 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCR Synthetic Benchmark Dataset for Indic Languages
May 05, 2022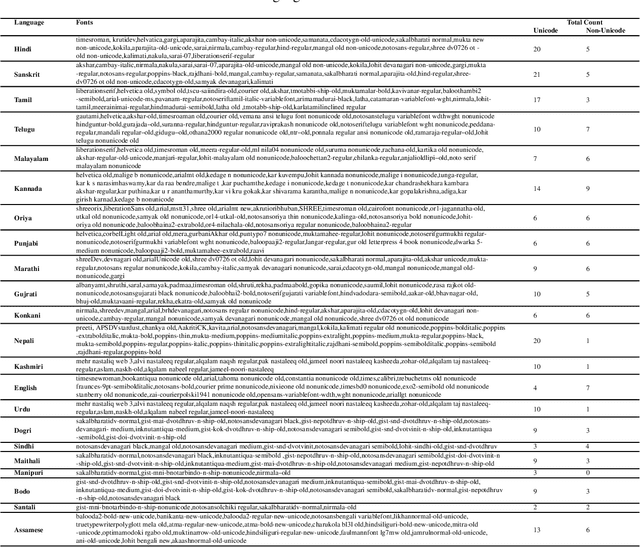
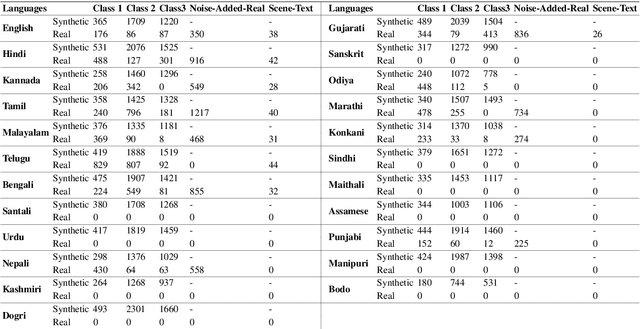
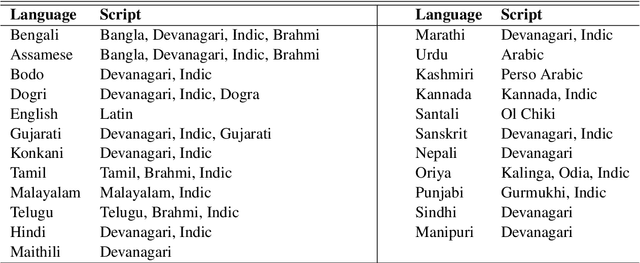
We present the largest publicly available synthetic OCR benchmark dataset for Indic languages. The collection contains a total of 90k images and their ground truth for 23 Indic languages. OCR model validation in Indic languages require a good amount of diverse data to be processed in order to create a robust and reliable model. Generating such a huge amount of data would be difficult otherwise but with synthetic data, it becomes far easier. It can be of great importance to fields like Computer Vision or Image Processing where once an initial synthetic data is developed, model creation becomes easier. Generating synthetic data comes with the flexibility to adjust its nature and environment as and when required in order to improve the performance of the model. Accuracy for labeled real-time data is sometimes quite expensive while accuracy for synthetic data can be easily achieved with a good score.
