 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Epistemic and Aleatoric Uncertainty in Reinforcement Learning
Paper and Code
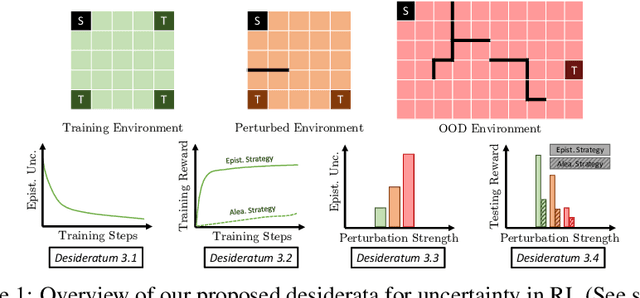

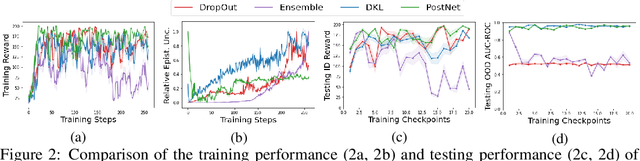
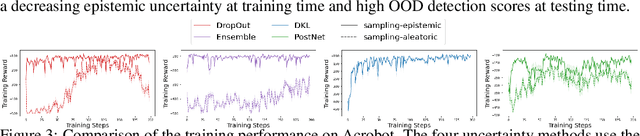
Characterizing aleatoric and epistemic uncertainty on the predicted rewards can help in building reliable reinforcement learning (RL) systems. Aleatoric uncertainty results from the irreducible environment stochasticity leading to inherently risky states and actions. Epistemic uncertainty results from the limited information accumulated during learning to make informed decisions. Characterizing aleatoric and epistemic uncertainty can be used to speed up learning in a training environment, improve generalization to similar testing environments, and flag unfamiliar behavior in anomalous testing environments. In this work, we introduce a framework for disentangling aleatoric and epistemic uncertainty in RL. (1) We first define four desiderata that capture the desired behavior for aleatoric and epistemic uncertainty estimation in RL at both training and testing time. (2) We then present four RL models inspired by supervised learning (i.e. Monte Carlo dropout, ensemble, deep kernel learning models, and evidential networks) to instantiate aleatoric and epistemic uncertainty. Finally, (3) we propose a practical evaluation method to evaluate uncertainty estimation in model-free RL based on detection of out-of-distribution environments and generalization to perturbed environments. We present theoretical and experimental evidence to validate that carefully equipping model-free RL agents with supervised learning uncertainty methods can fulfill our desiderata.