 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMPL-IK: Learned Morphology-Aware Inverse Kinematics for AI Driven Artistic Workflows
Aug 16, 2022
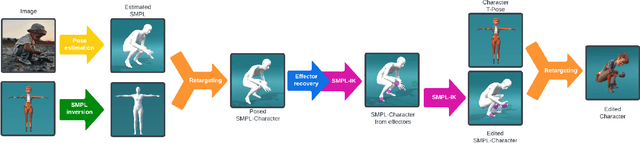


Inverse Kinematics (IK) systems are often rigid with respect to their input character, thus requiring user intervention to be adapted to new skeletons. In this paper we aim at creating a flexible, learned IK solver applicable to a wide variety of human morphologies. We extend a state-of-the-art machine learning IK solver to operate on the well known Skinned Multi-Person Linear model (SMPL). We call our model SMPL-IK, and show that when integrated into real-time 3D software, this extended system opens up opportunities for defining novel AI-assisted animation workflows. For example, pose authoring can be made more flexible with SMPL-IK by allowing users to modify gender and body shape while posing a character. Additionally, when chained with existing pose estimation algorithms, SMPL-IK accelerates posing by allowing users to bootstrap 3D scenes from 2D images while allowing for further editing. Finally, we propose a novel SMPL Shape Inversion mechanism (SMPL-SI) to map arbitrary humanoid characters to the SMPL space, allowing artists to leverage SMPL-IK on custom characters. In addition to qualitative demos showing proposed tools, we present quantitative SMPL-IK baselines on the H36M and AMASS datasets.
Motion Inbetweening via Deep $Δ$-Interpolator
Jan 27, 2022
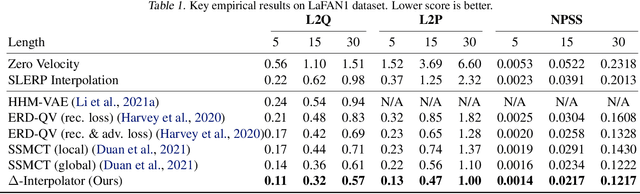
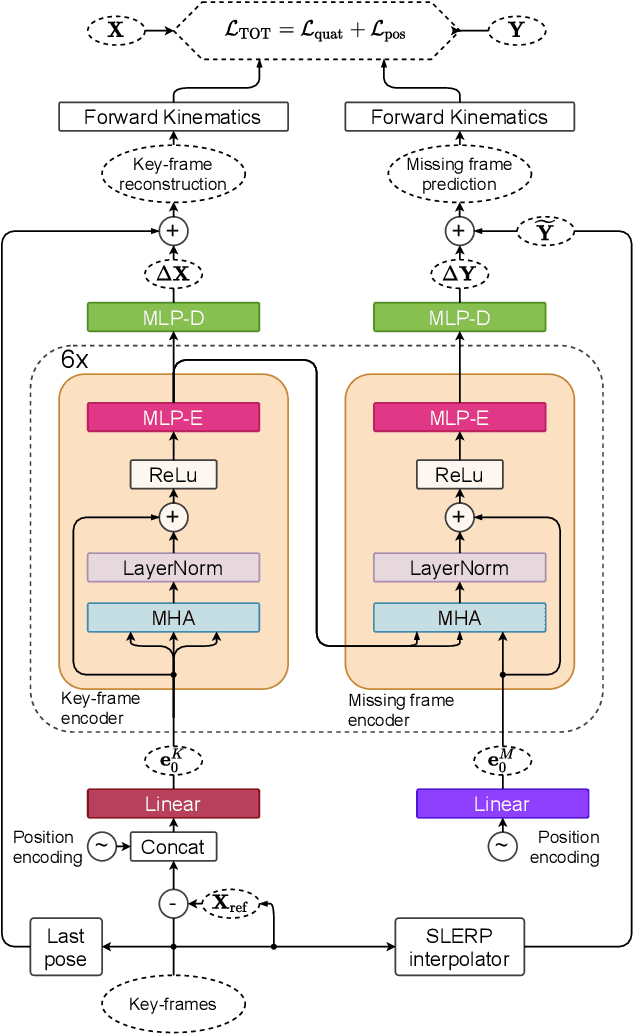
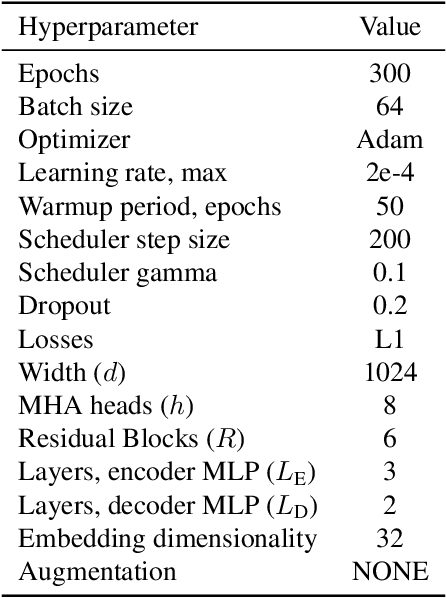
We show that the task of synthesizing missing middle frames, commonly known as motion in-betweening in the animation industry, can be solved more accurately and effectively if a deep learning interpolator operates in the delta mode, using the spherical linear interpolator as a baseline. We demonstrate our empirical findings on the publicly available LaFAN1 dataset. We further generalize this result by showing that the $\Delta$-regime is viable with respect to the reference of the last known frame (also known as the zero-velocity model). This supports the more general conclusion that deep in-betweening in the reference frame local to input frames is more accurate and robust than in-betweening in the global (world) reference frame advocated in previous work. Our code is publicly available at https://github.com/boreshkinai/delta-interpolator.
