 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Feedback-to-Plan Decisions for Self-Evolving LLM Agents in CUDA Kernel Generation
May 26, 2026Large language models (LLMs) have shown strong empirical gains as self-evolving agents for CUDA kernel generation, driven by feedback-conditioned planning across generations. However, how planning decisions attribute and combine heterogeneous feedback signals remains opaque. Standard end-to-end ablations fail to resolve this question, as iterative planning amplifies early perturbations and conflates feedback effects with trajectory-dependent drift. We introduce \texttt{CUDAnalyst}, a unified analysis layer for controlled, generation-level attribution of planning decisions to feedback components via trajectory freezing and selective feedback injection. \texttt{CUDAnalyst} enables stable generation-level evaluation and principled coalitional-style attribution of feedback effects and interactions. Our results show that explicit planning is beneficial only when feedback is aligned, that effective planning emerges from structured multi-feedback interactions, and that high-level plans from stronger reasoning models can partially transfer to weaker ones. These trends hold across reference backbones, representative workloads, and reference induction regimes, indicating that the identified feedback-to-plan structure is robust within the controlled axes studied.
HybridFlow: A Two-Step Generative Policy for Robotic Manipulation
Feb 14, 2026Limited by inference latency, existing robot manipulation policies lack sufficient real-time interaction capability with the environment. Although faster generation methods such as flow matching are gradually replacing diffusion methods, researchers are pursuing even faster generation suitable for interactive robot control. MeanFlow, as a one-step variant of flow matching, has shown strong potential in image generation, but its precision in action generation does not meet the stringent requirements of robotic manipulation. We therefore propose \textbf{HybridFlow}, a \textbf{3-stage method} with \textbf{2-NFE}: Global Jump in MeanFlow mode, ReNoise for distribution alignment, and Local Refine in ReFlow mode. This method balances inference speed and generation quality by leveraging the rapid advantage of MeanFlow one-step generation while ensuring action precision with minimal generation steps. Through real-world experiments, HybridFlow outperforms the 16-step Diffusion Policy by \textbf{15--25\%} in success rate while reducing inference time from 152ms to 19ms (\textbf{8$\times$ speedup}, \textbf{$\sim$52Hz}); it also achieves 70.0\% success on unseen-color OOD grasping and 66.3\% on deformable object folding. We envision HybridFlow as a practical low-latency method to enhance real-world interaction capabilities of robotic manipulation policies.
YOLO-LLTS: Real-Time Low-Light Traffic Sign Detection via Prior-Guided Enhancement and Multi-Branch Feature Interaction
Mar 18, 2025Detecting traffic signs effectively under low-light conditions remains a significant challenge. To address this issue, we propose YOLO-LLTS, an end-to-end real-time traffic sign detection algorithm specifically designed for low-light environments. Firstly, we introduce the High-Resolution Feature Map for Small Object Detection (HRFM-TOD) module to address indistinct small-object features in low-light scenarios. By leveraging high-resolution feature maps, HRFM-TOD effectively mitigates the feature dilution problem encountered in conventional PANet frameworks, thereby enhancing both detection accuracy and inference speed. Secondly, we develop the Multi-branch Feature Interaction Attention (MFIA) module, which facilitates deep feature interaction across multiple receptive fields in both channel and spatial dimensions, significantly improving the model's information extraction capabilities. Finally, we propose the Prior-Guided Enhancement Module (PGFE) to tackle common image quality challenges in low-light environments, such as noise, low contrast, and blurriness. This module employs prior knowledge to enrich image details and enhance visibility, substantially boosting detection performance. To support this research, we construct a novel dataset, the Chinese Nighttime Traffic Sign Sample Set (CNTSSS), covering diverse nighttime scenarios, including urban, highway, and rural environments under varying weather conditions. Experimental evaluations demonstrate that YOLO-LLTS achieves state-of-the-art performance, outperforming the previous best methods by 2.7% mAP50 and 1.6% mAP50:95 on TT100K-night, 1.3% mAP50 and 1.9% mAP50:95 on CNTSSS, and achieving superior results on the CCTSDB2021 dataset. Moreover, deployment experiments on edge devices confirm the real-time applicability and effectiveness of our proposed approach.
