 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVLMs and Humans Ground Differently in Referential Communication
Jan 28, 2026For generative AI agents to partner effectively with human users, the ability to accurately predict human intent is critical. But this ability to collaborate remains limited by a critical deficit: an inability to model common ground. Here, we present a referential communication experiment with a factorial design involving director-matcher pairs (human-human, human-AI, AI-human, and AI-AI) that interact with multiple turns in repeated rounds to match pictures of objects not associated with any obvious lexicalized labels. We release the online pipeline for data collection, the tools and analyses for accuracy, efficiency, and lexical overlap, and a corpus of 356 dialogues (89 pairs over 4 rounds each) that unmasks LVLMs' limitations in interactively resolving referring expressions, a crucial skill that underlies human language use.
Mini-Hes: A Parallelizable Second-order Latent Factor Analysis Model
Feb 19, 2024Interactions among large number of entities is naturally high-dimensional and incomplete (HDI) in many big data related tasks. Behavioral characteristics of users are hidden in these interactions, hence, effective representation of the HDI data is a fundamental task for understanding user behaviors. Latent factor analysis (LFA) model has proven to be effective in representing HDI data. The performance of an LFA model relies heavily on its training process, which is a non-convex optimization. It has been proven that incorporating local curvature and preprocessing gradients during its training process can lead to superior performance compared to LFA models built with first-order family methods. However, with the escalation of data volume, the feasibility of second-order algorithms encounters challenges. To address this pivotal issue, this paper proposes a mini-block diagonal hessian-free (Mini-Hes) optimization for building an LFA model. It leverages the dominant diagonal blocks in the generalized Gauss-Newton matrix based on the analysis of the Hessian matrix of LFA model and serves as an intermediary strategy bridging the gap between first-order and second-order optimization methods. Experiment results indicate that, with Mini-Hes, the LFA model outperforms several state-of-the-art models in addressing missing data estimation task on multiple real HDI datasets from recommender system. (The source code of Mini-Hes is available at https://github.com/Goallow/Mini-Hes)
Representation Learning on Event Stream via an Elastic Net-incorporated Tensor Network
Jan 16, 2024Event cameras are neuromorphic sensors that capture asynchronous and sparse event stream when per-pixel brightness changes. The state-of-the-art processing methods for event signals typically aggregate events into a frame or a grid. However, events are dense in time, these works are limited to local information of events due to the stacking. In this paper, we present a novel spatiotemporal representation learning method which can capture the global correlations of all events in the event stream simultaneously by tensor decomposition. In addition, with the events are sparse in space, we propose an Elastic Net-incorporated tensor network (ENTN) model to obtain more spatial and temporal details about event stream. Empirically, the results indicate that our method can represent the spatiotemporal correlation of events with high quality, and can achieve effective results in applications like filtering noise compared with the state-of-the-art methods.
A Dynamic Linear Bias Incorporation Scheme for Nonnegative Latent Factor Analysis
Sep 19, 2023
High-Dimensional and Incomplete (HDI) data is commonly encountered in big data-related applications like social network services systems, which are concerning the limited interactions among numerous nodes. Knowledge acquisition from HDI data is a vital issue in the domain of data science due to their embedded rich patterns like node behaviors, where the fundamental task is to perform HDI data representation learning. Nonnegative Latent Factor Analysis (NLFA) models have proven to possess the superiority to address this issue, where a linear bias incorporation (LBI) scheme is important in present the training overshooting and fluctuation, as well as preventing the model from premature convergence. However, existing LBI schemes are all statistic ones where the linear biases are fixed, which significantly restricts the scalability of the resultant NLFA model and results in loss of representation learning ability to HDI data. Motivated by the above discoveries, this paper innovatively presents the dynamic linear bias incorporation (DLBI) scheme. It firstly extends the linear bias vectors into matrices, and then builds a binary weight matrix to switch the active/inactive states of the linear biases. The weight matrix's each entry switches between the binary states dynamically corresponding to the linear bias value variation, thereby establishing the dynamic linear biases for an NLFA model. Empirical studies on three HDI datasets from real applications demonstrate that the proposed DLBI-based NLFA model obtains higher representation accuracy several than state-of-the-art models do, as well as highly-competitive computational efficiency.
