 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Differentially Private Graph Neural Networks with Random Walk Sampling
Jan 02, 2023Deep learning models are known to put the privacy of their training data at risk, which poses challenges for their safe and ethical release to the public. Differentially private stochastic gradient descent is the de facto standard for training neural networks without leaking sensitive information about the training data. However, applying it to models for graph-structured data poses a novel challenge: unlike with i.i.d. data, sensitive information about a node in a graph cannot only leak through its gradients, but also through the gradients of all nodes within a larger neighborhood. In practice, this limits privacy-preserving deep learning on graphs to very shallow graph neural networks. We propose to solve this issue by training graph neural networks on disjoint subgraphs of a given training graph. We develop three random-walk-based methods for generating such disjoint subgraphs and perform a careful analysis of the data-generating distributions to provide strong privacy guarantees. Through extensive experiments, we show that our method greatly outperforms the state-of-the-art baseline on three large graphs, and matches or outperforms it on four smaller ones.
On the Robustness and Anomaly Detection of Sparse Neural Networks
Jul 09, 2022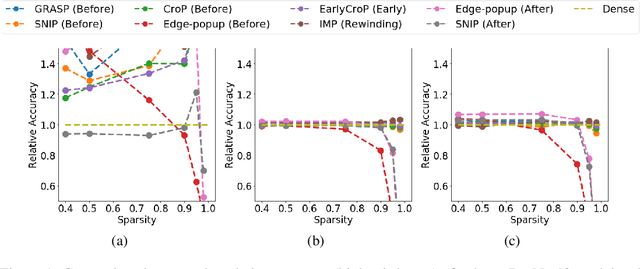

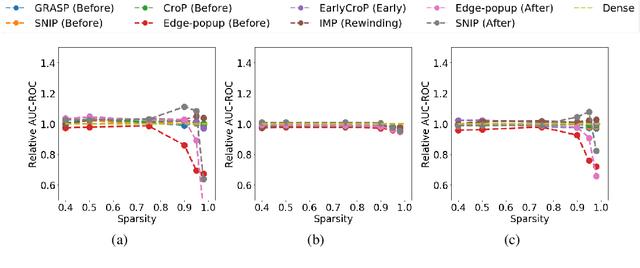

The robustness and anomaly detection capability of neural networks are crucial topics for their safe adoption in the real-world. Moreover, the over-parameterization of recent networks comes with high computational costs and raises questions about its influence on robustness and anomaly detection. In this work, we show that sparsity can make networks more robust and better anomaly detectors. To motivate this even further, we show that a pre-trained neural network contains, within its parameter space, sparse subnetworks that are better at these tasks without any further training. We also show that structured sparsity greatly helps in reducing the complexity of expensive robustness and detection methods, while maintaining or even improving their results on these tasks. Finally, we introduce a new method, SensNorm, which uses the sensitivity of weights derived from an appropriate pruning method to detect anomalous samples in the input.
Winning the Lottery Ahead of Time: Efficient Early Network Pruning
Jun 21, 2022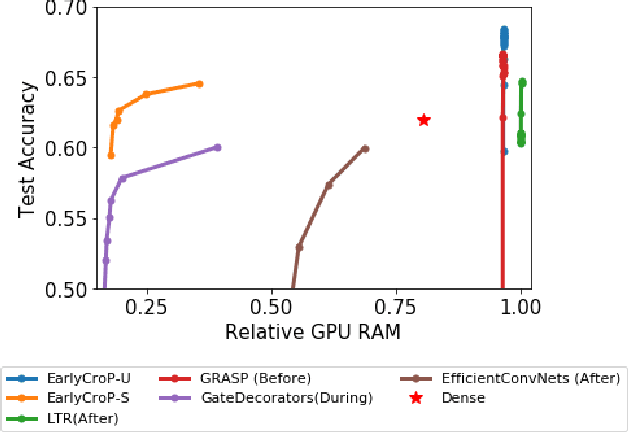
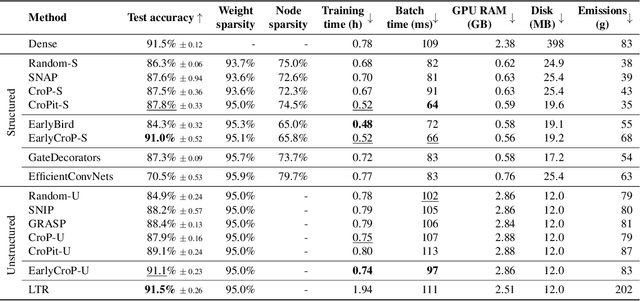
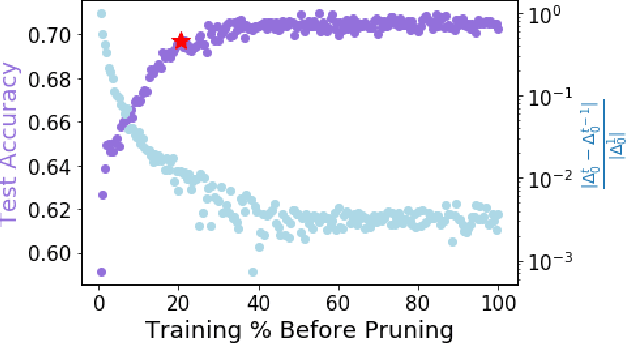
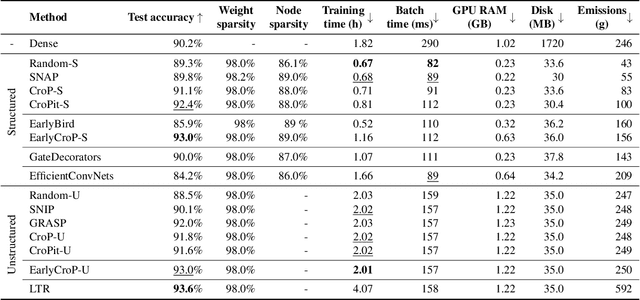
Pruning, the task of sparsifying deep neural networks, received increasing attention recently. Although state-of-the-art pruning methods extract highly sparse models, they neglect two main challenges: (1) the process of finding these sparse models is often very expensive; (2) unstructured pruning does not provide benefits in terms of GPU memory, training time, or carbon emissions. We propose Early Compression via Gradient Flow Preservation (EarlyCroP), which efficiently extracts state-of-the-art sparse models before or early in training addressing challenge (1), and can be applied in a structured manner addressing challenge (2). This enables us to train sparse networks on commodity GPUs whose dense versions would be too large, thereby saving costs and reducing hardware requirements. We empirically show that EarlyCroP outperforms a rich set of baselines for many tasks (incl. classification, regression) and domains (incl. computer vision, natural language processing, and reinforcment learning). EarlyCroP leads to accuracy comparable to dense training while outperforming pruning baselines.