A GREAT Architecture for Edge-Based Graph Problems Like TSP
Aug 29, 2024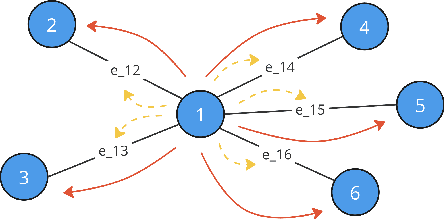
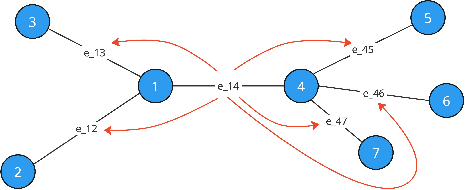
In the last years, many neural network-based approaches have been proposed to tackle combinatorial optimization problems such as routing problems. Many of these approaches are based on graph neural networks (GNNs) or related transformers, operating on the Euclidean coordinates representing the routing problems. However, GNNs are inherently not well suited to operate on dense graphs, such as in routing problems. Furthermore, models operating on Euclidean coordinates cannot be applied to non-Euclidean versions of routing problems that are often found in real-world settings. To overcome these limitations, we propose a novel GNN-related edge-based neural model called Graph Edge Attention Network (GREAT). We evaluate the performance of GREAT in the edge-classification task to predict optimal edges in the Traveling Salesman Problem (TSP). We can use such a trained GREAT model to produce sparse TSP graph instances, keeping only the edges GREAT finds promising. Compared to other, non-learning-based methods to sparsify TSP graphs, GREAT can produce very sparse graphs while keeping most of the optimal edges. Furthermore, we build a reinforcement learning-based GREAT framework which we apply to Euclidean and non-Euclidean asymmetric TSP. This framework achieves state-of-the-art results.
Less Is More -- On the Importance of Sparsification for Transformers and Graph Neural Networks for TSP
Mar 25, 2024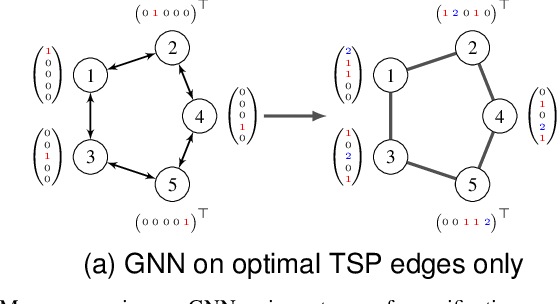
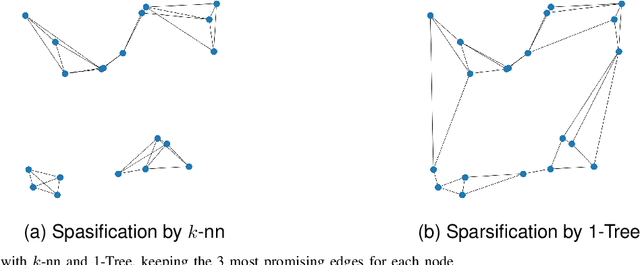


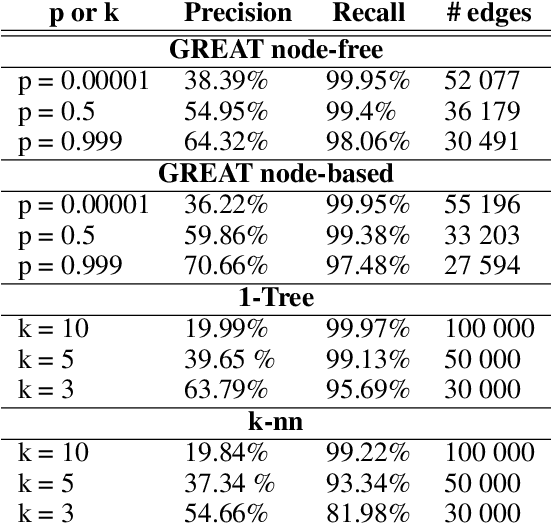
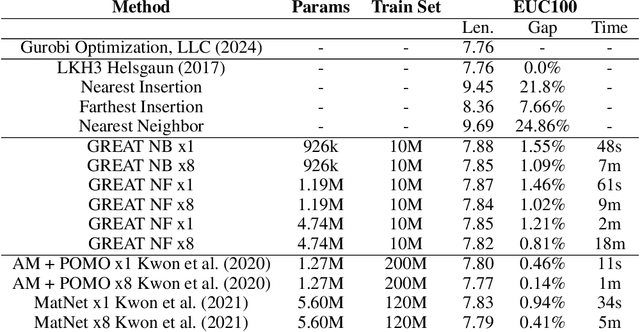
Most of the recent studies tackling routing problems like the Traveling Salesman Problem (TSP) with machine learning use a transformer or Graph Neural Network (GNN) based encoder architecture. However, many of them apply these encoders naively by allowing them to aggregate information over the whole TSP instances. We, on the other hand, propose a data preprocessing method that allows the encoders to focus on the most relevant parts of the TSP instances only. In particular, we propose graph sparsification for TSP graph representations passed to GNNs and attention masking for TSP instances passed to transformers where the masks correspond to the adjacency matrices of the sparse TSP graph representations. Furthermore, we propose ensembles of different sparsification levels allowing models to focus on the most promising parts while also allowing information flow between all nodes of a TSP instance. In the experimental studies, we show that for GNNs appropriate sparsification and ensembles of different sparsification levels lead to substantial performance increases of the overall architecture. We also design a new, state-of-the-art transformer encoder with ensembles of attention masking. These transformers increase model performance from a gap of $0.16\%$ to $0.10\%$ for TSP instances of size 100 and from $0.02\%$ to $0.00\%$ for TSP instances of size 50.
