 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding speech from non-invasive brain recordings
Paper and Code
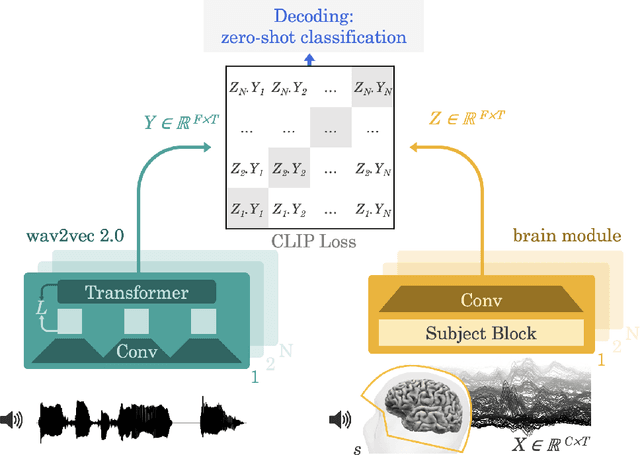

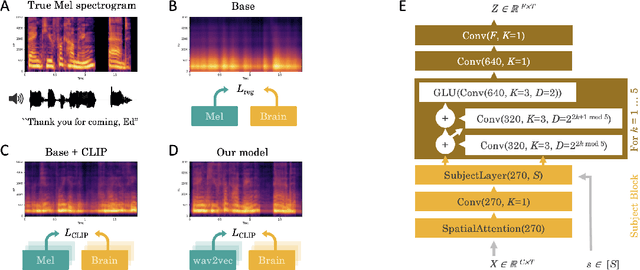

Decoding language from brain activity is a long-awaited goal in both healthcare and neuroscience. Major milestones have recently been reached thanks to intracranial devices: subject-specific pipelines trained on invasive brain responses to basic language tasks now start to efficiently decode interpretable features (e.g. letters, words, spectrograms). However, scaling this approach to natural speech and non-invasive brain recordings remains a major challenge. Here, we propose a single end-to-end architecture trained with contrastive learning across a large cohort of individuals to predict self-supervised representations of natural speech. We evaluate our model on four public datasets, encompassing 169 volunteers recorded with magneto- or electro-encephalography (M/EEG), while they listened to natural speech. The results show that our model can identify, from 3s of MEG signals, the corresponding speech segment with up to 72.5% top-10 accuracy out of 1,594 distinct segments (and 44% top-1 accuracy), and up to 19.1% out of 2,604 segments for EEG recordings -- hence allowing the decoding of phrases absent from the training set. Model comparison and ablation analyses show that these performances directly benefit from our original design choices, namely the use of (i) a contrastive objective, (ii) pretrained representations of speech and (iii) a common convolutional architecture simultaneously trained across several participants. Together, these results delineate a promising path to decode natural language processing in real time from non-invasive recordings of brain activity.