 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiTaskGen: A Comprehensive Task Generator for Benchmarking and Improving Vision-Language Agents on Embodied Decision-Making
May 27, 2025Building embodied agents capable of accomplishing arbitrary tasks is a core objective towards achieving embodied artificial general intelligence (E-AGI). While recent work has advanced such general robot policies, their training and evaluation are often limited to tasks within specific scenes, involving restricted instructions and scenarios. Existing benchmarks also typically rely on manual annotation of limited tasks in a few scenes. We argue that exploring the full spectrum of feasible tasks within any given scene is crucial, as they provide both extensive benchmarks for evaluation and valuable resources for agent improvement. Towards this end, we introduce ManiTaskGen, a novel system that automatically generates comprehensive, diverse, feasible mobile manipulation tasks for any given scene. The generated tasks encompass both process-based, specific instructions (e.g., "move object from X to Y") and outcome-based, abstract instructions (e.g., "clear the table"). We apply ManiTaskGen to both simulated and real-world scenes, demonstrating the validity and diversity of the generated tasks. We then leverage these tasks to automatically construct benchmarks, thoroughly evaluating the embodied decision-making capabilities of agents built upon existing vision-language models (VLMs). Furthermore, we propose a simple yet effective method that utilizes ManiTaskGen tasks to enhance embodied decision-making. Overall, this work presents a universal task generation framework for arbitrary scenes, facilitating both benchmarking and improvement of embodied decision-making agents.
Towards Embodiment Scaling Laws in Robot Locomotion
May 09, 2025Developing generalist agents that can operate across diverse tasks, environments, and physical embodiments is a grand challenge in robotics and artificial intelligence. In this work, we focus on the axis of embodiment and investigate embodiment scaling laws$\unicode{x2013}$the hypothesis that increasing the number of training embodiments improves generalization to unseen ones. Using robot locomotion as a test bed, we procedurally generate a dataset of $\sim$1,000 varied embodiments, spanning humanoids, quadrupeds, and hexapods, and train generalist policies capable of handling diverse observation and action spaces on random subsets. We find that increasing the number of training embodiments improves generalization to unseen ones, and scaling embodiments is more effective in enabling embodiment-level generalization than scaling data on small, fixed sets of embodiments. Notably, our best policy, trained on the full dataset, zero-shot transfers to novel embodiments in the real world, such as Unitree Go2 and H1. These results represent a step toward general embodied intelligence, with potential relevance to adaptive control for configurable robots, co-design of morphology and control, and beyond.
GAMMA: Graspability-Aware Mobile MAnipulation Policy Learning based on Online Grasping Pose Fusion
Sep 27, 2023



Mobile manipulation constitutes a fundamental task for robotic assistants and garners significant attention within the robotics community. A critical challenge inherent in mobile manipulation is the effective observation of the target while approaching it for grasping. In this work, we propose a graspability-aware mobile manipulation approach powered by an online grasping pose fusion framework that enables a temporally consistent grasping observation. Specifically, the predicted grasping poses are online organized to eliminate the redundant, outlier grasping poses, which can be encoded as a grasping pose observation state for reinforcement learning. Moreover, on-the-fly fusing the grasping poses enables a direct assessment of graspability, encompassing both the quantity and quality of grasping poses.
3D-Aware Object Goal Navigation via Simultaneous Exploration and Identification
Dec 01, 2022


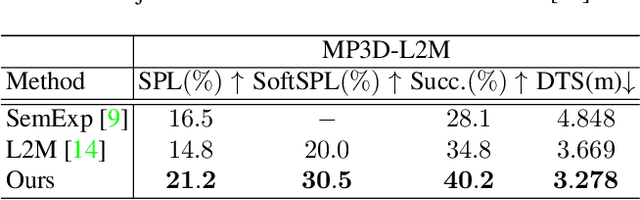
Object goal navigation (ObjectNav) in unseen environments is a fundamental task for Embodied AI. Agents in existing works learn ObjectNav policies based on 2D maps, scene graphs, or image sequences. Considering this task happens in 3D space, a 3D-aware agent can advance its ObjectNav capability via learning from fine-grained spatial information. However, leveraging 3D scene representation can be prohibitively unpractical for policy learning in this floor-level task, due to low sample efficiency and expensive computational cost. In this work, we propose a framework for the challenging 3D-aware ObjectNav based on two straightforward sub-policies. The two sub-polices, namely corner-guided exploration policy and category-aware identification policy, simultaneously perform by utilizing online fused 3D points as observation. Through extensive experiments, we show that this framework can dramatically improve the performance in ObjectNav through learning from 3D scene representation. Our framework achieves the best performance among all modular-based methods on the Matterport3D and Gibson datasets, while requiring (up to 30x) less computational cost for training.