 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMwave: Wavelet-Driven Feature Enrichment for Effective Adaptation of Segment Anything Model
Jul 27, 2025The emergence of large foundation models has propelled significant advances in various domains. The Segment Anything Model (SAM), a leading model for image segmentation, exemplifies these advances, outperforming traditional methods. However, such foundation models often suffer from performance degradation when applied to complex tasks for which they are not trained. Existing methods typically employ adapter-based fine-tuning strategies to adapt SAM for tasks and leverage high-frequency features extracted from the Fourier domain. However, Our analysis reveals that these approaches offer limited benefits due to constraints in their feature extraction techniques. To overcome this, we propose \textbf{\textit{SAMwave}}, a novel and interpretable approach that utilizes the wavelet transform to extract richer, multi-scale high-frequency features from input data. Extending this, we introduce complex-valued adapters capable of capturing complex-valued spatial-frequency information via complex wavelet transforms. By adaptively integrating these wavelet coefficients, SAMwave enables SAM's encoder to capture information more relevant for dense prediction. Empirical evaluations on four challenging low-level vision tasks demonstrate that SAMwave significantly outperforms existing adaptation methods. This superior performance is consistent across both the SAM and SAM2 backbones and holds for both real and complex-valued adapter variants, highlighting the efficiency, flexibility, and interpretability of our proposed method for adapting segment anything models.
Improve Academic Query Resolution through BERT-based Question Extraction from Images
Apr 28, 2024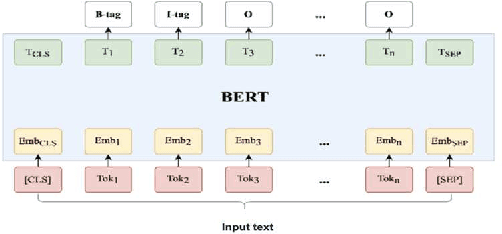

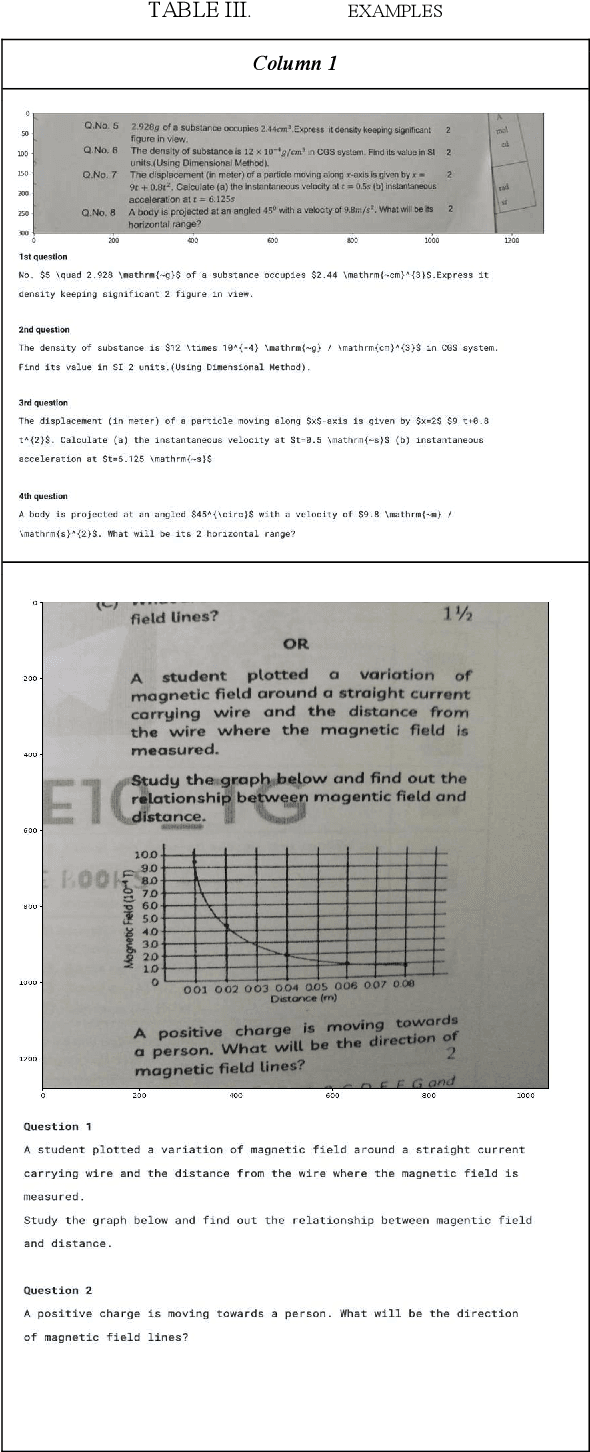
Providing fast and accurate resolution to the student's query is an essential solution provided by Edtech organizations. This is generally provided with a chat-bot like interface to enable students to ask their doubts easily. One preferred format for student queries is images, as it allows students to capture and post questions without typing complex equations and information. However, this format also presents difficulties, as images may contain multiple questions or textual noise that lowers the accuracy of existing single-query answering solutions. In this paper, we propose a method for extracting questions from text or images using a BERT-based deep learning model and compare it to the other rule-based and layout-based methods. Our method aims to improve the accuracy and efficiency of student query resolution in Edtech organizations.
OCR Synthetic Benchmark Dataset for Indic Languages
May 05, 2022
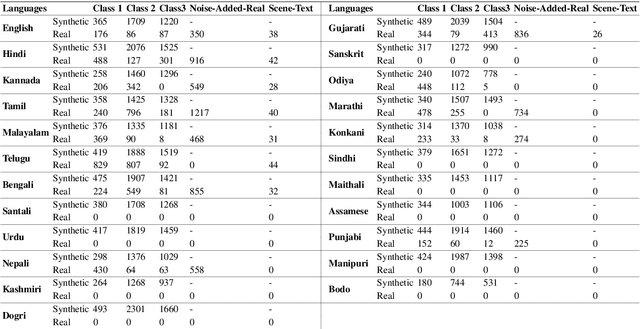
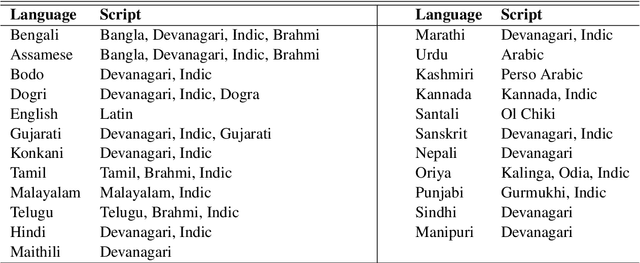
We present the largest publicly available synthetic OCR benchmark dataset for Indic languages. The collection contains a total of 90k images and their ground truth for 23 Indic languages. OCR model validation in Indic languages require a good amount of diverse data to be processed in order to create a robust and reliable model. Generating such a huge amount of data would be difficult otherwise but with synthetic data, it becomes far easier. It can be of great importance to fields like Computer Vision or Image Processing where once an initial synthetic data is developed, model creation becomes easier. Generating synthetic data comes with the flexibility to adjust its nature and environment as and when required in order to improve the performance of the model. Accuracy for labeled real-time data is sometimes quite expensive while accuracy for synthetic data can be easily achieved with a good score.