 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Medical Forecasting -- Foresight 2
Dec 14, 2024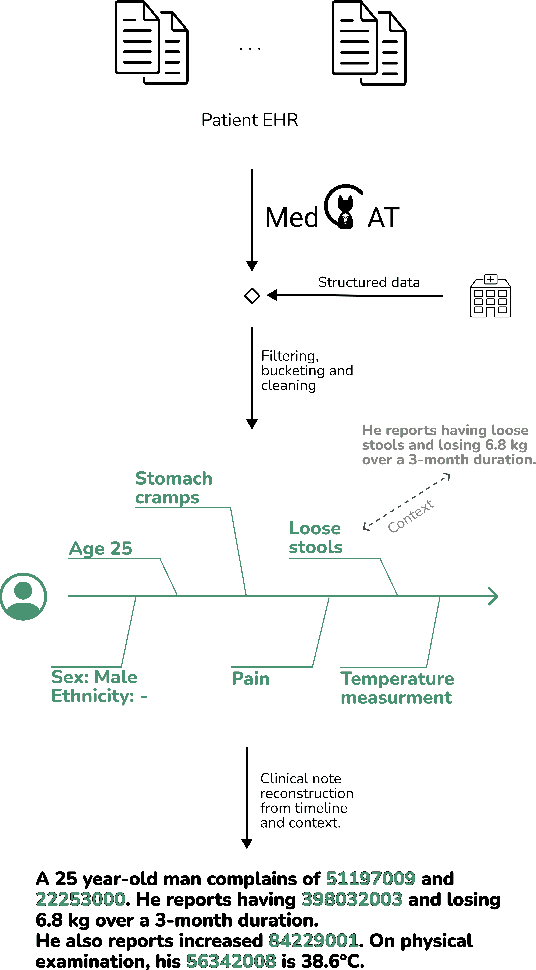
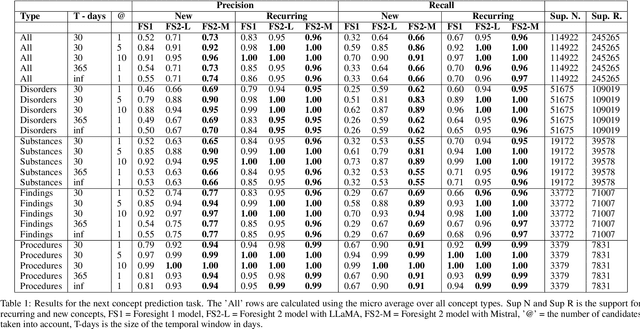
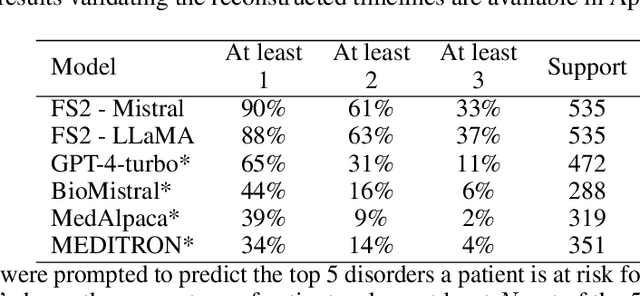
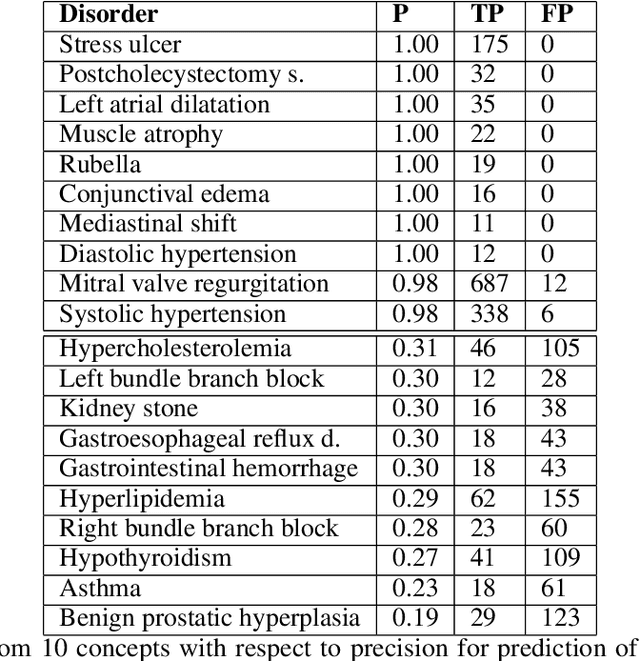
Foresight 2 (FS2) is a large language model fine-tuned on hospital data for modelling patient timelines (GitHub 'removed for anon'). It can understand patients' clinical notes and predict SNOMED codes for a wide range of biomedical use cases, including diagnosis suggestions, risk forecasting, and procedure and medication recommendations. FS2 is trained on the free text portion of the MIMIC-III dataset, firstly through extracting biomedical concepts and then creating contextualised patient timelines, upon which the model is then fine-tuned. The results show significant improvement over the previous state-of-the-art for the next new biomedical concept prediction (P/R - 0.73/0.66 vs 0.52/0.32) and a similar improvement specifically for the next new disorder prediction (P/R - 0.69/0.62 vs 0.46/0.25). Finally, on the task of risk forecast, we compare our model to GPT-4-turbo (and a range of open-source biomedical LLMs) and show that FS2 performs significantly better on such tasks (P@5 - 0.90 vs 0.65). This highlights the need to incorporate hospital data into LLMs and shows that small models outperform much larger ones when fine-tuned on high-quality, specialised data.
