 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Cases: How to Justify the Safety of Advanced AI Systems
Mar 18, 2024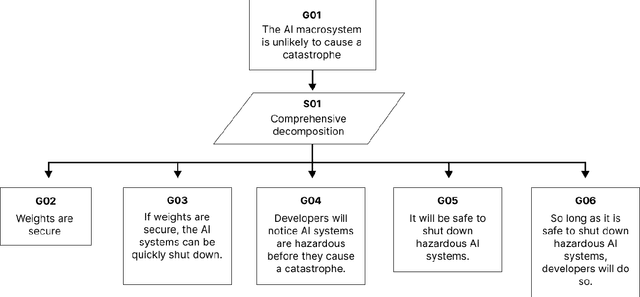



As AI systems become more advanced, companies and regulators will make difficult decisions about whether it is safe to train and deploy them. To prepare for these decisions, we investigate how developers could make a 'safety case,' which is a structured rationale that AI systems are unlikely to cause a catastrophe. We propose a framework for organizing a safety case and discuss four categories of arguments to justify safety: total inability to cause a catastrophe, sufficiently strong control measures, trustworthiness despite capability to cause harm, and -- if AI systems become much more powerful -- deference to credible AI advisors. We evaluate concrete examples of arguments in each category and outline how arguments could be combined to justify that AI systems are safe to deploy.
Steering Llama 2 via Contrastive Activation Addition
Dec 09, 2023
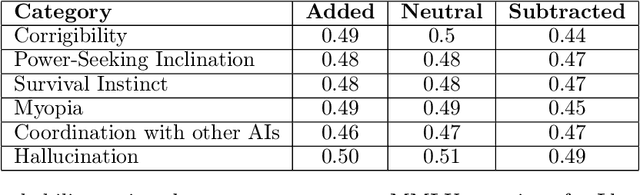

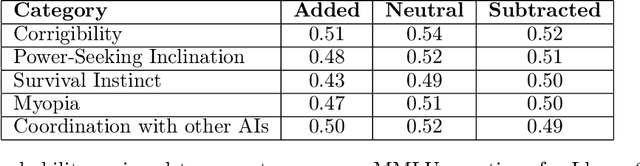
We introduce Contrastive Activation Addition (CAA), an innovative method for steering language models by modifying activations during their forward passes. CAA computes ``steering vectors'' by averaging the difference in residual stream activations between pairs of positive and negative examples of a particular behavior such as factual versus hallucinatory responses. During inference, these steering vectors are added at all token positions after the user's prompt with either a positive or negative coefficient, allowing precise control over the degree of the targeted behavior. We evaluate CAA's effectiveness on Llama 2 Chat using both multiple-choice behavioral question datasets and open-ended generation tasks. We demonstrate that CAA significantly alters model behavior, outperforms traditional methods like finetuning and few-shot prompting, and minimally reduces capabilities. Moreover, by employing various activation space interpretation methods, we gain deeper insights into CAA's mechanisms. CAA both accurately steers model outputs and also sheds light on how high-level concepts are represented in Large Language Models (LLMs).