 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA foundation model for human-AI collaboration in medical literature mining
Jan 27, 2025



Systematic literature review is essential for evidence-based medicine, requiring comprehensive analysis of clinical trial publications. However, the application of artificial intelligence (AI) models for medical literature mining has been limited by insufficient training and evaluation across broad therapeutic areas and diverse tasks. Here, we present LEADS, an AI foundation model for study search, screening, and data extraction from medical literature. The model is trained on 633,759 instruction data points in LEADSInstruct, curated from 21,335 systematic reviews, 453,625 clinical trial publications, and 27,015 clinical trial registries. We showed that LEADS demonstrates consistent improvements over four cutting-edge generic large language models (LLMs) on six tasks. Furthermore, LEADS enhances expert workflows by providing supportive references following expert requests, streamlining processes while maintaining high-quality results. A study with 16 clinicians and medical researchers from 14 different institutions revealed that experts collaborating with LEADS achieved a recall of 0.81 compared to 0.77 experts working alone in study selection, with a time savings of 22.6%. In data extraction tasks, experts using LEADS achieved an accuracy of 0.85 versus 0.80 without using LEADS, alongside a 26.9% time savings. These findings highlight the potential of specialized medical literature foundation models to outperform generic models, delivering significant quality and efficiency benefits when integrated into expert workflows for medical literature mining.
SDoH-GPT: Using Large Language Models to Extract Social Determinants of Health (SDoH)
Jul 24, 2024



Extracting social determinants of health (SDoH) from unstructured medical notes depends heavily on labor-intensive annotations, which are typically task-specific, hampering reusability and limiting sharing. In this study we introduced SDoH-GPT, a simple and effective few-shot Large Language Model (LLM) method leveraging contrastive examples and concise instructions to extract SDoH without relying on extensive medical annotations or costly human intervention. It achieved tenfold and twentyfold reductions in time and cost respectively, and superior consistency with human annotators measured by Cohen's kappa of up to 0.92. The innovative combination of SDoH-GPT and XGBoost leverages the strengths of both, ensuring high accuracy and computational efficiency while consistently maintaining 0.90+ AUROC scores. Testing across three distinct datasets has confirmed its robustness and accuracy. This study highlights the potential of leveraging LLMs to revolutionize medical note classification, demonstrating their capability to achieve highly accurate classifications with significantly reduced time and cost.
RadBERT-CL: Factually-Aware Contrastive Learning For Radiology Report Classification
Nov 19, 2021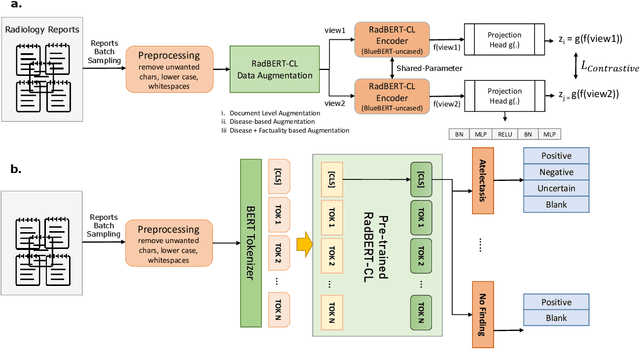
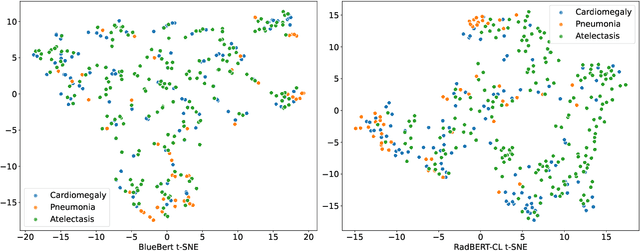

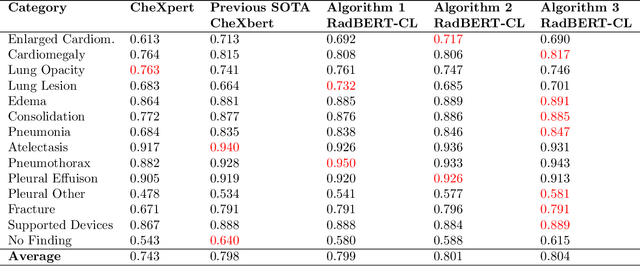
Radiology reports are unstructured and contain the imaging findings and corresponding diagnoses transcribed by radiologists which include clinical facts and negated and/or uncertain statements. Extracting pathologic findings and diagnoses from radiology reports is important for quality control, population health, and monitoring of disease progress. Existing works, primarily rely either on rule-based systems or transformer-based pre-trained model fine-tuning, but could not take the factual and uncertain information into consideration, and therefore generate false-positive outputs. In this work, we introduce three sedulous augmentation techniques which retain factual and critical information while generating augmentations for contrastive learning. We introduce RadBERT-CL, which fuses these information into BlueBert via a self-supervised contrastive loss. Our experiments on MIMIC-CXR show superior performance of RadBERT-CL on fine-tuning for multi-class, multi-label report classification. We illustrate that when few labeled data are available, RadBERT-CL outperforms conventional SOTA transformers (BERT/BlueBert) by significantly larger margins (6-11%). We also show that the representations learned by RadBERT-CL can capture critical medical information in the latent space.