 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-CAP: Benchmarking Cost, Accuracy and Performance of Sparse Mixture-of-Experts Systems
May 16, 2025The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently, but it depends on heterogeneous compute and memory resources. These factors jointly affect system Cost, Accuracy, and Performance (CAP), making trade-offs inevitable. Existing benchmarks often fail to capture these trade-offs accurately, complicating practical deployment decisions. To address this, we introduce MoE-CAP, a benchmark specifically designed for MoE systems. Our analysis reveals that achieving an optimal balance across CAP is difficult with current hardware; MoE systems typically optimize two of the three dimensions at the expense of the third-a dynamic we term the MoE-CAP trade-off. To visualize this, we propose the CAP Radar Diagram. We further introduce sparsity-aware performance metrics-Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU)-to enable accurate performance benchmarking of MoE systems across diverse hardware platforms and deployment scenarios.
BitDecoding: Unlocking Tensor Cores for Long-Context LLMs Decoding with Low-Bit KV Cache
Mar 24, 2025The growing adoption of long-context Large Language Models (LLMs) has introduced significant memory and computational challenges in autoregressive decoding due to the expanding Key-Value (KV) cache. KV cache quantization has emerged as a promising solution, with prior work showing that 4-bit or even 2-bit quantization can maintain model accuracy while reducing memory costs. However, despite these benefits, preliminary implementations for the low-bit KV cache struggle to deliver the expected speedup due to quantization and dequantization overheads and the lack of Tensor Cores utilization. In this work, we propose BitDecoding, a GPU-optimized framework that unlocks Tensor Cores for efficient decoding with low-bit KV cache. Efficiently leveraging Tensor Cores for low-bit KV cache is challenging due to the dynamic nature of KV cache generation at each decoding step. BitDecoding addresses these challenges with a Tensor Cores-Centric BitFusion Scheme that ensures data layout compatibility to enable high utilization of Tensor Cores. Additionally, BitDecoding incorporates a warp-efficient parallel decoding kernel and a fine-grained asynchronous pipeline, minimizing dequantization overhead and improving computational efficiency. Experiments show that BitDecoding achieves up to 7.5x speedup on RTX 4090, 4.8x on A100, and 8.9x on H100, compared to FP16 FlashDecoding-v2. It also outperforms the state-of-the-art low-bit KV cache implementation (QServe) by up to 4.3x. On LLaMA-3.1-8B with a 128K sequence length, BitDecoding reduces single-batch decoding latency by 3x, demonstrating its effectiveness in long-context generation scenarios. The code is available at https://github.com/DD-DuDa/BitDecoding.
SeerAttention: Learning Intrinsic Sparse Attention in Your LLMs
Oct 17, 2024



Attention is the cornerstone of modern Large Language Models (LLMs). Yet its quadratic complexity limits the efficiency and scalability of LLMs, especially for those with a long-context window. A promising approach addressing this limitation is to leverage the sparsity in attention. However, existing sparsity-based solutions predominantly rely on predefined patterns or heuristics to approximate sparsity. This practice falls short to fully capture the dynamic nature of attention sparsity in language-based tasks. This paper argues that attention sparsity should be learned rather than predefined. To this end, we design SeerAttention, a new Attention mechanism that augments the conventional attention with a learnable gate that adaptively selects significant blocks in an attention map and deems the rest blocks sparse. Such block-level sparsity effectively balances accuracy and speedup. To enable efficient learning of the gating network, we develop a customized FlashAttention implementation that extracts the block-level ground truth of attention map with minimum overhead. SeerAttention not only applies to post-training, but also excels in long-context fine-tuning. Our results show that at post-training stages, SeerAttention significantly outperforms state-of-the-art static or heuristic-based sparse attention methods, while also being more versatile and flexible to adapt to varying context lengths and sparsity ratios. When applied to long-context fine-tuning with YaRN, SeerAttention can achieve a remarkable 90% sparsity ratio at a 32k context length with minimal perplexity loss, offering a 5.67x speedup over FlashAttention-2.
STBLLM: Breaking the 1-Bit Barrier with Structured Binary LLMs
Aug 03, 2024



