 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoTracker3: Simpler and Better Point Tracking by Pseudo-Labelling Real Videos
Oct 15, 2024Most state-of-the-art point trackers are trained on synthetic data due to the difficulty of annotating real videos for this task. However, this can result in suboptimal performance due to the statistical gap between synthetic and real videos. In order to understand these issues better, we introduce CoTracker3, comprising a new tracking model and a new semi-supervised training recipe. This allows real videos without annotations to be used during training by generating pseudo-labels using off-the-shelf teachers. The new model eliminates or simplifies components from previous trackers, resulting in a simpler and often smaller architecture. This training scheme is much simpler than prior work and achieves better results using 1,000 times less data. We further study the scaling behaviour to understand the impact of using more real unsupervised data in point tracking. The model is available in online and offline variants and reliably tracks visible and occluded points.
Meta 3D Gen
Jul 02, 2024


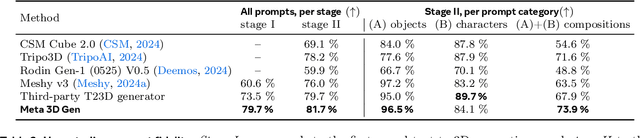
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
Aligning brain functions boosts the decoding of visual semantics in novel subjects
Dec 11, 2023Deep learning is leading to major advances in the realm of brain decoding from functional Magnetic Resonance Imaging (fMRI). However, the large inter-subject variability in brain characteristics has limited most studies to train models on one subject at a time. Consequently, this approach hampers the training of deep learning models, which typically requires very large datasets. Here, we propose to boost brain decoding by aligning brain responses to videos and static images across subjects. Compared to the anatomically-aligned baseline, our method improves out-of-subject decoding performance by up to 75%. Moreover, it also outperforms classical single-subject approaches when fewer than 100 minutes of data is available for the tested subject. Furthermore, we propose a new multi-subject alignment method, which obtains comparable results to that of classical single-subject approaches while improving out-of-subject generalization. Finally, we show that this method aligns neural representations in accordance with brain anatomy. Overall, this study lays the foundations for leveraging extensive neuroimaging datasets and enhancing the decoding of individuals with a limited amount of brain recordings.
Real-time volumetric rendering of dynamic humans
Mar 21, 2023



We present a method for fast 3D reconstruction and real-time rendering of dynamic humans from monocular videos with accompanying parametric body fits. Our method can reconstruct a dynamic human in less than 3h using a single GPU, compared to recent state-of-the-art alternatives that take up to 72h. These speedups are obtained by using a lightweight deformation model solely based on linear blend skinning, and an efficient factorized volumetric representation for modeling the shape and color of the person in canonical pose. Moreover, we propose a novel local ray marching rendering which, by exploiting standard GPU hardware and without any baking or conversion of the radiance field, allows visualizing the neural human on a mobile VR device at 40 frames per second with minimal loss of visual quality. Our experimental evaluation shows superior or competitive results with state-of-the art methods while obtaining large training speedup, using a simple model, and achieving real-time rendering.
Text-To-4D Dynamic Scene Generation
Jan 26, 2023



We present MAV3D (Make-A-Video3D), a method for generating three-dimensional dynamic scenes from text descriptions. Our approach uses a 4D dynamic Neural Radiance Field (NeRF), which is optimized for scene appearance, density, and motion consistency by querying a Text-to-Video (T2V) diffusion-based model. The dynamic video output generated from the provided text can be viewed from any camera location and angle, and can be composited into any 3D environment. MAV3D does not require any 3D or 4D data and the T2V model is trained only on Text-Image pairs and unlabeled videos. We demonstrate the effectiveness of our approach using comprehensive quantitative and qualitative experiments and show an improvement over previously established internal baselines. To the best of our knowledge, our method is the first to generate 3D dynamic scenes given a text description.