 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAviary: training language agents on challenging scientific tasks
Dec 30, 2024



Solving complex real-world tasks requires cycles of actions and observations. This is particularly true in science, where tasks require many cycles of analysis, tool use, and experimentation. Language agents are promising for automating intellectual tasks in science because they can interact with tools via natural language or code. Yet their flexibility creates conceptual and practical challenges for software implementations, since agents may comprise non-standard components such as internal reasoning, planning, tool usage, as well as the inherent stochasticity of temperature-sampled language models. Here, we introduce Aviary, an extensible gymnasium for language agents. We formalize agents as policies solving language-grounded partially observable Markov decision processes, which we term language decision processes. We then implement five environments, including three challenging scientific environments: (1) manipulating DNA constructs for molecular cloning, (2) answering research questions by accessing scientific literature, and (3) engineering protein stability. These environments were selected for their focus on multi-step reasoning and their relevance to contemporary biology research. Finally, with online training and scaling inference-time compute, we show that language agents backed by open-source, non-frontier LLMs can match and exceed both frontier LLM agents and human experts on multiple tasks at up to 100x lower inference cost.
Decoding speech from non-invasive brain recordings
Aug 25, 2022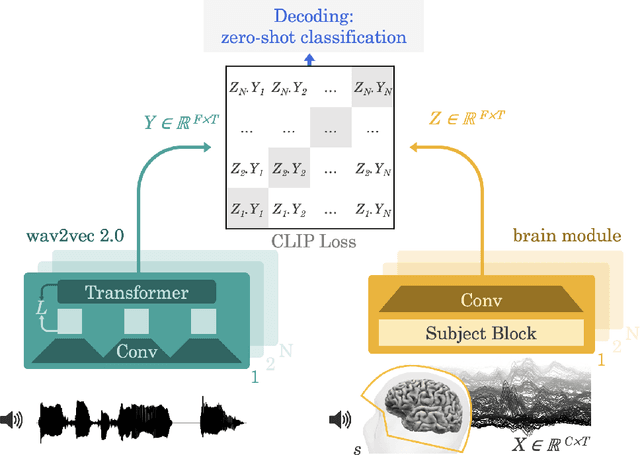

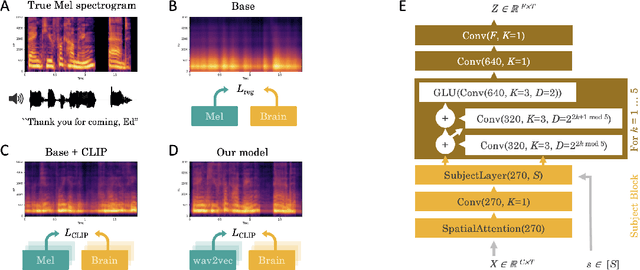

Decoding language from brain activity is a long-awaited goal in both healthcare and neuroscience. Major milestones have recently been reached thanks to intracranial devices: subject-specific pipelines trained on invasive brain responses to basic language tasks now start to efficiently decode interpretable features (e.g. letters, words, spectrograms). However, scaling this approach to natural speech and non-invasive brain recordings remains a major challenge. Here, we propose a single end-to-end architecture trained with contrastive learning across a large cohort of individuals to predict self-supervised representations of natural speech. We evaluate our model on four public datasets, encompassing 169 volunteers recorded with magneto- or electro-encephalography (M/EEG), while they listened to natural speech. The results show that our model can identify, from 3s of MEG signals, the corresponding speech segment with up to 72.5% top-10 accuracy out of 1,594 distinct segments (and 44% top-1 accuracy), and up to 19.1% out of 2,604 segments for EEG recordings -- hence allowing the decoding of phrases absent from the training set. Model comparison and ablation analyses show that these performances directly benefit from our original design choices, namely the use of (i) a contrastive objective, (ii) pretrained representations of speech and (iii) a common convolutional architecture simultaneously trained across several participants. Together, these results delineate a promising path to decode natural language processing in real time from non-invasive recordings of brain activity.
Online Self-Attentive Gated RNNs for Real-Time Speaker Separation
Jul 27, 2021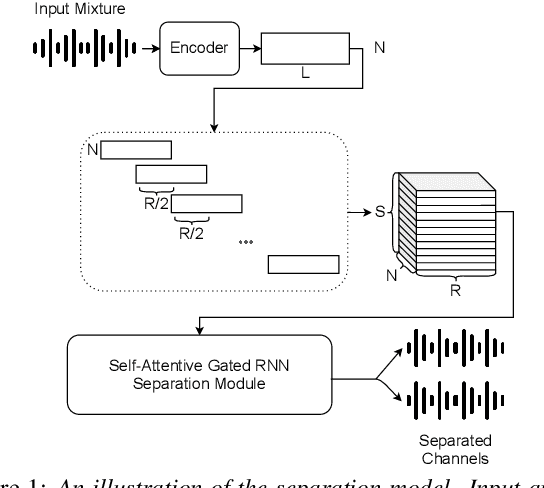



Deep neural networks have recently shown great success in the task of blind source separation, both under monaural and binaural settings. Although these methods were shown to produce high-quality separations, they were mainly applied under offline settings, in which the model has access to the full input signal while separating the signal. In this study, we convert a non-causal state-of-the-art separation model into a causal and real-time model and evaluate its performance under both online and offline settings. We compare the performance of the proposed model to several baseline methods under anechoic, noisy, and noisy-reverberant recording conditions while exploring both monaural and binaural inputs and outputs. Our findings shed light on the relative difference between causal and non-causal models when performing separation. Our stateful implementation for online separation leads to a minor drop in performance compared to the offline model; 0.8dB for monaural inputs and 0.3dB for binaural inputs while reaching a real-time factor of 0.65. Samples can be found under the following link: https://kwanum.github.io/sagrnnc-stream-results/.
High Fidelity Speech Regeneration with Application to Speech Enhancement
Jan 31, 2021

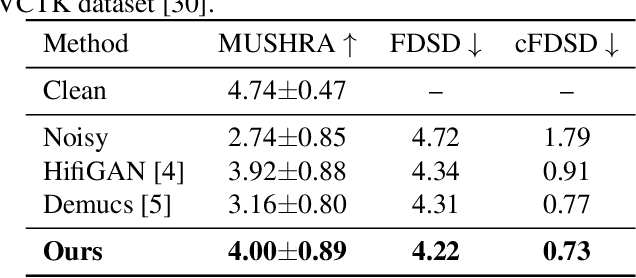
Speech enhancement has seen great improvement in recent years mainly through contributions in denoising, speaker separation, and dereverberation methods that mostly deal with environmental effects on vocal audio. To enhance speech beyond the limitations of the original signal, we take a regeneration approach, in which we recreate the speech from its essence, including the semi-recognized speech, prosody features, and identity. We propose a wav-to-wav generative model for speech that can generate 24khz speech in a real-time manner and which utilizes a compact speech representation, composed of ASR and identity features, to achieve a higher level of intelligibility. Inspired by voice conversion methods, we train to augment the speech characteristics while preserving the identity of the source using an auxiliary identity network. Perceptual acoustic metrics and subjective tests show that the method obtains valuable improvements over recent baselines.