ProtoRes: Proto-Residual Architecture for Deep Modeling of Human Pose
Jun 09, 2021
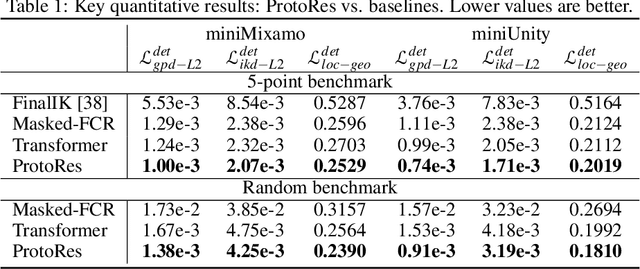
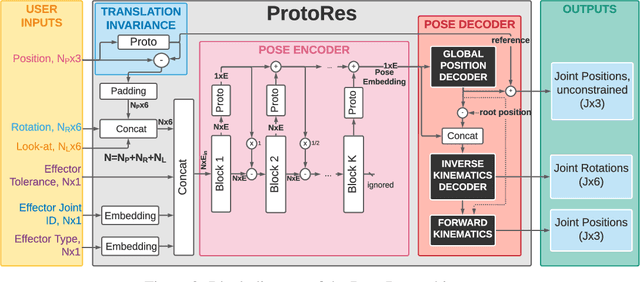
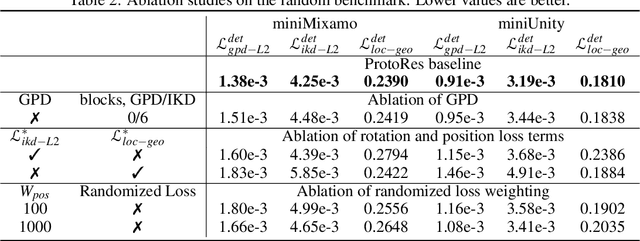
Our work focuses on the development of a learnable neural representation of human pose for advanced AI assisted animation tooling. Specifically, we tackle the problem of constructing a full static human pose based on sparse and variable user inputs (e.g. locations and/or orientations of a subset of body joints). To solve this problem, we propose a novel neural architecture that combines residual connections with prototype encoding of a partially specified pose to create a new complete pose from the learned latent space. We show that our architecture outperforms a baseline based on Transformer, both in terms of accuracy and computational efficiency. Additionally, we develop a user interface to integrate our neural model in Unity, a real-time 3D development platform. Furthermore, we introduce two new datasets representing the static human pose modeling problem, based on high-quality human motion capture data, which will be released publicly along with model code.
