 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmu Edit: Precise Image Editing via Recognition and Generation Tasks
Nov 16, 2023



Instruction-based image editing holds immense potential for a variety of applications, as it enables users to perform any editing operation using a natural language instruction. However, current models in this domain often struggle with accurately executing user instructions. We present Emu Edit, a multi-task image editing model which sets state-of-the-art results in instruction-based image editing. To develop Emu Edit we train it to multi-task across an unprecedented range of tasks, such as region-based editing, free-form editing, and Computer Vision tasks, all of which are formulated as generative tasks. Additionally, to enhance Emu Edit's multi-task learning abilities, we provide it with learned task embeddings which guide the generation process towards the correct edit type. Both these elements are essential for Emu Edit's outstanding performance. Furthermore, we show that Emu Edit can generalize to new tasks, such as image inpainting, super-resolution, and compositions of editing tasks, with just a few labeled examples. This capability offers a significant advantage in scenarios where high-quality samples are scarce. Lastly, to facilitate a more rigorous and informed assessment of instructable image editing models, we release a new challenging and versatile benchmark that includes seven different image editing tasks.
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Sep 05, 2023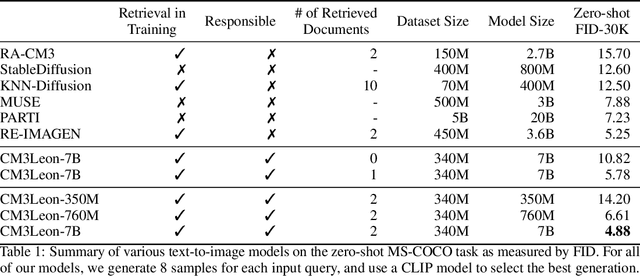

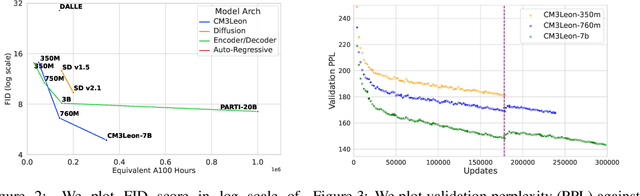

We present CM3Leon (pronounced "Chameleon"), a retrieval-augmented, token-based, decoder-only multi-modal language model capable of generating and infilling both text and images. CM3Leon uses the CM3 multi-modal architecture but additionally shows the extreme benefits of scaling up and tuning on more diverse instruction-style data. It is the first multi-modal model trained with a recipe adapted from text-only language models, including a large-scale retrieval-augmented pre-training stage and a second multi-task supervised fine-tuning (SFT) stage. It is also a general-purpose model that can do both text-to-image and image-to-text generation, allowing us to introduce self-contained contrastive decoding methods that produce high-quality outputs. Extensive experiments demonstrate that this recipe is highly effective for multi-modal models. CM3Leon achieves state-of-the-art performance in text-to-image generation with 5x less training compute than comparable methods (zero-shot MS-COCO FID of 4.88). After SFT, CM3Leon can also demonstrate unprecedented levels of controllability in tasks ranging from language-guided image editing to image-controlled generation and segmentation.
Text-To-4D Dynamic Scene Generation
Jan 26, 2023



We present MAV3D (Make-A-Video3D), a method for generating three-dimensional dynamic scenes from text descriptions. Our approach uses a 4D dynamic Neural Radiance Field (NeRF), which is optimized for scene appearance, density, and motion consistency by querying a Text-to-Video (T2V) diffusion-based model. The dynamic video output generated from the provided text can be viewed from any camera location and angle, and can be composited into any 3D environment. MAV3D does not require any 3D or 4D data and the T2V model is trained only on Text-Image pairs and unlabeled videos. We demonstrate the effectiveness of our approach using comprehensive quantitative and qualitative experiments and show an improvement over previously established internal baselines. To the best of our knowledge, our method is the first to generate 3D dynamic scenes given a text description.
Make-A-Video: Text-to-Video Generation without Text-Video Data
Sep 29, 2022

