 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Probabilities of Error to Combine Quantization and Early Exiting: QuEE
Paper and Code
Jun 20, 2024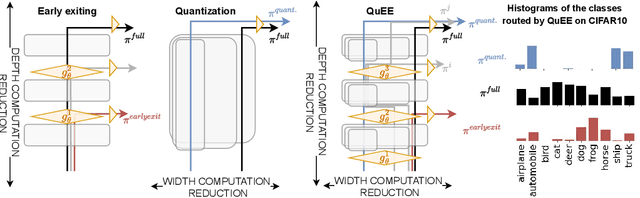
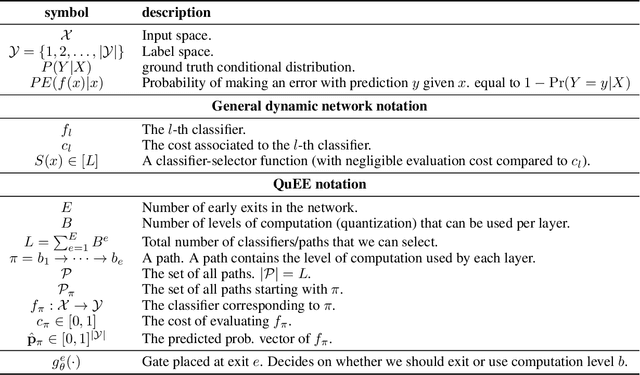
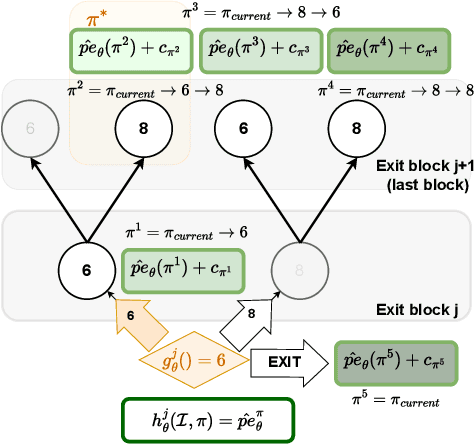

Machine learning models can solve complex tasks but often require significant computational resources during inference. This has led to the development of various post-training computation reduction methods that tackle this issue in different ways, such as quantization which reduces the precision of weights and arithmetic operations, and dynamic networks which adapt computation to the sample at hand. In this work, we propose a more general dynamic network that can combine both quantization and early exit dynamic network: QuEE. Our algorithm can be seen as a form of soft early exiting or input-dependent compression. Rather than a binary decision between exiting or continuing, we introduce the possibility of continuing with reduced computation. This complicates the traditionally considered early exiting problem, which we solve through a principled formulation. The crucial factor of our approach is accurate prediction of the potential accuracy improvement achievable through further computation. We demonstrate the effectiveness of our method through empirical evaluation, as well as exploring the conditions for its success on 4 classification datasets.