 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSyn: Autonomously Scaling Synthetic Environments for Reasoning Models
Feb 23, 2026Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising approach for training reasoning language models (RLMs) by leveraging supervision from verifiers. Although verifier implementation is easier than solution annotation for many tasks, existing synthetic data generation methods remain largely solution-centric, while verifier-based methods rely on a few hand-crafted procedural environments. In this work, we scale RLVR by introducing ReSyn, a pipeline that generates diverse reasoning environments equipped with instance generators and verifiers, covering tasks such as constraint satisfaction, algorithmic puzzles, and spatial reasoning. A Qwen2.5-7B-Instruct model trained with RL on ReSyn data achieves consistent gains across reasoning benchmarks and out-of-domain math benchmarks, including a 27\% relative improvement on the challenging BBEH benchmark. Ablations show that verifier-based supervision and increased task diversity both contribute significantly, providing empirical evidence that generating reasoning environments at scale can enhance reasoning abilities in RLMs
Generating Data-Driven Reasoning Rubrics for Domain-Adaptive Reward Modeling
Feb 06, 2026An impediment to using Large Language Models (LLMs) for reasoning output verification is that LLMs struggle to reliably identify errors in thinking traces, particularly in long outputs, domains requiring expert knowledge, and problems without verifiable rewards. We propose a data-driven approach to automatically construct highly granular reasoning error taxonomies to enhance LLM-driven error detection on unseen reasoning traces. Our findings indicate that classification approaches that leverage these error taxonomies, or "rubrics", demonstrate strong error identification compared to baseline methods in technical domains like coding, math, and chemical engineering. These rubrics can be used to build stronger LLM-as-judge reward functions for reasoning model training via reinforcement learning. Experimental results show that these rewards have the potential to improve models' task accuracy on difficult domains over models trained by general LLMs-as-judges by +45%, and approach performance of models trained by verifiable rewards while using as little as 20% as many gold labels. Through our approach, we extend the usage of reward rubrics from assessing qualitative model behavior to assessing quantitative model correctness on tasks typically learned via RLVR rewards. This extension opens the door for teaching models to solve complex technical problems without a full dataset of gold labels, which are often highly costly to procure.
VeriCoT: Neuro-symbolic Chain-of-Thought Validation via Logical Consistency Checks
Nov 06, 2025



LLMs can perform multi-step reasoning through Chain-of-Thought (CoT), but they cannot reliably verify their own logic. Even when they reach correct answers, the underlying reasoning may be flawed, undermining trust in high-stakes scenarios. To mitigate this issue, we introduce VeriCoT, a neuro-symbolic method that extracts and verifies formal logical arguments from CoT reasoning. VeriCoT formalizes each CoT reasoning step into first-order logic and identifies premises that ground the argument in source context, commonsense knowledge, or prior reasoning steps. The symbolic representation enables automated solvers to verify logical validity while the NL premises allow humans and systems to identify ungrounded or fallacious reasoning steps. Experiments on the ProofWriter, LegalBench, and BioASQ datasets show VeriCoT effectively identifies flawed reasoning, and serves as a strong predictor of final answer correctness. We also leverage VeriCoT's verification signal for (1) inference-time self-reflection, (2) supervised fine-tuning (SFT) on VeriCoT-distilled datasets and (3) preference fine-tuning (PFT) with direct preference optimization (DPO) using verification-based pairwise rewards, further improving reasoning validity and accuracy.
Lil-Bevo: Explorations of Strategies for Training Language Models in More Humanlike Ways
Oct 26, 2023



We present Lil-Bevo, our submission to the BabyLM Challenge. We pretrained our masked language models with three ingredients: an initial pretraining with music data, training on shorter sequences before training on longer ones, and masking specific tokens to target some of the BLiMP subtasks. Overall, our baseline models performed above chance, but far below the performance levels of larger LLMs trained on more data. We found that training on short sequences performed better than training on longer sequences.Pretraining on music may help performance marginally, but, if so, the effect seems small. Our targeted Masked Language Modeling augmentation did not seem to improve model performance in general, but did seem to help on some of the specific BLiMP tasks that we were targeting (e.g., Negative Polarity Items). Training performant LLMs on small amounts of data is a difficult but potentially informative task. While some of our techniques showed some promise, more work is needed to explore whether they can improve performance more than the modest gains here. Our code is available at https://github.com/venkatasg/Lil-Bevo and out models at https://huggingface.co/collections/venkatasg/babylm-653591cdb66f4bf68922873a
MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning
Oct 24, 2023



While large language models (LLMs) equipped with techniques like chain-of-thought prompting have demonstrated impressive capabilities, they still fall short in their ability to reason robustly in complex settings. However, evaluating LLM reasoning is challenging because system capabilities continue to grow while benchmark datasets for tasks like logical deduction have remained static. We introduce MuSR, a dataset for evaluating language models on multistep soft reasoning tasks specified in a natural language narrative. This dataset has two crucial features. First, it is created through a novel neurosymbolic synthetic-to-natural generation algorithm, enabling the construction of complex reasoning instances that challenge GPT-4 (e.g., murder mysteries roughly 1000 words in length) and which can be scaled further as more capable LLMs are released. Second, our dataset instances are free text narratives corresponding to real-world domains of reasoning; this makes it simultaneously much more challenging than other synthetically-crafted benchmarks while remaining realistic and tractable for human annotators to solve with high accuracy. We evaluate a range of LLMs and prompting techniques on this dataset and characterize the gaps that remain for techniques like chain-of-thought to perform robust reasoning.
Deductive Additivity for Planning of Natural Language Proofs
Jul 06, 2023

