 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Training for Graph Neural Networks
Jun 27, 2023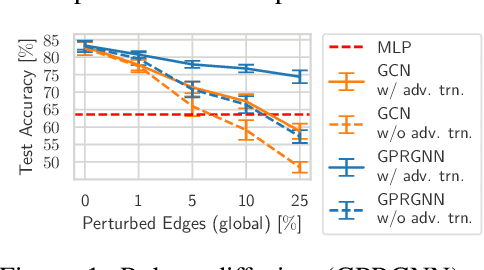
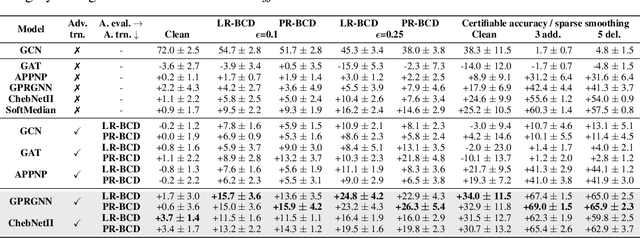
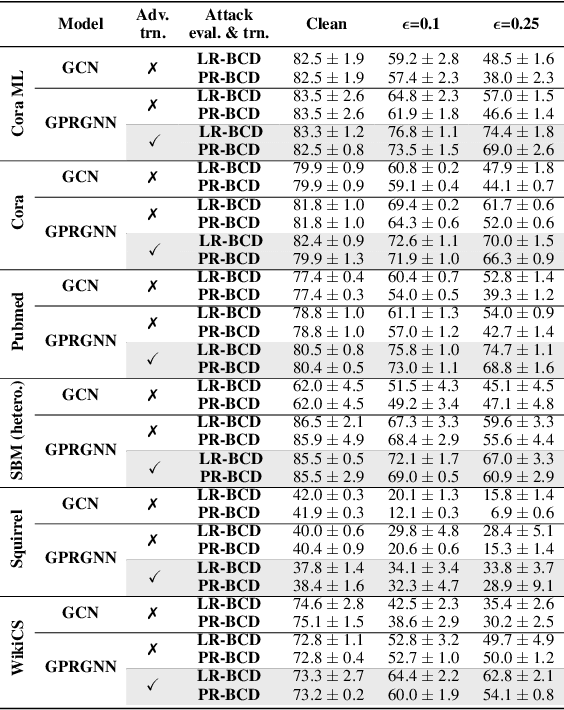
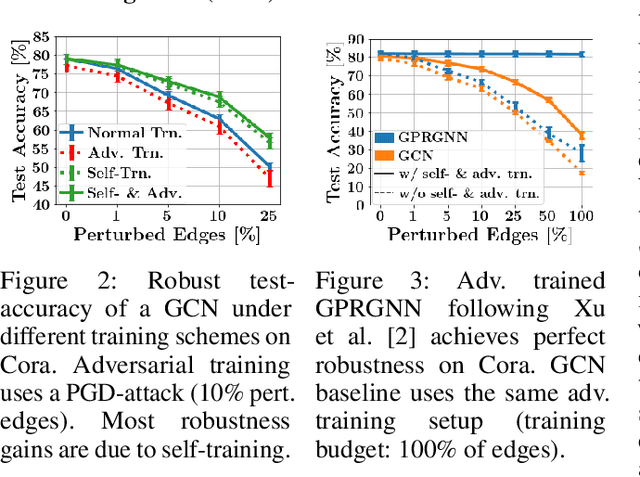
Despite its success in the image domain, adversarial training does not (yet) stand out as an effective defense for Graph Neural Networks (GNNs) against graph structure perturbations. In the pursuit of fixing adversarial training (1) we show and overcome fundamental theoretical as well as practical limitations of the adopted graph learning setting in prior work; (2) we reveal that more flexible GNNs based on learnable graph diffusion are able to adjust to adversarial perturbations, while the learned message passing scheme is naturally interpretable; (3) we introduce the first attack for structure perturbations that, while targeting multiple nodes at once, is capable of handling global (graph-level) as well as local (node-level) constraints. Including these contributions, we demonstrate that adversarial training is a state-of-the-art defense against adversarial structure perturbations.
Revisiting Robustness in Graph Machine Learning
May 02, 2023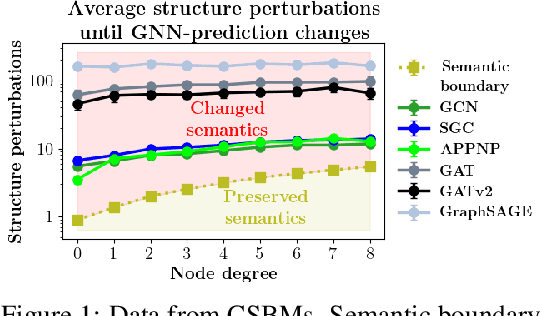
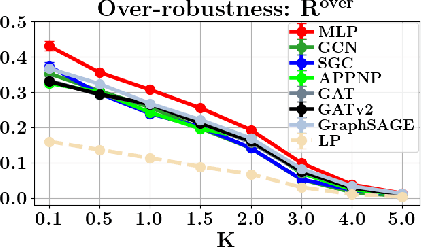
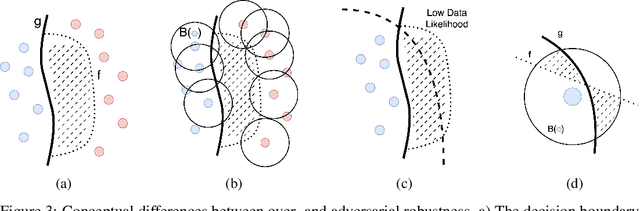

Many works show that node-level predictions of Graph Neural Networks (GNNs) are unrobust to small, often termed adversarial, changes to the graph structure. However, because manual inspection of a graph is difficult, it is unclear if the studied perturbations always preserve a core assumption of adversarial examples: that of unchanged semantic content. To address this problem, we introduce a more principled notion of an adversarial graph, which is aware of semantic content change. Using Contextual Stochastic Block Models (CSBMs) and real-world graphs, our results uncover: $i)$ for a majority of nodes the prevalent perturbation models include a large fraction of perturbed graphs violating the unchanged semantics assumption; $ii)$ surprisingly, all assessed GNNs show over-robustness - that is robustness beyond the point of semantic change. We find this to be a complementary phenomenon to adversarial examples and show that including the label-structure of the training graph into the inference process of GNNs significantly reduces over-robustness, while having a positive effect on test accuracy and adversarial robustness. Theoretically, leveraging our new semantics-aware notion of robustness, we prove that there is no robustness-accuracy tradeoff for inductively classifying a newly added node.