 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGREAT-EER: Graph Edge Attention Network for Emergency Evacuation Responses
Feb 16, 2026Emergency situations that require the evacuation of urban areas can arise from man-made causes (e.g., terrorist attacks or industrial accidents) or natural disasters, the latter becoming more frequent due to climate change. As a result, effective and fast methods to develop evacuation plans are of great importance. In this work, we identify and propose the Bus Evacuation Orienteering Problem (BEOP), an NP-hard combinatorial optimization problem with the goal of evacuating as many people from an affected area by bus in a short, predefined amount of time. The purpose of bus-based evacuation is to reduce congestion and disorder that arises in purely car-focused evacuation scenarios. To solve the BEOP, we propose a deep reinforcement learning-based method utilizing graph learning, which, once trained, achieves fast inference speed and is able to create evacuation routes in fractions of seconds. We can bound the gap of our evacuation plans using an MILP formulation. To validate our method, we create evacuation scenarios for San Francisco using real-world road networks and travel times. We show that we achieve near-optimal solution quality and are further able to investigate how many evacuation vehicles are necessary to achieve certain bus-based evacuation quotas given a predefined evacuation time while keeping run time adequate.
Towards Reproducibility in Predictive Process Mining: SPICE -- A Deep Learning Library
Dec 19, 2025



In recent years, Predictive Process Mining (PPM) techniques based on artificial neural networks have evolved as a method for monitoring the future behavior of unfolding business processes and predicting Key Performance Indicators (KPIs). However, many PPM approaches often lack reproducibility, transparency in decision making, usability for incorporating novel datasets and benchmarking, making comparisons among different implementations very difficult. In this paper, we propose SPICE, a Python framework that reimplements three popular, existing baseline deep-learning-based methods for PPM in PyTorch, while designing a common base framework with rigorous configurability to enable reproducible and robust comparison of past and future modelling approaches. We compare SPICE to original reported metrics and with fair metrics on 11 datasets.
Directly Follows Graphs Go Predictive Process Monitoring With Graph Neural Networks
Mar 05, 2025In the past years, predictive process monitoring (PPM) techniques based on artificial neural networks have evolved as a method to monitor the future behavior of business processes. Existing approaches mostly focus on interpreting the processes as sequences, so-called traces, and feeding them to neural architectures designed to operate on sequential data such as recurrent neural networks (RNNs) or transformers. In this study, we investigate an alternative way to perform PPM: by transforming each process in its directly-follows-graph (DFG) representation we are able to apply graph neural networks (GNNs) for the prediction tasks. By this, we aim to develop models that are more suitable for complex processes that are long and contain an abundance of loops. In particular, we present different ways to create DFG representations depending on the particular GNN we use. The tested GNNs range from classical node-based to novel edge-based architectures. Further, we investigate the possibility of using multi-graphs. By these steps, we aim to design graph representations that minimize the information loss when transforming traces into graphs.
