 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA pilot protocol and cohort for the investigation of non-pathological variability in speech
Jun 11, 2024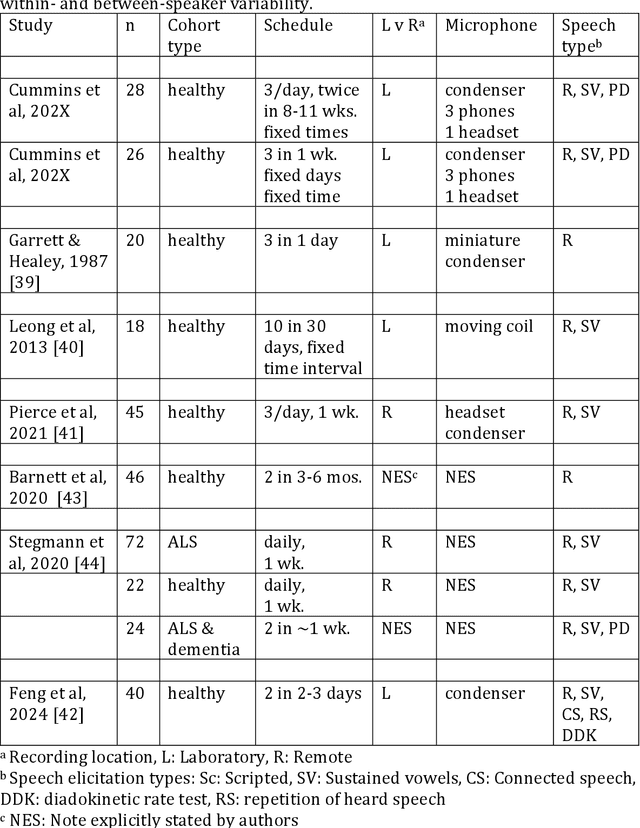
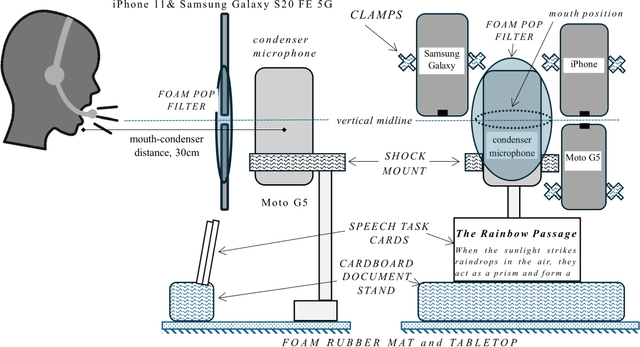
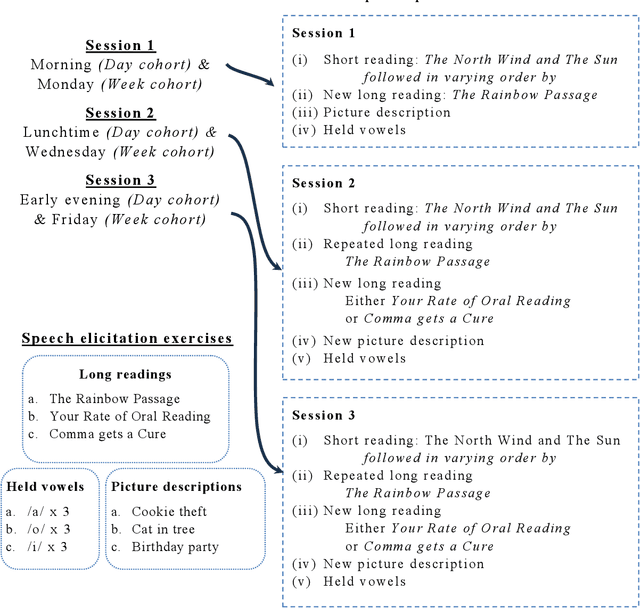

Background Speech-based biomarkers have potential as a means for regular, objective assessment of symptom severity, remotely and in-clinic in combination with advanced analytical models. However, the complex nature of speech and the often subtle changes associated with health mean that findings are highly dependent on methodological and cohort choices. These are often not reported adequately in studies investigating speech-based health assessment Objective To develop and apply an exemplar protocol to generate a pilot dataset of healthy speech with detailed metadata for the assessment of factors in the speech recording-analysis pipeline, including device choice, speech elicitation task and non-pathological variability. Methods We developed our collection protocol and choice of exemplar speech features based on a thematic literature review. Our protocol includes the elicitation of three different speech types. With a focus towards remote applications, we also choose to collect speech with three different microphone types. We developed a pipeline to extract a set of 14 exemplar speech features. Results We collected speech from 28 individuals three times in one day, repeated at the same times 8-11 weeks later, and from 25 healthy individuals three times in one week. Participant characteristics collected included sex, age, native language status and voice use habits of the participant. A preliminary set of 14 speech features covering timing, prosody, voice quality, articulation and spectral moment characteristics were extracted that provide a resource of normative values. Conclusions There are multiple methodological factors involved in the collection, processing and analysis of speech recordings. Consistent reporting and greater harmonisation of study protocols are urgently required to aid the translation of speech processing into clinical research and practice.