A pilot protocol and cohort for the investigation of non-pathological variability in speech
Jun 11, 2024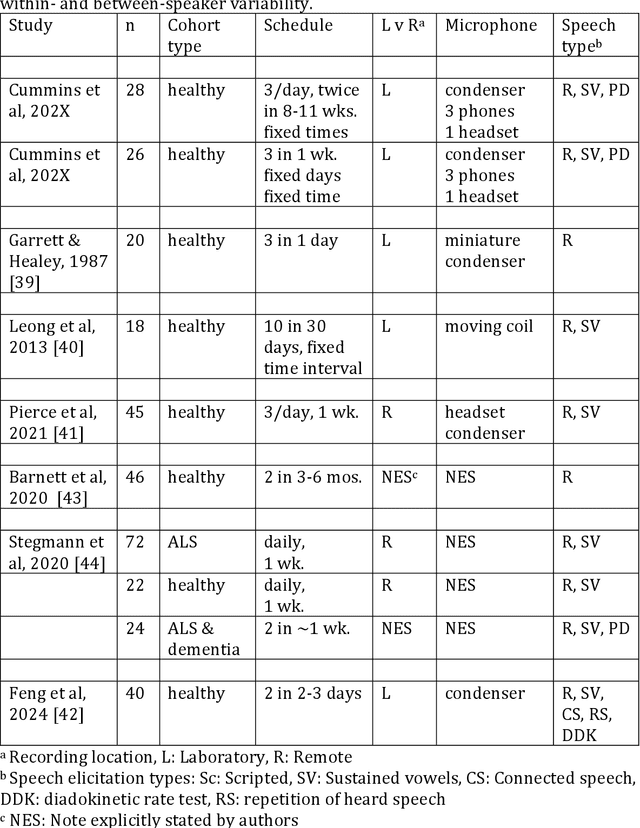
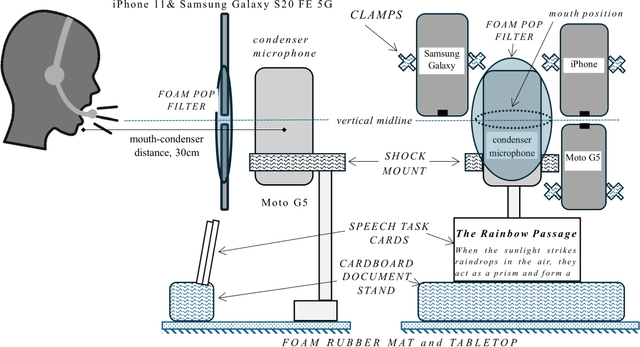
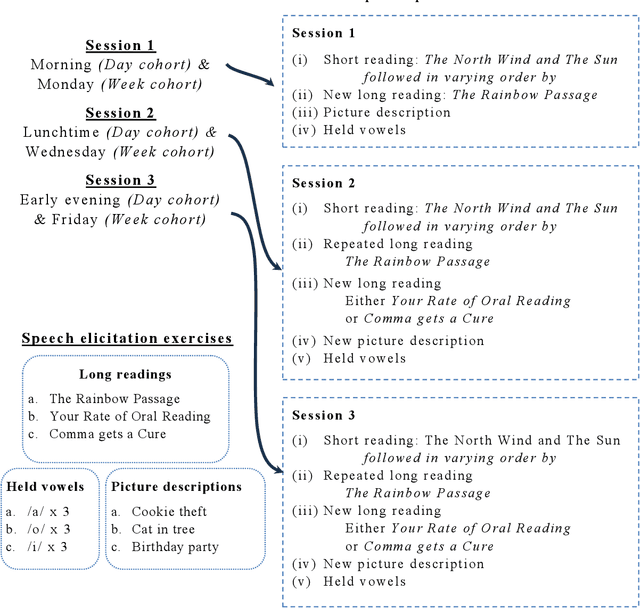

Background Speech-based biomarkers have potential as a means for regular, objective assessment of symptom severity, remotely and in-clinic in combination with advanced analytical models. However, the complex nature of speech and the often subtle changes associated with health mean that findings are highly dependent on methodological and cohort choices. These are often not reported adequately in studies investigating speech-based health assessment Objective To develop and apply an exemplar protocol to generate a pilot dataset of healthy speech with detailed metadata for the assessment of factors in the speech recording-analysis pipeline, including device choice, speech elicitation task and non-pathological variability. Methods We developed our collection protocol and choice of exemplar speech features based on a thematic literature review. Our protocol includes the elicitation of three different speech types. With a focus towards remote applications, we also choose to collect speech with three different microphone types. We developed a pipeline to extract a set of 14 exemplar speech features. Results We collected speech from 28 individuals three times in one day, repeated at the same times 8-11 weeks later, and from 25 healthy individuals three times in one week. Participant characteristics collected included sex, age, native language status and voice use habits of the participant. A preliminary set of 14 speech features covering timing, prosody, voice quality, articulation and spectral moment characteristics were extracted that provide a resource of normative values. Conclusions There are multiple methodological factors involved in the collection, processing and analysis of speech recordings. Consistent reporting and greater harmonisation of study protocols are urgently required to aid the translation of speech processing into clinical research and practice.