Proximal Symmetric Non-negative Latent Factor Analysis: A Novel Approach to Highly-Accurate Representation of Undirected Weighted Networks
Jun 06, 2023An Undirected Weighted Network (UWN) is commonly found in big data-related applications. Note that such a network's information connected with its nodes, and edges can be expressed as a Symmetric, High-Dimensional and Incomplete (SHDI) matrix. However, existing models fail in either modeling its intrinsic symmetry or low-data density, resulting in low model scalability or representation learning ability. For addressing this issue, a Proximal Symmetric Nonnegative Latent-factor-analysis (PSNL) model is proposed. It incorporates a proximal term into symmetry-aware and data density-oriented objective function for high representation accuracy. Then an adaptive Alternating Direction Method of Multipliers (ADMM)-based learning scheme is implemented through a Tree-structured of Parzen Estimators (TPE) method for high computational efficiency. Empirical studies on four UWNs demonstrate that PSNL achieves higher accuracy gain than state-of-the-art models, as well as highly competitive computational efficiency.
Multi-constrained Symmetric Nonnegative Latent Factor Analysis for Accurately Representing Large-scale Undirected Weighted Networks
Jun 06, 2023An Undirected Weighted Network (UWN) is frequently encountered in a big-data-related application concerning the complex interactions among numerous nodes, e.g., a protein interaction network from a bioinformatics application. A Symmetric High-Dimensional and Incomplete (SHDI) matrix can smoothly illustrate such an UWN, which contains rich knowledge like node interaction behaviors and local complexes. To extract desired knowledge from an SHDI matrix, an analysis model should carefully consider its symmetric-topology for describing an UWN's intrinsic symmetry. Representation learning to an UWN borrows the success of a pyramid of symmetry-aware models like a Symmetric Nonnegative Matrix Factorization (SNMF) model whose objective function utilizes a sole Latent Factor (LF) matrix for representing SHDI's symmetry rigorously. However, they suffer from the following drawbacks: 1) their computational complexity is high; and 2) their modeling strategy narrows their representation features, making them suffer from low learning ability. Aiming at addressing above critical issues, this paper proposes a Multi-constrained Symmetric Nonnegative Latent-factor-analysis (MSNL) model with two-fold ideas: 1) introducing multi-constraints composed of multiple LF matrices, i.e., inequality and equality ones into a data-density-oriented objective function for precisely representing the intrinsic symmetry of an SHDI matrix with broadened feature space; and 2) implementing an Alternating Direction Method of Multipliers (ADMM)-incorporated learning scheme for precisely solving such a multi-constrained model. Empirical studies on three SHDI matrices from a real bioinformatics or industrial application demonstrate that the proposed MSNL model achieves stronger representation learning ability to an SHDI matrix than state-of-the-art models do.