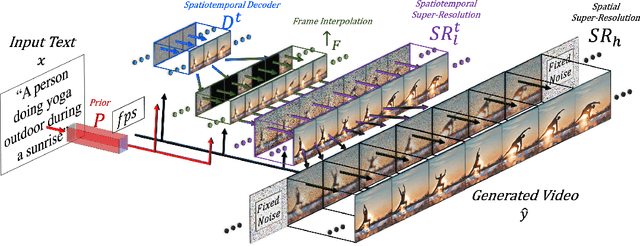
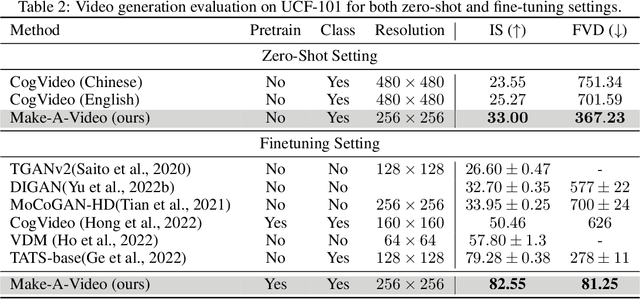
We propose Make-A-Video -- an approach for directly translating the tremendous recent progress in Text-to-Image (T2I) generation to Text-to-Video (T2V). Our intuition is simple: learn what the world looks like and how it is described from paired text-image data, and learn how the world moves from unsupervised video footage. Make-A-Video has three advantages: (1) it accelerates training of the T2V model (it does not need to learn visual and multimodal representations from scratch), (2) it does not require paired text-video data, and (3) the generated videos inherit the vastness (diversity in aesthetic, fantastical depictions, etc.) of today's image generation models. We design a simple yet effective way to build on T2I models with novel and effective spatial-temporal modules. First, we decompose the full temporal U-Net and attention tensors and approximate them in space and time. Second, we design a spatial temporal pipeline to generate high resolution and frame rate videos with a video decoder, interpolation model and two super resolution models that can enable various applications besides T2V. In all aspects, spatial and temporal resolution, faithfulness to text, and quality, Make-A-Video sets the new state-of-the-art in text-to-video generation, as determined by both qualitative and quantitative measures.
KNN-Diffusion: Image Generation via Large-Scale Retrieval
Apr 06, 2022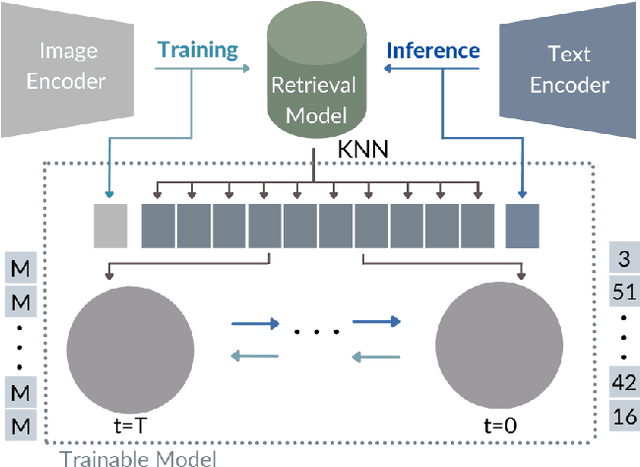
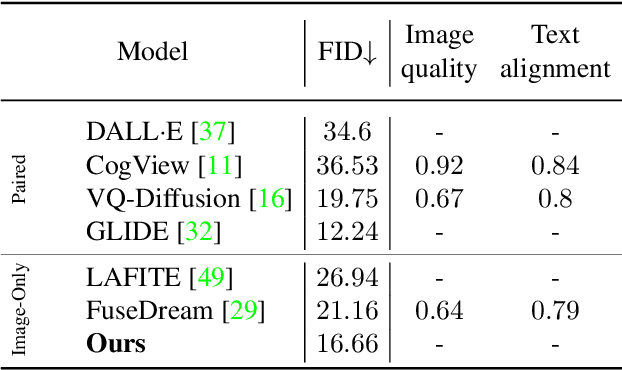
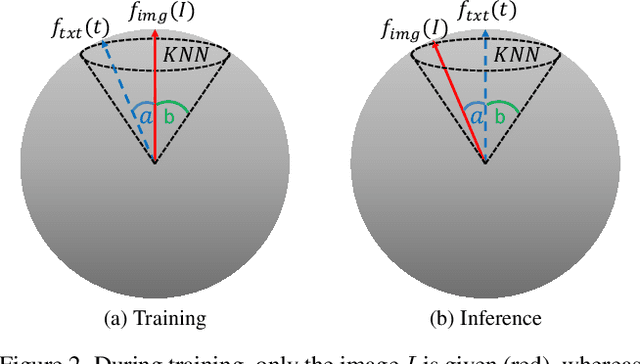