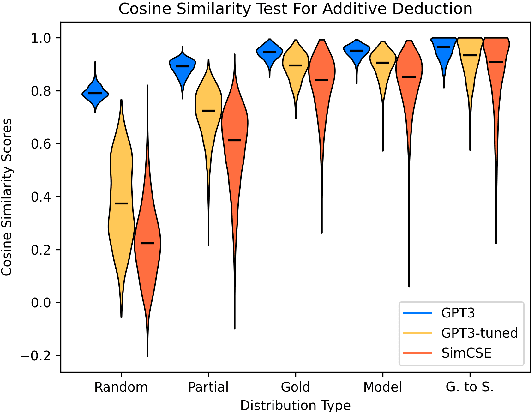
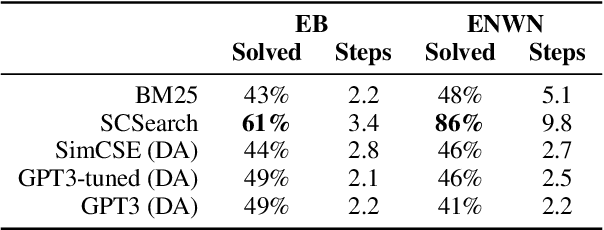
Current natural language systems designed for multi-step claim validation typically operate in two phases: retrieve a set of relevant premise statements using heuristics (planning), then generate novel conclusions from those statements using a large language model (deduction). The planning step often requires expensive Transformer operations and does not scale to arbitrary numbers of premise statements. In this paper, we investigate whether an efficient planning heuristic is possible via embedding spaces compatible with deductive reasoning. Specifically, we evaluate whether embedding spaces exhibit a property we call deductive additivity: the sum of premise statement embeddings should be close to embeddings of conclusions based on those premises. We explore multiple sources of off-the-shelf dense embeddings in addition to fine-tuned embeddings from GPT3 and sparse embeddings from BM25. We study embedding models both intrinsically, evaluating whether the property of deductive additivity holds, and extrinsically, using them to assist planning in natural language proof generation. Lastly, we create a dataset, Single-Step Reasoning Contrast (SSRC), to further probe performance on various reasoning types. Our findings suggest that while standard embedding methods frequently embed conclusions near the sums of their premises, they fall short of being effective heuristics and lack the ability to model certain categories of reasoning.
Natural Language Deduction with Incomplete Information
Nov 01, 2022



A growing body of work studies how to answer a question or verify a claim by generating a natural language "proof": a chain of deductive inferences yielding the answer based on a set of premises. However, these methods can only make sound deductions when they follow from evidence that is given. We propose a new system that can handle the underspecified setting where not all premises are stated at the outset; that is, additional assumptions need to be materialized to prove a claim. By using a natural language generation model to abductively infer a premise given another premise and a conclusion, we can impute missing pieces of evidence needed for the conclusion to be true. Our system searches over two fringes in a bidirectional fashion, interleaving deductive (forward-chaining) and abductive (backward-chaining) generation steps. We sample multiple possible outputs for each step to achieve coverage of the search space, at the same time ensuring correctness by filtering low-quality generations with a round-trip validation procedure. Results on a modified version of the EntailmentBank dataset and a new dataset called Everyday Norms: Why Not? show that abductive generation with validation can recover premises across in- and out-of-domain settings.
Natural Language Deduction through Search over Statement Compositions
Jan 16, 2022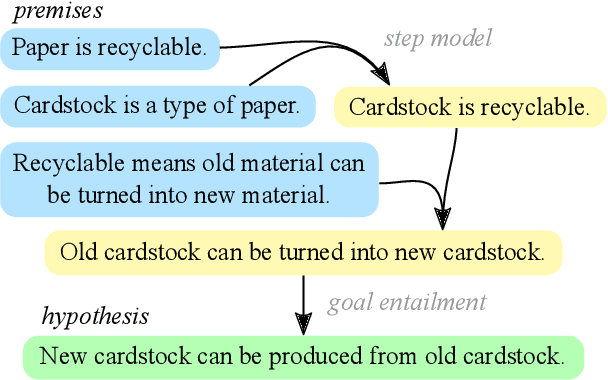

