 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA pilot protocol and cohort for the investigation of non-pathological variability in speech
Jun 11, 2024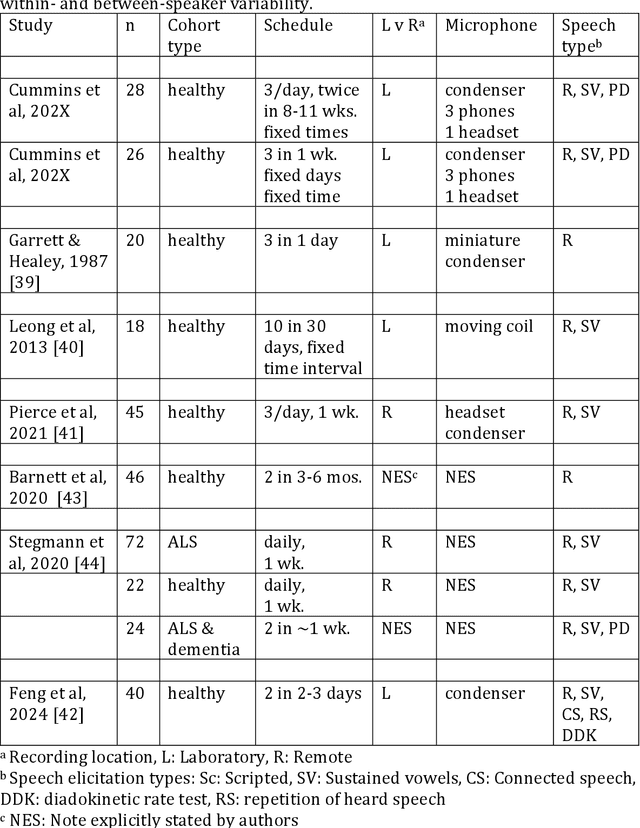
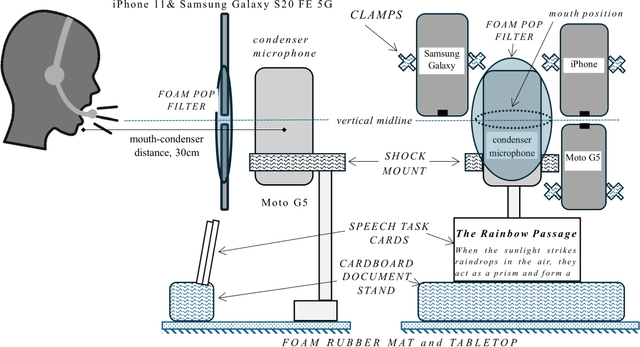
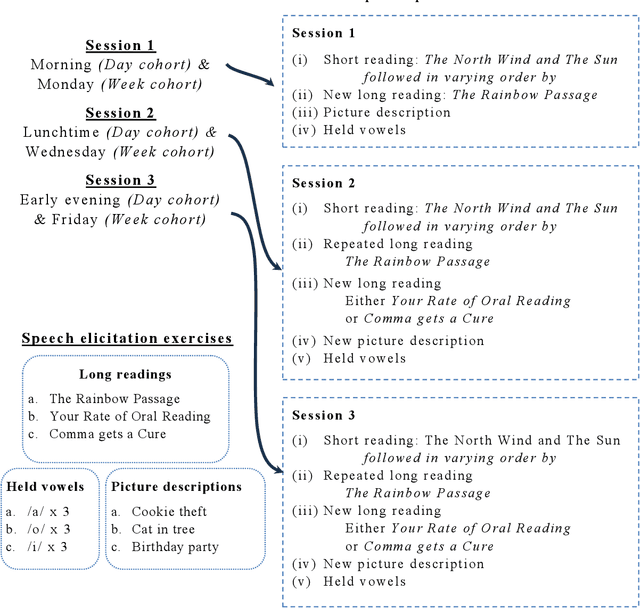

Background Speech-based biomarkers have potential as a means for regular, objective assessment of symptom severity, remotely and in-clinic in combination with advanced analytical models. However, the complex nature of speech and the often subtle changes associated with health mean that findings are highly dependent on methodological and cohort choices. These are often not reported adequately in studies investigating speech-based health assessment Objective To develop and apply an exemplar protocol to generate a pilot dataset of healthy speech with detailed metadata for the assessment of factors in the speech recording-analysis pipeline, including device choice, speech elicitation task and non-pathological variability. Methods We developed our collection protocol and choice of exemplar speech features based on a thematic literature review. Our protocol includes the elicitation of three different speech types. With a focus towards remote applications, we also choose to collect speech with three different microphone types. We developed a pipeline to extract a set of 14 exemplar speech features. Results We collected speech from 28 individuals three times in one day, repeated at the same times 8-11 weeks later, and from 25 healthy individuals three times in one week. Participant characteristics collected included sex, age, native language status and voice use habits of the participant. A preliminary set of 14 speech features covering timing, prosody, voice quality, articulation and spectral moment characteristics were extracted that provide a resource of normative values. Conclusions There are multiple methodological factors involved in the collection, processing and analysis of speech recordings. Consistent reporting and greater harmonisation of study protocols are urgently required to aid the translation of speech processing into clinical research and practice.
VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples
Mar 17, 2021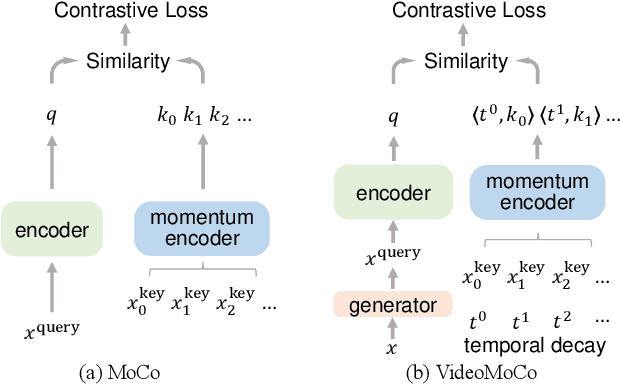
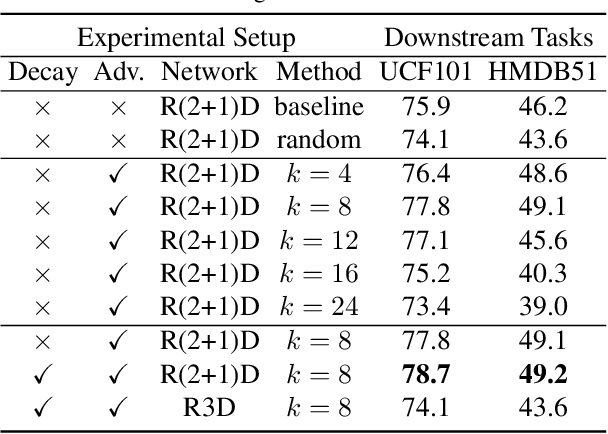

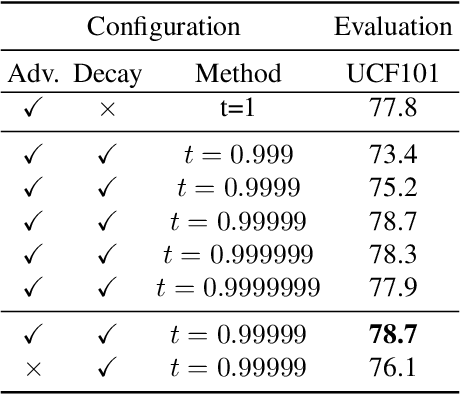
MoCo is effective for unsupervised image representation learning. In this paper, we propose VideoMoCo for unsupervised video representation learning. Given a video sequence as an input sample, we improve the temporal feature representations of MoCo from two perspectives. First, we introduce a generator to drop out several frames from this sample temporally. The discriminator is then learned to encode similar feature representations regardless of frame removals. By adaptively dropping out different frames during training iterations of adversarial learning, we augment this input sample to train a temporally robust encoder. Second, we use temporal decay to model key attenuation in the memory queue when computing the contrastive loss. As the momentum encoder updates after keys enqueue, the representation ability of these keys degrades when we use the current input sample for contrastive learning. This degradation is reflected via temporal decay to attend the input sample to recent keys in the queue. As a result, we adapt MoCo to learn video representations without empirically designing pretext tasks. By empowering the temporal robustness of the encoder and modeling the temporal decay of the keys, our VideoMoCo improves MoCo temporally based on contrastive learning. Experiments on benchmark datasets including UCF101 and HMDB51 show that VideoMoCo stands as a state-of-the-art video representation learning method.