While the availability of massive Text-Image datasets is shown to be extremely useful in training large-scale generative models (e.g. DDPMs, Transformers), their output typically depends on the quality of both the input text, as well as the training dataset. In this work, we show how large-scale retrieval methods, in particular efficient K-Nearest-Neighbors (KNN) search, can be used in order to train a model to adapt to new samples. Learning to adapt enables several new capabilities. Sifting through billions of records at inference time is extremely efficient and can alleviate the need to train or memorize an adequately large generative model. Additionally, fine-tuning trained models to new samples can be achieved by simply adding them to the table. Rare concepts, even without any presence in the training set, can be then leveraged during test time without any modification to the generative model. Our diffusion-based model trains on images only, by leveraging a joint Text-Image multi-modal metric. Compared to baseline methods, our generations achieve state of the art results both in human evaluations as well as with perceptual scores when tested on a public multimodal dataset of natural images, as well as on a collected dataset of 400 million Stickers.
Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
Mar 24, 2022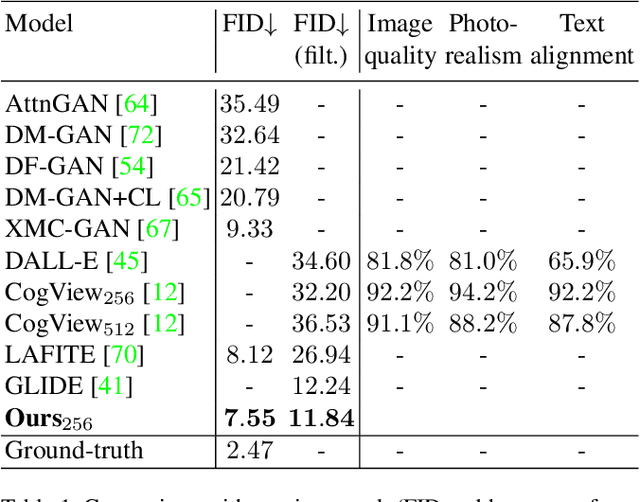

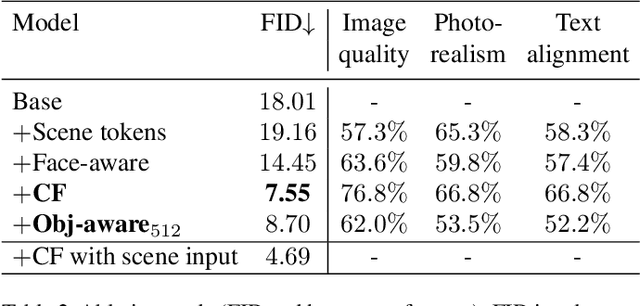

Recent text-to-image generation methods provide a simple yet exciting conversion capability between text and image domains. While these methods have incrementally improved the generated image fidelity and text relevancy, several pivotal gaps remain unanswered, limiting applicability and quality. We propose a novel text-to-image method that addresses these gaps by (i) enabling a simple control mechanism complementary to text in the form of a scene, (ii) introducing elements that substantially improve the tokenization process by employing domain-specific knowledge over key image regions (faces and salient objects), and (iii) adapting classifier-free guidance for the transformer use case. Our model achieves state-of-the-art FID and human evaluation results, unlocking the ability to generate high fidelity images in a resolution of 512x512 pixels, significantly improving visual quality. Through scene controllability, we introduce several new capabilities: (i) Scene editing, (ii) text editing with anchor scenes, (iii) overcoming out-of-distribution text prompts, and (iv) story illustration generation, as demonstrated in the story we wrote.
Single-Shot Freestyle Dance Reenactment
Dec 02, 2020
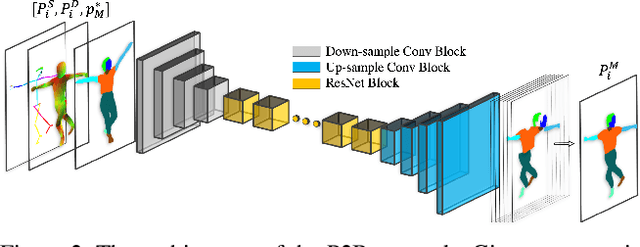
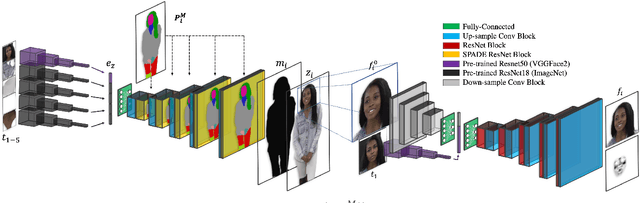