Robust Motion In-betweening
Feb 09, 2021


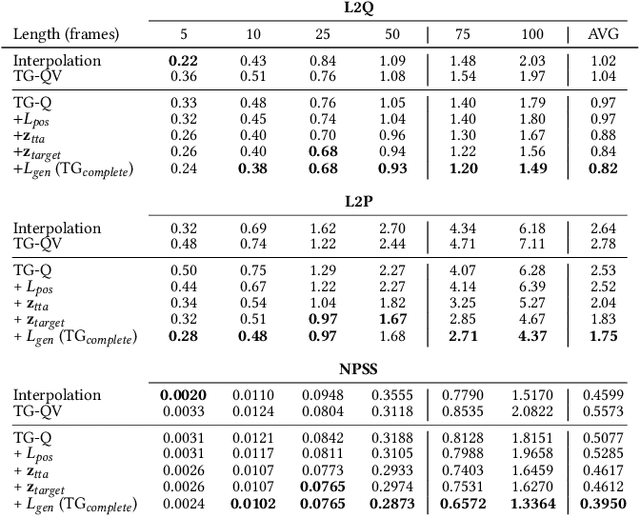
In this work we present a novel, robust transition generation technique that can serve as a new tool for 3D animators, based on adversarial recurrent neural networks. The system synthesizes high-quality motions that use temporally-sparse keyframes as animation constraints. This is reminiscent of the job of in-betweening in traditional animation pipelines, in which an animator draws motion frames between provided keyframes. We first show that a state-of-the-art motion prediction model cannot be easily converted into a robust transition generator when only adding conditioning information about future keyframes. To solve this problem, we then propose two novel additive embedding modifiers that are applied at each timestep to latent representations encoded inside the network's architecture. One modifier is a time-to-arrival embedding that allows variations of the transition length with a single model. The other is a scheduled target noise vector that allows the system to be robust to target distortions and to sample different transitions given fixed keyframes. To qualitatively evaluate our method, we present a custom MotionBuilder plugin that uses our trained model to perform in-betweening in production scenarios. To quantitatively evaluate performance on transitions and generalizations to longer time horizons, we present well-defined in-betweening benchmarks on a subset of the widely used Human3.6M dataset and on LaFAN1, a novel high quality motion capture dataset that is more appropriate for transition generation. We are releasing this new dataset along with this work, with accompanying code for reproducing our baseline results.
Promoting Coordination through Policy Regularization in Multi-Agent Reinforcement Learning
Aug 06, 2019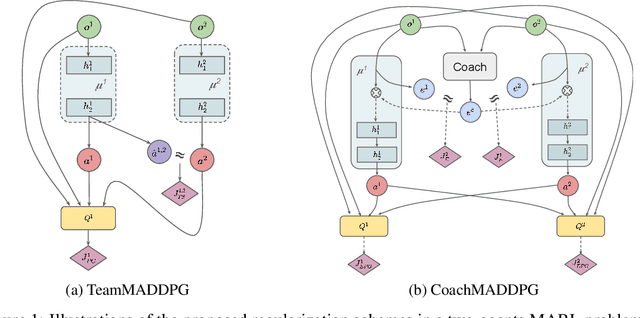
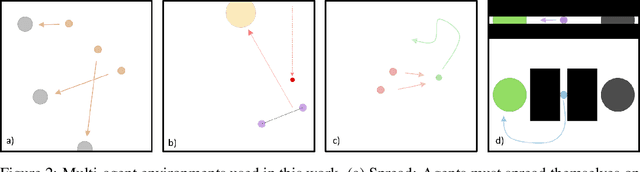
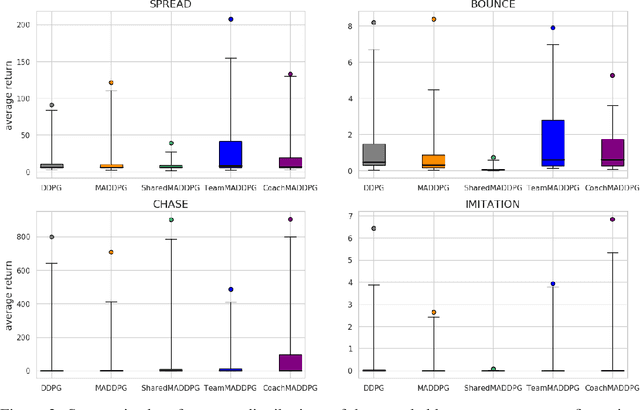
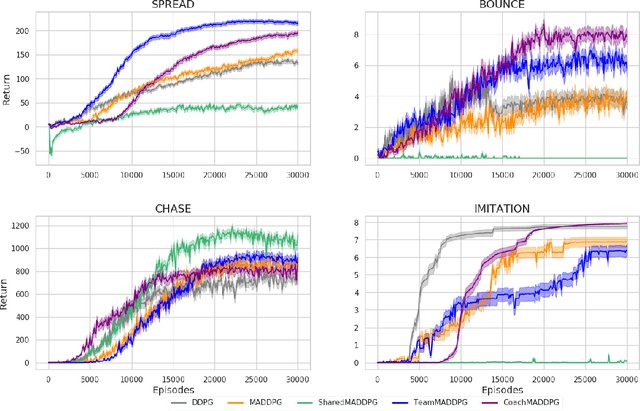
A central challenge in multi-agent reinforcement learning is the induction of coordination between agents of a team. In this work, we investigate how to promote inter-agent coordination and discuss two possible avenues based respectively on inter-agent modelling and guided synchronized sub-policies. We test each approach in four challenging continuous control tasks with sparse rewards and compare them against three variants of MADDPG, a state-of-the-art multi-agent reinforcement learning algorithm. To ensure a fair comparison, we rely on a thorough hyper-parameter selection and training methodology that allows a fixed hyper-parameter search budget for each algorithm and environment. We consequently assess both the hyper-parameter sensitivity, sample-efficiency and asymptotic performance of each learning method. Our experiments show that our proposed algorithms are more robust to the hyper-parameter choice and reliably lead to strong results.