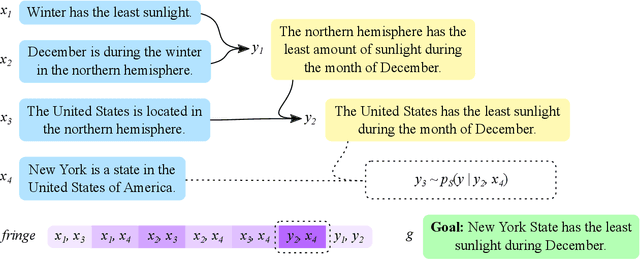
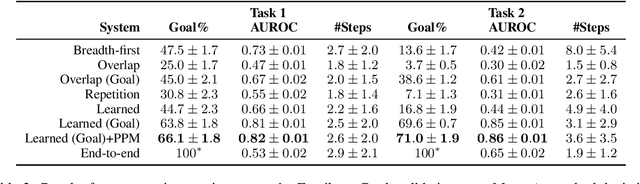
In settings from fact-checking to question answering, we frequently want to know whether a collection of evidence entails a hypothesis. Existing methods primarily focus on end-to-end discriminative versions of this task, but less work has treated the generative version in which a model searches over the space of entailed statements to derive the hypothesis. We propose a system for natural language deduction that decomposes the task into separate steps coordinated by best-first search, producing a tree of intermediate conclusions that faithfully reflects the system's reasoning process. Our experiments demonstrate that the proposed system can better distinguish verifiable hypotheses from unverifiable ones and produce natural language explanations that are more internally consistent than those produced by an end-to-end T5 model.
Flexible Operations for Natural Language Deduction
Apr 18, 2021
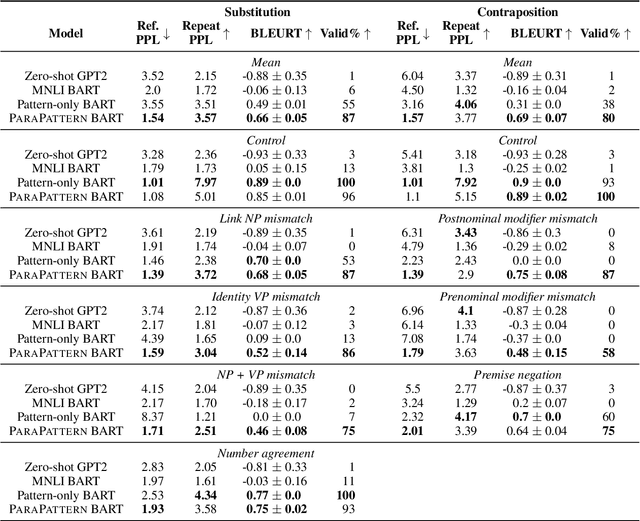

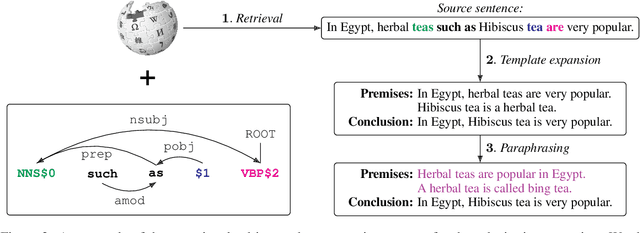
An interpretable system for complex, open-domain reasoning needs an interpretable meaning representation. Natural language is an excellent candidate -- it is both extremely expressive and easy for humans to understand. However, manipulating natural language statements in logically consistent ways is hard. Models have to be precise, yet robust enough to handle variation in how information is expressed. In this paper, we describe ParaPattern, a method for building models to generate logical transformations of diverse natural language inputs without direct human supervision. We use a BART-based model (Lewis et al., 2020) to generate the result of applying a particular logical operation to one or more premise statements. Crucially, we have a largely automated pipeline for scraping and constructing suitable training examples from Wikipedia, which are then paraphrased to give our models the ability to handle lexical variation. We evaluate our models using targeted contrast sets as well as out-of-domain sentence compositions from the QASC dataset (Khot et al., 2020). Our results demonstrate that our operation models are both accurate and flexible.
Byte Pair Encoding is Suboptimal for Language Model Pretraining
Apr 07, 2020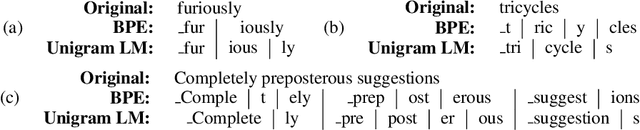



The success of pretrained transformer language models in natural language processing has led to a wide range of different pretraining setups. These models employ a variety of subword tokenization methods, most notably byte pair encoding (BPE) (Sennrich et al., 2016; Gage, 1994), the WordPiece method (Schuster and Nakajima, 2012), and unigram language modeling (Kudo, 2018), to segment text. However, to the best of our knowledge, the literature does not contain a direct evaluation of the impact of tokenization on language model pretraining. First, we analyze differences between BPE and unigram LM tokenization, and find that the unigram LM method is able to recover subword units that more strongly align with underlying morphology, in addition to avoiding several shortcomings of BPE stemming from its greedy construction procedure. We then compare the fine-tuned task performance of identical transformer masked language models pretrained with these tokenizations. Across downstream tasks, we find that the unigram LM tokenization method consistently matches or outperforms BPE. We hope that developers of future pretrained language models will consider adopting the unigram LM method over the more common BPE.