Samanantar: The Largest Publicly Available Parallel Corpora Collection for 11 Indic Languages
Apr 29, 2021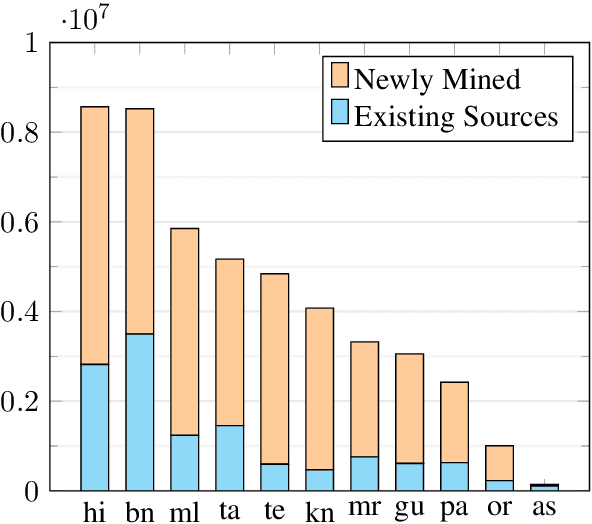
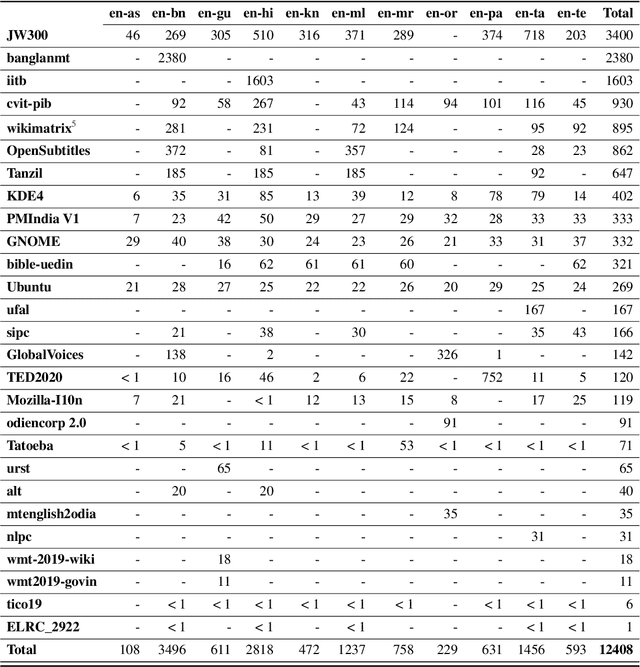
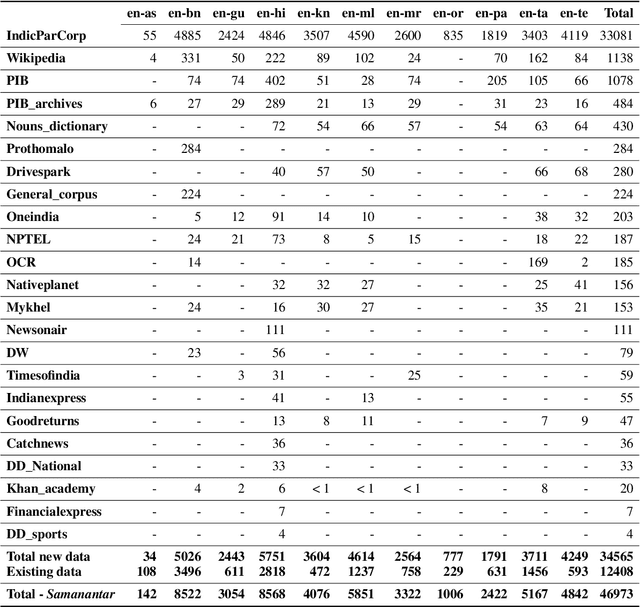
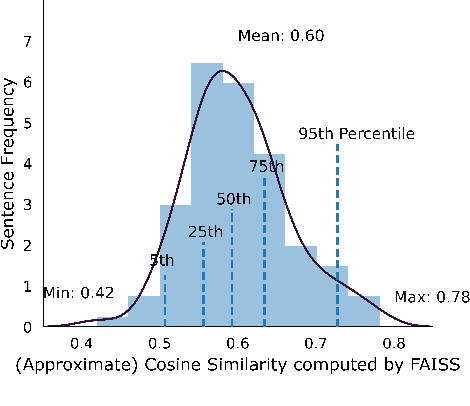
We present Samanantar, the largest publicly available parallel corpora collection for Indic languages. The collection contains a total of 46.9 million sentence pairs between English and 11 Indic languages (from two language families). In particular, we compile 12.4 million sentence pairs from existing, publicly-available parallel corpora, and we additionally mine 34.6 million sentence pairs from the web, resulting in a 2.8X increase in publicly available sentence pairs. We mine the parallel sentences from the web by combining many corpora, tools, and methods. In particular, we use (a) web-crawled monolingual corpora, (b) document OCR for extracting sentences from scanned documents (c) multilingual representation models for aligning sentences, and (d) approximate nearest neighbor search for searching in a large collection of sentences. Human evaluation of samples from the newly mined corpora validate the high quality of the parallel sentences across 11 language pairs. Further, we extracted 82.7 million sentence pairs between all 55 Indic language pairs from the English-centric parallel corpus using English as the pivot language. We trained multilingual NMT models spanning all these languages on Samanantar and compared with other baselines and previously reported results on publicly available benchmarks. Our models outperform existing models on these benchmarks, establishing the utility of Samanantar. Our data (https://indicnlp.ai4bharat.org/samanantar) and models (https://github.com/AI4Bharat/IndicTrans) will be available publicly and we hope they will help advance research in Indic NMT and multilingual NLP for Indic languages.