The task of motion transfer between a source dancer and a target person is a special case of the pose transfer problem, in which the target person changes their pose in accordance with the motions of the dancer. In this work, we propose a novel method that can reanimate a single image by arbitrary video sequences, unseen during training. The method combines three networks: (i) a segmentation-mapping network, (ii) a realistic frame-rendering network, and (iii) a face refinement network. By separating this task into three stages, we are able to attain a novel sequence of realistic frames, capturing natural motion and appearance. Our method obtains significantly better visual quality than previous methods and is able to animate diverse body types and appearances, which are captured in challenging poses, as shown in the experiments and supplementary video.
Specifying Object Attributes and Relations in Interactive Scene Generation
Sep 11, 2019
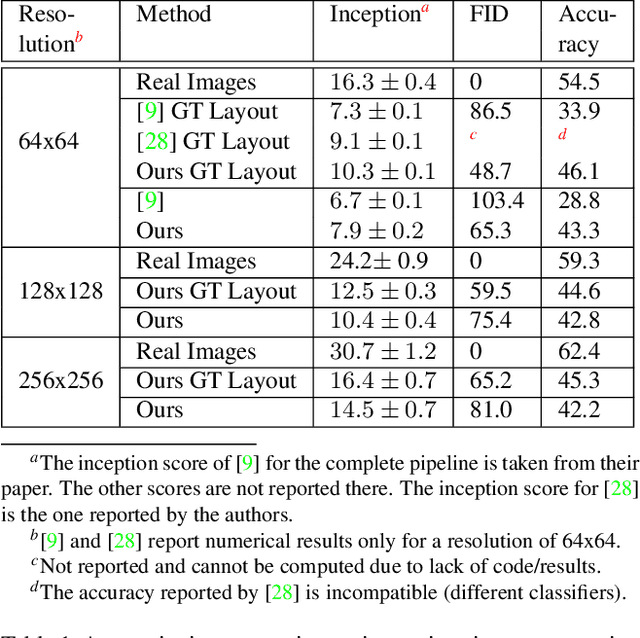
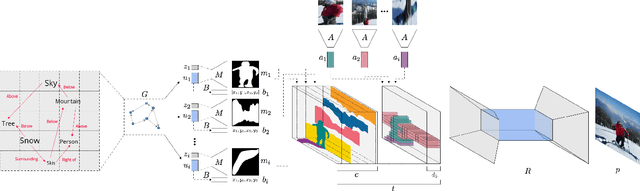
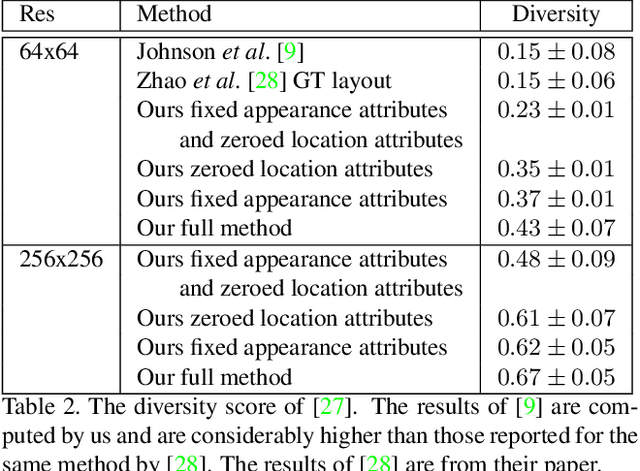
We introduce a method for the generation of images from an input scene graph. The method separates between a layout embedding and an appearance embedding. The dual embedding leads to generated images that better match the scene graph, have higher visual quality, and support more complex scene graphs. In addition, the embedding scheme supports multiple and diverse output images per scene graph, which can be further controlled by the user. We demonstrate two modes of per-object control: (i) importing elements from other images, and (ii) navigation in the object space, by selecting an appearance archetype. Our code is publicly available at https://www. github.com/ashual/scene_generation.