 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Learning: A Retrial-based Large Language Model Self-Supervised Learning and Autonomous Knowledge Generation
May 02, 2025The lack of domain-specific data in the pre-training of Large Language Models (LLMs) severely limits LLM-based decision systems in specialized applications, while post-training a model in the scenarios requires significant computational resources. In this paper, we present Retrial-Augmented Learning (RAL), a reward-free self-supervised learning framework for LLMs that operates without model training. By developing Retrieval-Augmented Generation (RAG) into a module for organizing intermediate data, we realized a three-stage autonomous knowledge generation of proposing a hypothesis, validating the hypothesis, and generating the knowledge. The method is evaluated in the LLM-PySC2 environment, a representative decision-making platform that combines sufficient complexity with domain-specific knowledge requirements. Experiments demonstrate that the proposed method effectively reduces hallucination by generating and utilizing validated knowledge, and increases decision-making performance at an extremely low cost. Meanwhile, the approach exhibits potential in out-of-distribution(OOD) tasks, robustness, and transferability, making it a cost-friendly but effective solution for decision-making problems and autonomous knowledge generation.
Reflection of Episodes: Learning to Play Game from Expert and Self Experiences
Feb 19, 2025

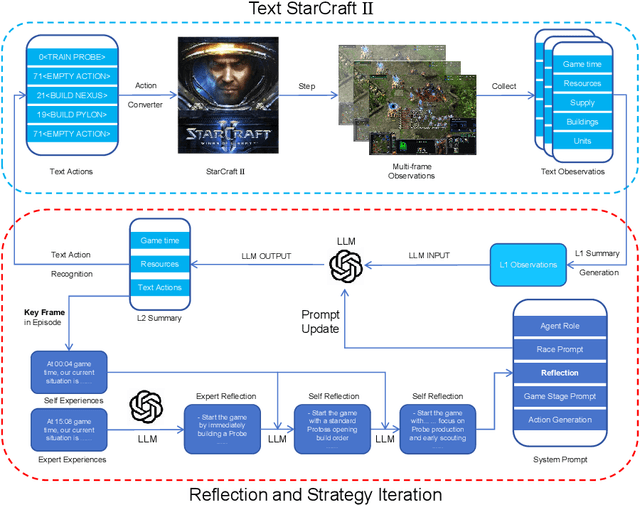

StarCraft II is a complex and dynamic real-time strategy (RTS) game environment, which is very suitable for artificial intelligence and reinforcement learning research. To address the problem of Large Language Model(LLM) learning in complex environments through self-reflection, we propose a Reflection of Episodes(ROE) framework based on expert experience and self-experience. This framework first obtains key information in the game through a keyframe selection method, then makes decisions based on expert experience and self-experience. After a game is completed, it reflects on the previous experience to obtain new self-experience. Finally, in the experiment, our method beat the robot under the Very Hard difficulty in TextStarCraft II. We analyze the data of the LLM in the process of the game in detail, verified its effectiveness.
LLM-PySC2: Starcraft II learning environment for Large Language Models
Nov 08, 2024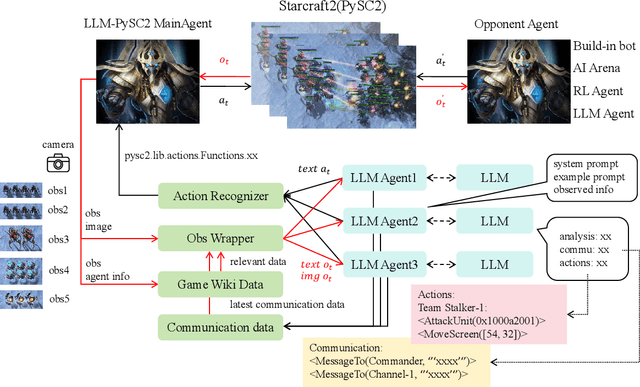
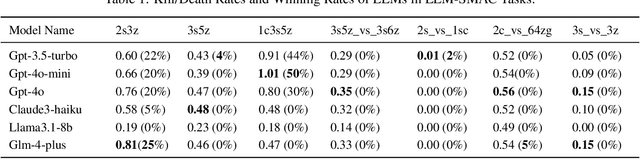
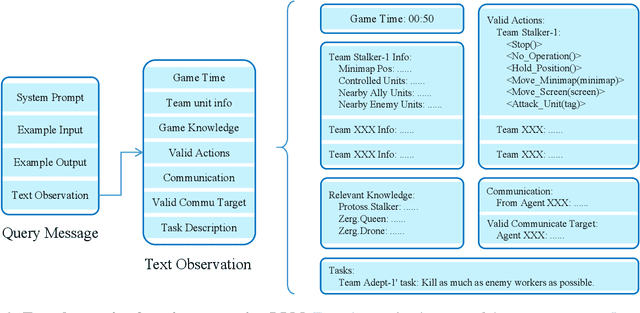

This paper introduces a new environment LLM-PySC2 (the Large Language Model StarCraft II Learning Environment), a platform derived from DeepMind's StarCraft II Learning Environment that serves to develop Large Language Models (LLMs) based decision-making methodologies. This environment is the first to offer the complete StarCraft II action space, multi-modal observation interfaces, and a structured game knowledge database, which are seamlessly connected with various LLMs to facilitate the research of LLMs-based decision-making. To further support multi-agent research, we developed an LLM collaborative framework that supports multi-agent concurrent queries and multi-agent communication. In our experiments, the LLM-PySC2 environment is adapted to be compatible with the StarCraft Multi-Agent Challenge (SMAC) task group and provided eight new scenarios focused on macro-decision abilities. We evaluated nine mainstream LLMs in the experiments, and results show that sufficient parameters are necessary for LLMs to make decisions, but improving reasoning ability does not directly lead to better decision-making outcomes. Our findings further indicate the importance of enabling large models to learn autonomously in the deployment environment through parameter training or train-free learning techniques. Ultimately, we expect that the LLM-PySC2 environment can promote research on learning methods for LLMs, helping LLM-based methods better adapt to task scenarios.