 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic layer selection in decoder-only transformers
Oct 26, 2024The vast size of Large Language Models (LLMs) has prompted a search to optimize inference. One effective approach is dynamic inference, which adapts the architecture to the sample-at-hand to reduce the overall computational cost. We empirically examine two common dynamic inference methods for natural language generation (NLG): layer skipping and early exiting. We find that a pre-trained decoder-only model is significantly more robust to layer removal via layer skipping, as opposed to early exit. We demonstrate the difficulty of using hidden state information to adapt computation on a per-token basis for layer skipping. Finally, we show that dynamic computation allocation on a per-sequence basis holds promise for significant efficiency gains by constructing an oracle controller. Remarkably, we find that there exists an allocation which achieves equal performance to the full model using only 23.3% of its layers on average.
Predicting Probabilities of Error to Combine Quantization and Early Exiting: QuEE
Jun 20, 2024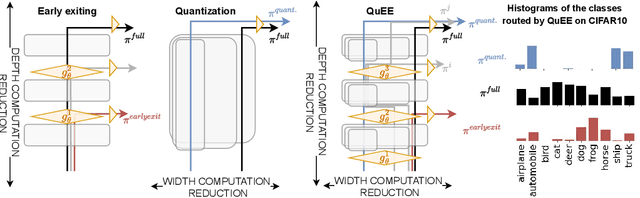
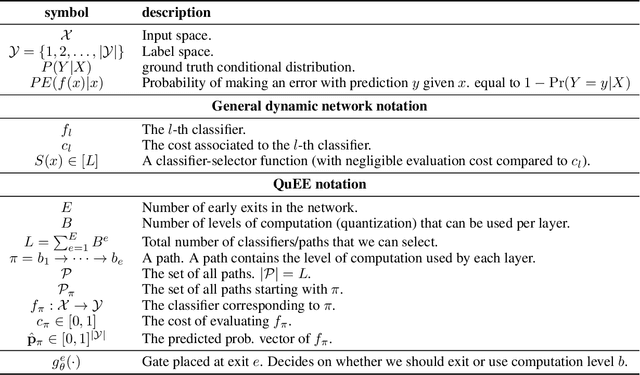
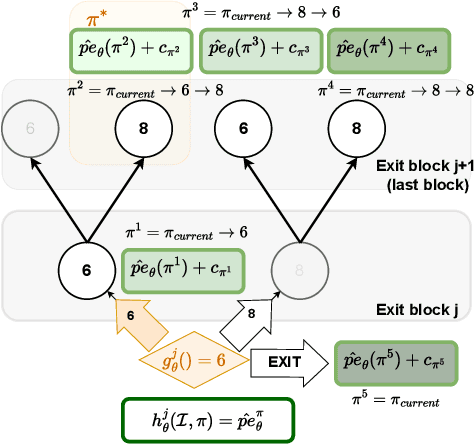

Machine learning models can solve complex tasks but often require significant computational resources during inference. This has led to the development of various post-training computation reduction methods that tackle this issue in different ways, such as quantization which reduces the precision of weights and arithmetic operations, and dynamic networks which adapt computation to the sample at hand. In this work, we propose a more general dynamic network that can combine both quantization and early exit dynamic network: QuEE. Our algorithm can be seen as a form of soft early exiting or input-dependent compression. Rather than a binary decision between exiting or continuing, we introduce the possibility of continuing with reduced computation. This complicates the traditionally considered early exiting problem, which we solve through a principled formulation. The crucial factor of our approach is accurate prediction of the potential accuracy improvement achievable through further computation. We demonstrate the effectiveness of our method through empirical evaluation, as well as exploring the conditions for its success on 4 classification datasets.
Jointly-Learned Exit and Inference for a Dynamic Neural Network : JEI-DNN
Oct 13, 2023Large pretrained models, coupled with fine-tuning, are slowly becoming established as the dominant architecture in machine learning. Even though these models offer impressive performance, their practical application is often limited by the prohibitive amount of resources required for every inference. Early-exiting dynamic neural networks (EDNN) circumvent this issue by allowing a model to make some of its predictions from intermediate layers (i.e., early-exit). Training an EDNN architecture is challenging as it consists of two intertwined components: the gating mechanism (GM) that controls early-exiting decisions and the intermediate inference modules (IMs) that perform inference from intermediate representations. As a result, most existing approaches rely on thresholding confidence metrics for the gating mechanism and strive to improve the underlying backbone network and the inference modules. Although successful, this approach has two fundamental shortcomings: 1) the GMs and the IMs are decoupled during training, leading to a train-test mismatch; and 2) the thresholding gating mechanism introduces a positive bias into the predictive probabilities, making it difficult to readily extract uncertainty information. We propose a novel architecture that connects these two modules. This leads to significant performance improvements on classification datasets and enables better uncertainty characterization capabilities.