A GREAT Architecture for Edge-Based Graph Problems Like TSP
Aug 29, 2024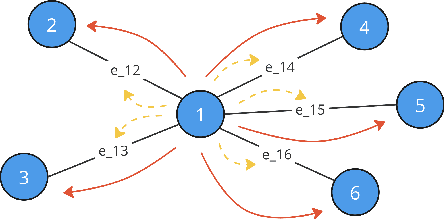
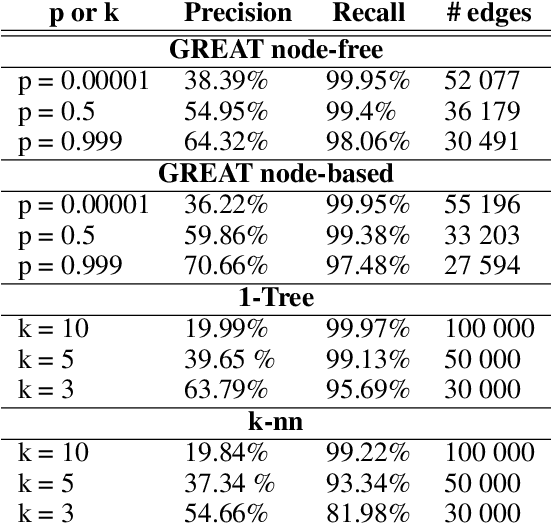
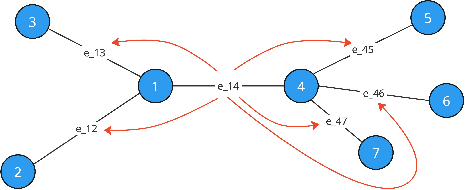
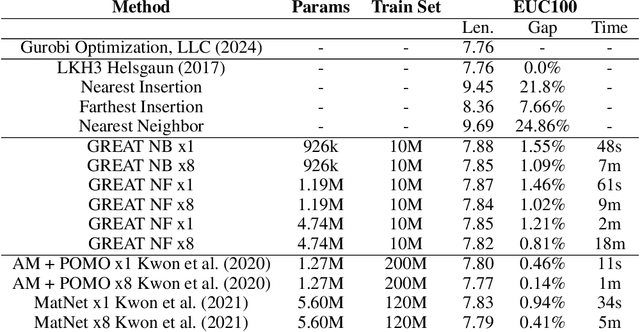
In the last years, many neural network-based approaches have been proposed to tackle combinatorial optimization problems such as routing problems. Many of these approaches are based on graph neural networks (GNNs) or related transformers, operating on the Euclidean coordinates representing the routing problems. However, GNNs are inherently not well suited to operate on dense graphs, such as in routing problems. Furthermore, models operating on Euclidean coordinates cannot be applied to non-Euclidean versions of routing problems that are often found in real-world settings. To overcome these limitations, we propose a novel GNN-related edge-based neural model called Graph Edge Attention Network (GREAT). We evaluate the performance of GREAT in the edge-classification task to predict optimal edges in the Traveling Salesman Problem (TSP). We can use such a trained GREAT model to produce sparse TSP graph instances, keeping only the edges GREAT finds promising. Compared to other, non-learning-based methods to sparsify TSP graphs, GREAT can produce very sparse graphs while keeping most of the optimal edges. Furthermore, we build a reinforcement learning-based GREAT framework which we apply to Euclidean and non-Euclidean asymmetric TSP. This framework achieves state-of-the-art results.
Less Is More -- On the Importance of Sparsification for Transformers and Graph Neural Networks for TSP
Mar 25, 2024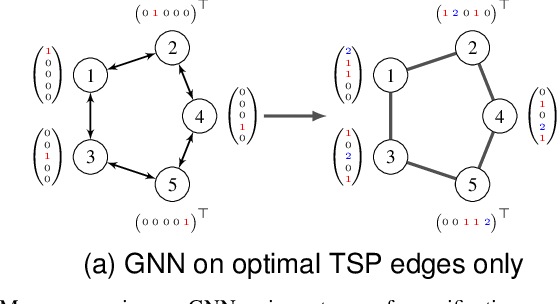
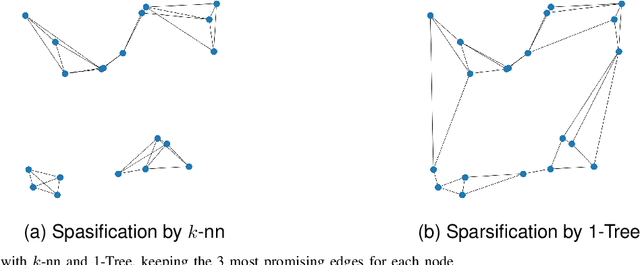


Most of the recent studies tackling routing problems like the Traveling Salesman Problem (TSP) with machine learning use a transformer or Graph Neural Network (GNN) based encoder architecture. However, many of them apply these encoders naively by allowing them to aggregate information over the whole TSP instances. We, on the other hand, propose a data preprocessing method that allows the encoders to focus on the most relevant parts of the TSP instances only. In particular, we propose graph sparsification for TSP graph representations passed to GNNs and attention masking for TSP instances passed to transformers where the masks correspond to the adjacency matrices of the sparse TSP graph representations. Furthermore, we propose ensembles of different sparsification levels allowing models to focus on the most promising parts while also allowing information flow between all nodes of a TSP instance. In the experimental studies, we show that for GNNs appropriate sparsification and ensembles of different sparsification levels lead to substantial performance increases of the overall architecture. We also design a new, state-of-the-art transformer encoder with ensembles of attention masking. These transformers increase model performance from a gap of $0.16\%$ to $0.10\%$ for TSP instances of size 100 and from $0.02\%$ to $0.00\%$ for TSP instances of size 50.