 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFPQ: Asymmetric Floating Point Quantization for LLMs
Paper and Code

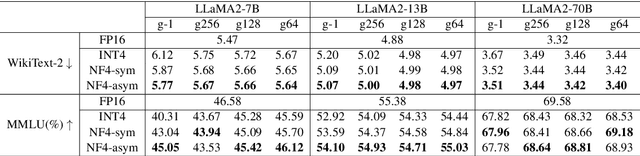


Large language models (LLMs) show great performance in various tasks, but face deployment challenges from limited memory capacity and bandwidth. Low-bit weight quantization can save memory and accelerate inference. Although floating-point (FP) formats show good performance in LLM quantization, they tend to perform poorly with small group sizes or sub-4 bits. We find the reason is that the absence of asymmetry in previous FP quantization makes it unsuitable for handling asymmetric value distribution of LLM weight tensors. In this work, we propose asymmetric FP quantization (AFPQ), which sets separate scales for positive and negative values. Our method leads to large accuracy improvements and can be easily plugged into other quantization methods, including GPTQ and AWQ, for better performance. Besides, no additional storage is needed compared with asymmetric integer (INT) quantization. The code is available at https://github.com/zhangsichengsjtu/AFPQ.