 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
Paper and Code
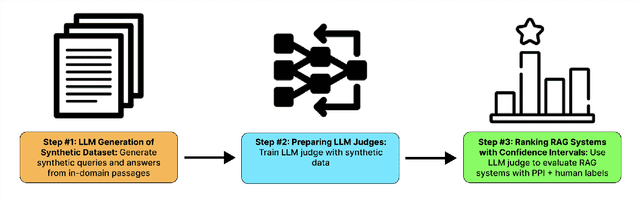
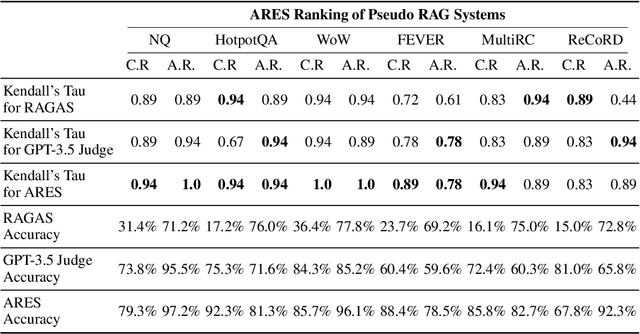
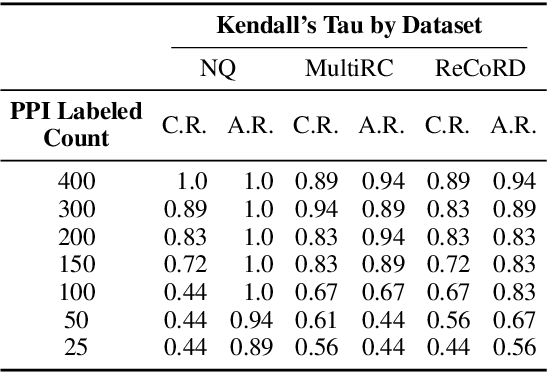
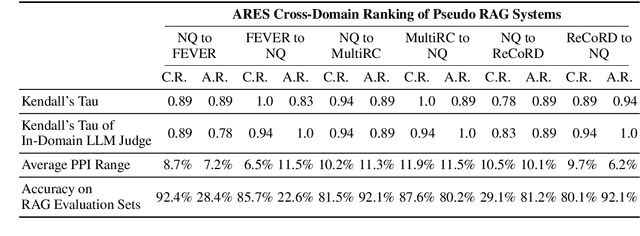
Evaluating retrieval-augmented generation (RAG) systems traditionally relies on hand annotations for input queries, passages to retrieve, and responses to generate. We introduce ARES, an Automated RAG Evaluation System, for evaluating RAG systems along the dimensions of context relevance, answer faithfulness, and answer relevance. Using synthetic training data, ARES finetunes lightweight LM judges to assess the quality of individual RAG components. To mitigate potential prediction errors, ARES utilizes a small set of human-annotated datapoints for prediction-powered inference (PPI). Across six different knowledge-intensive tasks in KILT and SuperGLUE, ARES accurately evaluates RAG systems while using a few hundred human annotations during evaluation. Furthermore, ARES judges remain effective across domain shifts, proving accurate even after changing the type of queries and/or documents used in the evaluated RAG systems. We make our datasets and code for replication and deployment available at https://github.com/stanford-futuredata/ARES.