Towards robust paralinguistic assessment for real-world mobile health (mHealth) monitoring: an initial study of reverberation effects on speech
May 21, 2023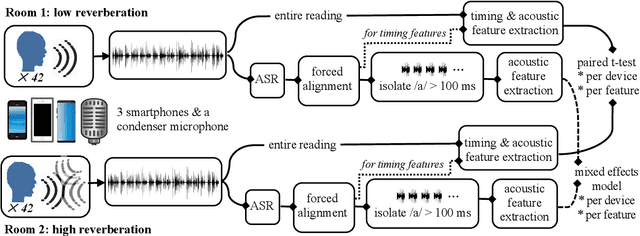

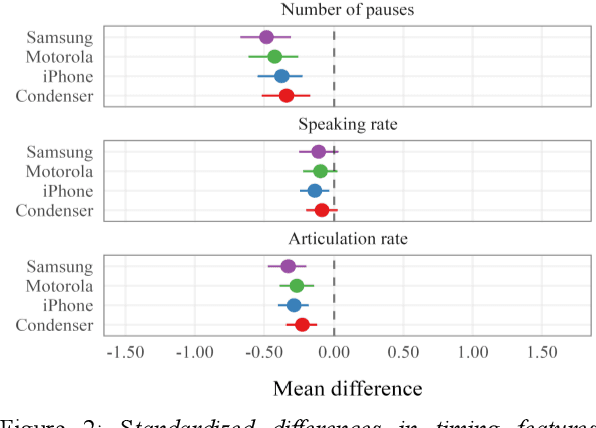
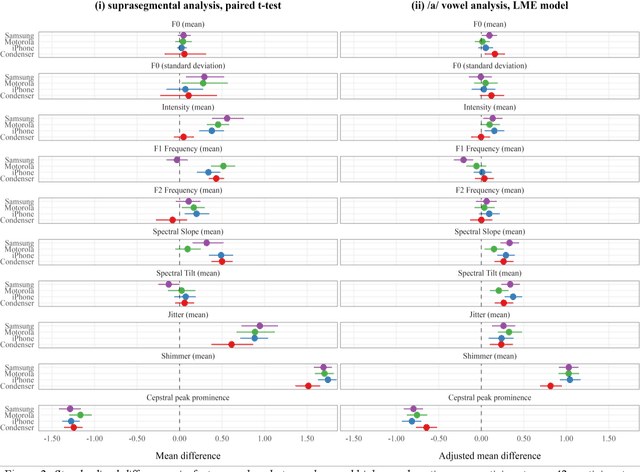
Speech is promising as an objective, convenient tool to monitor health remotely over time using mobile devices. Numerous paralinguistic features have been demonstrated to contain salient information related to an individual's health. However, mobile device specification and acoustic environments vary widely, risking the reliability of the extracted features. In an initial step towards quantifying these effects, we report the variability of 13 exemplar paralinguistic features commonly reported in the speech-health literature and extracted from the speech of 42 healthy volunteers recorded consecutively in rooms with low and high reverberation with one budget and two higher-end smartphones and a condenser microphone. Our results show reverberation has a clear effect on several features, in particular voice quality markers. They point to new research directions investigating how best to record and process in-the-wild speech for reliable longitudinal health state assessment.