Incoporating Weighted Board Learning System for Accurate Occupational Pneumoconiosis Staging
Aug 13, 2022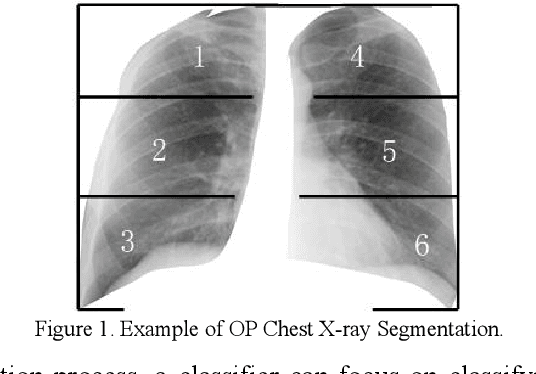
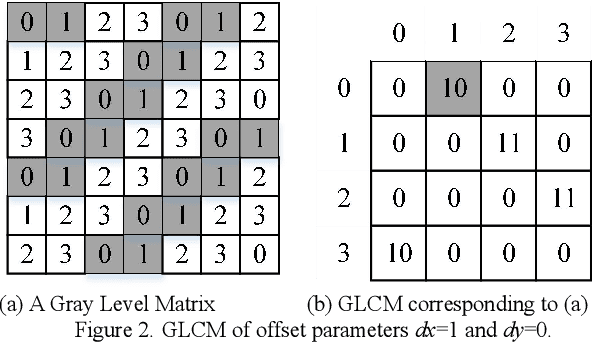


Occupational pneumoconiosis (OP) staging is a vital task concerning the lung healthy of a subject. The staging result of a patient is depended on the staging standard and his chest X-ray. It is essentially an image classification task. However, the distribution of OP data is commonly imbalanced, which largely reduces the effect of classification models which are proposed under the assumption that data follow a balanced distribution and causes inaccurate staging results. To achieve accurate OP staging, we proposed an OP staging model who is able to handle imbalance data in this work. The proposed model adopts gray level co-occurrence matrix (GLCM) to extract texture feature of chest X-ray and implements classification with a weighted broad learning system (WBLS). Empirical studies on six data cases provided by a hospital indicate that proposed model can perform better OP staging than state-of-the-art classifiers with imbalanced data.
A Practical Second-order Latent Factor Model via Distributed Particle Swarm Optimization
Aug 12, 2022



Latent Factor (LF) models are effective in representing high-dimension and sparse (HiDS) data via low-rank matrices approximation. Hessian-free (HF) optimization is an efficient method to utilizing second-order information of an LF model's objective function and it has been utilized to optimize second-order LF (SLF) model. However, the low-rank representation ability of a SLF model heavily relies on its multiple hyperparameters. Determining these hyperparameters is time-consuming and it largely reduces the practicability of an SLF model. To address this issue, a practical SLF (PSLF) model is proposed in this work. It realizes hyperparameter self-adaptation with a distributed particle swarm optimizer (DPSO), which is gradient-free and parallelized. Experiments on real HiDS data sets indicate that PSLF model has a competitive advantage over state-of-the-art models in data representation ability.
An Unconstrained Symmetric Nonnegative Latent Factor Analysis for Large-scale Undirected Weighted Networks
Aug 09, 2022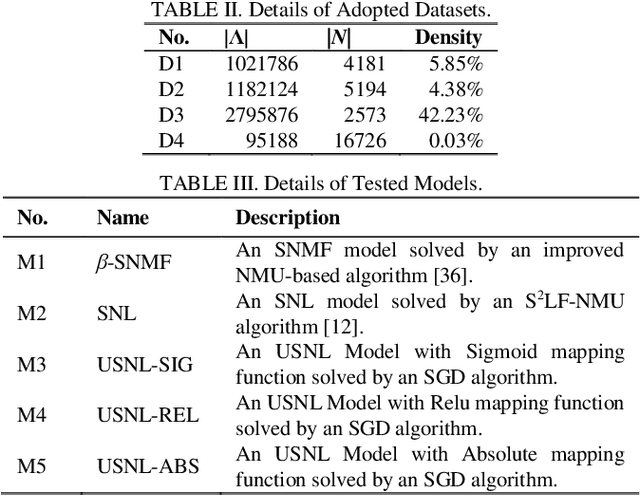
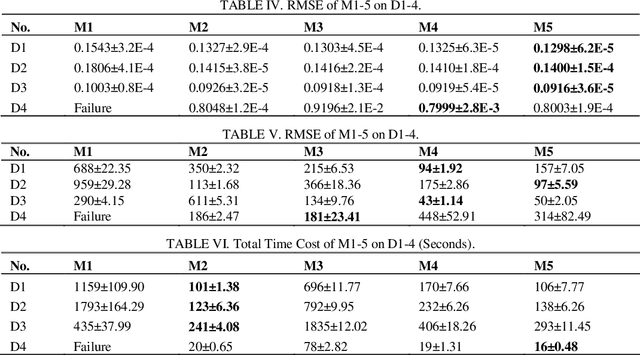
Large-scale undirected weighted networks are usually found in big data-related research fields. It can naturally be quantified as a symmetric high-dimensional and incomplete (SHDI) matrix for implementing big data analysis tasks. A symmetric non-negative latent-factor-analysis (SNL) model is able to efficiently extract latent factors (LFs) from an SHDI matrix. Yet it relies on a constraint-combination training scheme, which makes it lack flexibility. To address this issue, this paper proposes an unconstrained symmetric nonnegative latent-factor-analysis (USNL) model. Its main idea is two-fold: 1) The output LFs are separated from the decision parameters via integrating a nonnegative mapping function into an SNL model; and 2) Stochastic gradient descent (SGD) is adopted for implementing unconstrained model training along with ensuring the output LFs nonnegativity. Empirical studies on four SHDI matrices generated from real big data applications demonstrate that an USNL model achieves higher prediction accuracy of missing data than an SNL model, as well as highly competitive computational efficiency.