In this paper, we present STBLLM, the first structural binarization framework for compressing Large Language Models (LLMs) to less than 1-bit precision. LLMs have achieved remarkable performance, but their heavy memory requirements have hindered widespread adoption, particularly on resource-constrained devices. Binarization, which quantifies weights to a mere 1-bit, achieves a milestone in increasing computational efficiency. However, we observe that some weights in binarized LLMs can be randomly flipped without significant performance degradation, indicating the potential for further compression. To exploit this, our STBLLM employs an N:M sparsity to perform structural binarization of the weights. First, we introduce a new Standardized Importance (SI) metric that considers weight magnitude and input feature norm to better evaluate weight significance. Then, we propose a layer-wise approach where different layers of the LLM can be sparsified with varying N:M ratios, balancing compression and accuracy. Finally, we use residual approximation with double binarization to preserve information for salient weights. In addition, we utilize a fine-grained grouping strategy for less important weights that applies different quantization schemes to sparse, intermediate, and dense regions. We conduct extensive experiments on various language models, including the LLaMA-1/2/3, OPT family, and Mistral, to evaluate the effectiveness of STBLLM. The results demonstrate that our approach performs better than other compressed binarization LLM methods while significantly reducing memory requirements.
Model Quantization and Hardware Acceleration for Vision Transformers: A Comprehensive Survey
May 01, 2024



Vision Transformers (ViTs) have recently garnered considerable attention, emerging as a promising alternative to convolutional neural networks (CNNs) in several vision-related applications. However, their large model sizes and high computational and memory demands hinder deployment, especially on resource-constrained devices. This underscores the necessity of algorithm-hardware co-design specific to ViTs, aiming to optimize their performance by tailoring both the algorithmic structure and the underlying hardware accelerator to each other's strengths. Model quantization, by converting high-precision numbers to lower-precision, reduces the computational demands and memory needs of ViTs, allowing the creation of hardware specifically optimized for these quantized algorithms, boosting efficiency. This article provides a comprehensive survey of ViTs quantization and its hardware acceleration. We first delve into the unique architectural attributes of ViTs and their runtime characteristics. Subsequently, we examine the fundamental principles of model quantization, followed by a comparative analysis of the state-of-the-art quantization techniques for ViTs. Additionally, we explore the hardware acceleration of quantized ViTs, highlighting the importance of hardware-friendly algorithm design. In conclusion, this article will discuss ongoing challenges and future research paths. We consistently maintain the related open-source materials at https://github.com/DD-DuDa/awesome-vit-quantization-acceleration.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
BitDistiller: Unleashing the Potential of Sub-4-Bit LLMs via Self-Distillation
Feb 16, 2024The upscaling of Large Language Models (LLMs) has yielded impressive advances in natural language processing, yet it also poses significant deployment challenges. Weight quantization has emerged as a widely embraced solution to reduce memory and computational demands. This paper introduces BitDistiller, a framework that synergizes Quantization-Aware Training (QAT) with Knowledge Distillation (KD) to boost the performance of LLMs at ultra-low precisions (sub-4-bit). Specifically, BitDistiller first incorporates a tailored asymmetric quantization and clipping technique to maximally preserve the fidelity of quantized weights, and then proposes a novel Confidence-Aware Kullback-Leibler Divergence (CAKLD) objective, which is employed in a self-distillation manner to enable faster convergence and superior model performance. Empirical evaluations demonstrate that BitDistiller significantly surpasses existing methods in both 3-bit and 2-bit configurations on general language understanding and complex reasoning benchmarks. Notably, BitDistiller is shown to be more cost-effective, demanding fewer data and training resources. The code is available at https://github.com/DD-DuDa/BitDistiller.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
AFPQ: Asymmetric Floating Point Quantization for LLMs
Nov 03, 2023
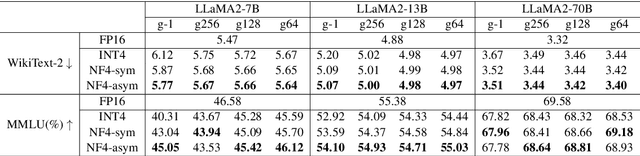


Large language models (LLMs) show great performance in various tasks, but face deployment challenges from limited memory capacity and bandwidth. Low-bit weight quantization can save memory and accelerate inference. Although floating-point (FP) formats show good performance in LLM quantization, they tend to perform poorly with small group sizes or sub-4 bits. We find the reason is that the absence of asymmetry in previous FP quantization makes it unsuitable for handling asymmetric value distribution of LLM weight tensors. In this work, we propose asymmetric FP quantization (AFPQ), which sets separate scales for positive and negative values. Our method leads to large accuracy improvements and can be easily plugged into other quantization methods, including GPTQ and AWQ, for better performance. Besides, no additional storage is needed compared with asymmetric integer (INT) quantization. The code is available at https://github.com/zhangsichengsjtu/AFPQ.