Automatic Detection of Expressed Emotion from Five-Minute Speech Samples: Challenges and Opportunities
Mar 30, 2022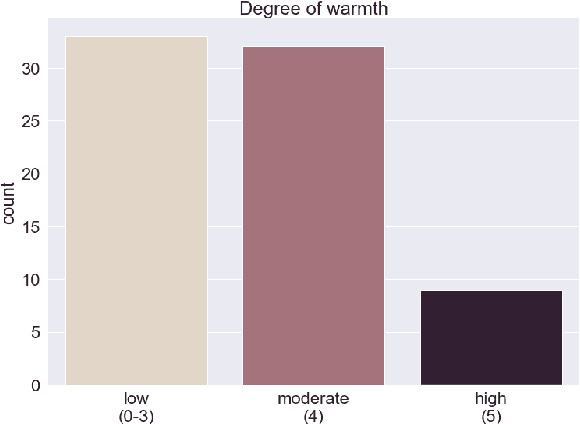
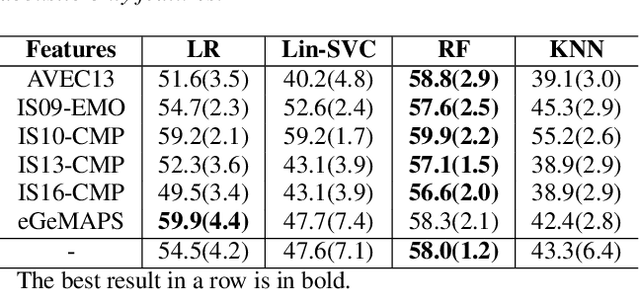
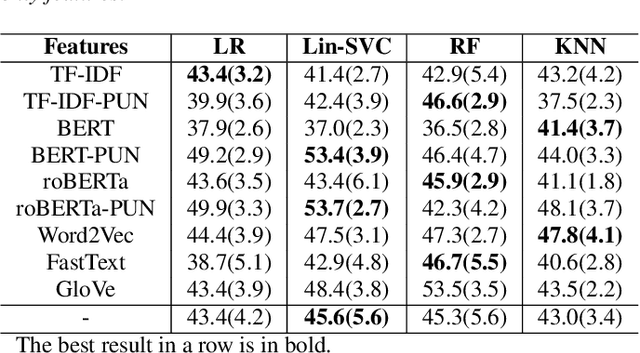
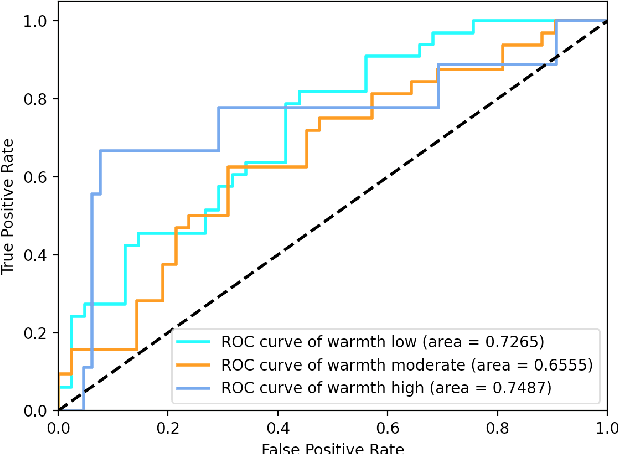
We present a novel feasibility study on the automatic recognition of Expressed Emotion (EE), a family environment concept based on caregivers speaking freely about their relative/family member. We describe an automated approach for determining the \textit{degree of warmth}, a key component of EE, from acoustic and text features acquired from a sample of 37 recorded interviews. These recordings, collected over 20 years ago, are derived from a nationally representative birth cohort of 2,232 British twin children and were manually coded for EE. We outline the core steps of extracting usable information from recordings with highly variable audio quality and assess the efficacy of four machine learning approaches trained with different combinations of acoustic and text features. Despite the challenges of working with this legacy data, we demonstrated that the degree of warmth can be predicted with an $F_{1}$-score of \textbf{61.5\%}. In this paper, we summarise our learning and provide recommendations for future work using real-world speech samples.