Second-order Symmetric Non-negative Latent Factor Analysis
Mar 04, 2022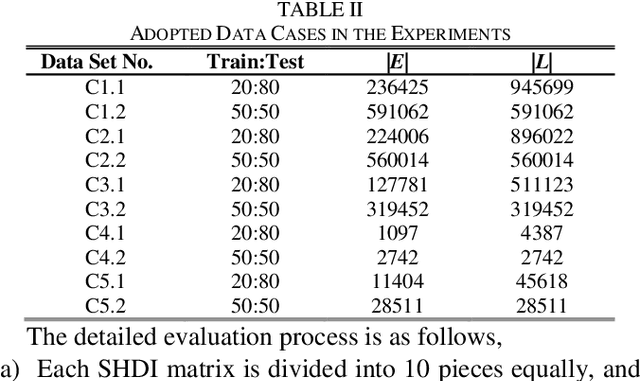
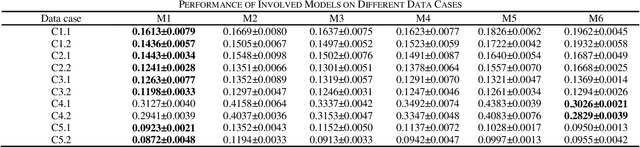
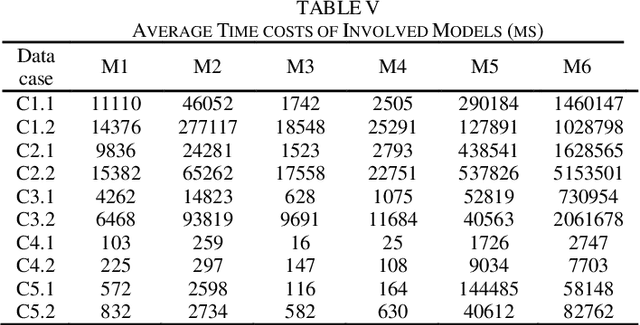
Precise representation of large-scale undirected network is the basis for understanding relations within a massive entity set. The undirected network representation task can be efficiently addressed by a symmetry non-negative latent factor (SNLF) model, whose objective is clearly non-convex. However, existing SNLF models commonly adopt a first-order optimizer that cannot well handle the non-convex objective, thereby resulting in inaccurate representation results. On the other hand, higher-order learning algorithms are expected to make a breakthrough, but their computation efficiency are greatly limited due to the direct manipulation of the Hessian matrix, which can be huge in undirected network representation tasks. Aiming at addressing this issue, this study proposes to incorporate an efficient second-order method into SNLF, thereby establishing a second-order symmetric non-negative latent factor analysis model for undirected network with two-fold ideas: a) incorporating a mapping strategy into SNLF model to form an unconstrained model, and b) training the unconstrained model with a specially designed second order method to acquire a proper second-order step efficiently. Empirical studies indicate that proposed model outperforms state-of-the-art models in representation accuracy with affordable computational burden.