promising applications for quantum machine learning (QML). Quanvolutional Neural Networks with non-trainable parameters are the preferred solution to run on current and near future quantum devices. The typical input preprocessing pipeline for quanvolutional layers comprises of four steps: optional input binary quantization, encoding classical data into quantum states, processing the data to obtain the final quantum states, decoding quantum states back to classical outputs. In this paper we propose two ways to enhance the efficiency of quanvolutional models. First, we propose a flexible data quantization approach with memoization, applicable to any encoding method. This allows us to increase the number of quantization levels to retain more information or lower them to reduce the amount of circuit executions. Second, we introduce a new integrated encoding strategy, which combines the encoding and processing steps in a single circuit. This method allows great flexibility on several architectural parameters (e.g., number of qubits, filter size, and circuit depth) making them adjustable to quantum hardware requirements. We compare our proposed integrated model with a classical convolutional neural network and the well-known rotational encoding method, on two different classification tasks. The results demonstrate that our proposed model encoding exhibits a comparable or superior performance to the other models while requiring fewer quantum resources.