Recurrent Semi-supervised Classification and Constrained Adversarial Generation with Motion Capture Data
Jul 11, 2018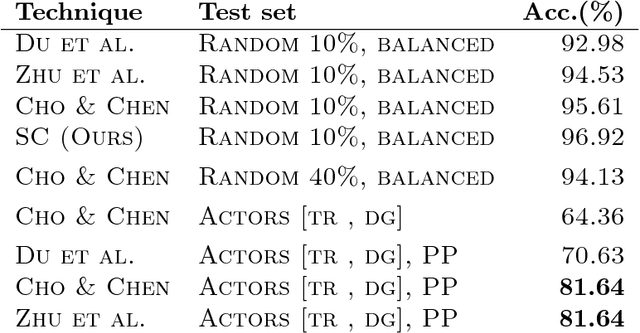
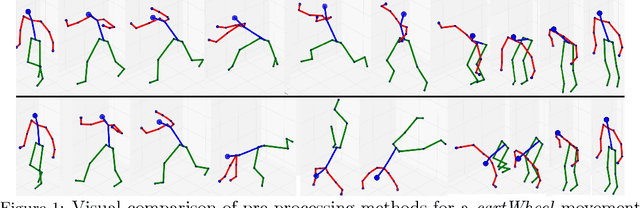
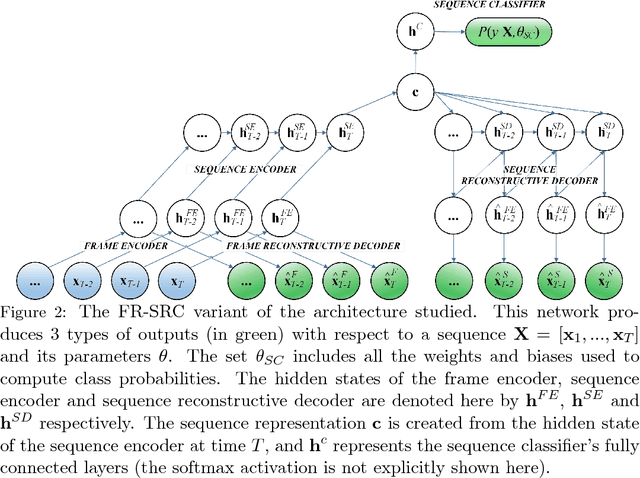
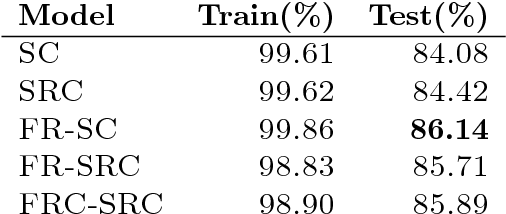
We explore recurrent encoder multi-decoder neural network architectures for semi-supervised sequence classification and reconstruction. We find that the use of multiple reconstruction modules helps models generalize in a classification task when only a small amount of labeled data is available, which is often the case in practice. Such models provide useful high-level representations of motions allowing clustering, searching and faster labeling of new sequences. We also propose a new, realistic partitioning of a well-known, high quality motion-capture dataset for better evaluations. We further explore a novel formulation for future-predicting decoders based on conditional recurrent generative adversarial networks, for which we propose both soft and hard constraints for transition generation derived from desired physical properties of synthesized future movements and desired animation goals. We find that using such constraints allow to stabilize the training of recurrent adversarial architectures for animation generation.