Quantifying white matter hyperintensity and brain volumes in heterogeneous clinical and low-field portable MRI
Dec 08, 2023
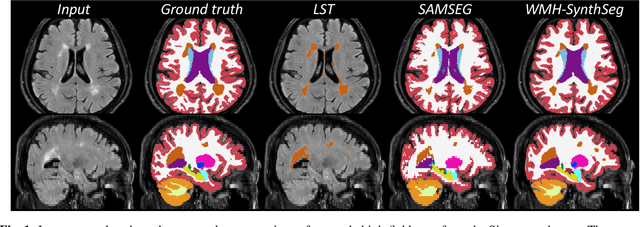
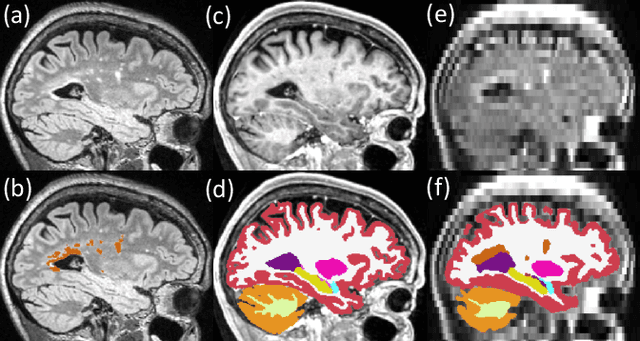

Brain atrophy and white matter hyperintensity (WMH) are critical neuroimaging features for ascertaining brain injury in cerebrovascular disease and multiple sclerosis. Automated segmentation and quantification is desirable but existing methods require high-resolution MRI with good signal-to-noise ratio (SNR). This precludes application to clinical and low-field portable MRI (pMRI) scans, thus hampering large-scale tracking of atrophy and WMH progression, especially in underserved areas where pMRI has huge potential. Here we present a method that segments white matter hyperintensity and 36 brain regions from scans of any resolution and contrast (including pMRI) without retraining. We show results on six public datasets and on a private dataset with paired high- and low-field scans (3T and 64mT), where we attain strong correlation between the WMH ($\rho$=.85) and hippocampal volumes (r=.89) estimated at both fields. Our method is publicly available as part of FreeSurfer, at: http://surfer.nmr.mgh.harvard.edu/fswiki/WMH-SynthSeg.
Scene Inference for Object Illumination Editing
Jul 31, 2021

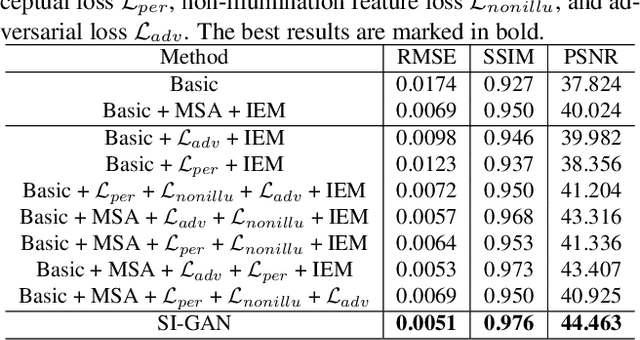
The seamless illumination integration between a foreground object and a background scene is an important but challenging task in computer vision and augmented reality community. However, to our knowledge, there is no publicly available high-quality dataset that meets the illumination seamless integration task, which greatly hinders the development of this research direction. To this end, we apply a physically-based rendering method to create a large-scale, high-quality dataset, named IH dataset, which provides rich illumination information for seamless illumination integration task. In addition, we propose a deep learning-based SI-GAN method, a multi-task collaborative network, which makes full use of the multi-scale attention mechanism and adversarial learning strategy to directly infer mapping relationship between the inserted foreground object and corresponding background environment, and edit object illumination according to the proposed illumination exchange mechanism in parallel network. By this means, we can achieve the seamless illumination integration without explicit estimation of 3D geometric information. Comprehensive experiments on both our dataset and real-world images collected from the Internet show that our proposed SI-GAN provides a practical and effective solution for image-based object illumination editing, and validate the superiority of our method against state-of-the-art methods.