 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower Bounds for Chain-of-Thought Reasoning in Hard-Attention Transformers
Feb 04, 2025Chain-of-thought reasoning and scratchpads have emerged as critical tools for enhancing the computational capabilities of transformers. While theoretical results show that polynomial-length scratchpads can extend transformers' expressivity from $TC^0$ to $PTIME$, their required length remains poorly understood. Empirical evidence even suggests that transformers need scratchpads even for many problems in $TC^0$, such as Parity or Multiplication, challenging optimistic bounds derived from circuit complexity. In this work, we initiate the study of systematic lower bounds for the number of CoT steps across different algorithmic problems, in the hard-attention regime. We study a variety of algorithmic problems, and provide bounds that are tight up to logarithmic factors. Overall, these results contribute to emerging understanding of the power and limitations of chain-of-thought reasoning.
Why are Sensitive Functions Hard for Transformers?
Feb 25, 2024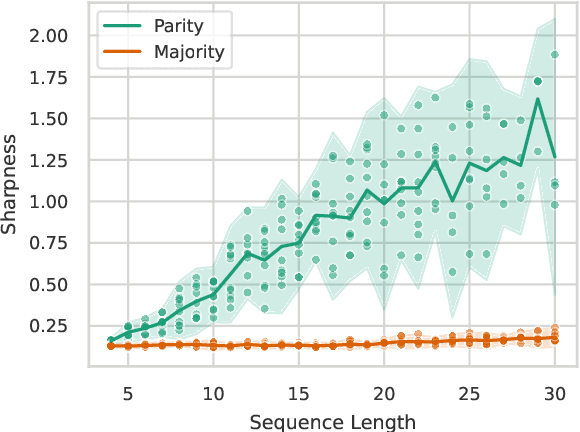



Empirical studies have identified a range of learnability biases and limitations of transformers, such as a persistent difficulty in learning to compute simple formal languages such as PARITY, and a bias towards low-degree functions. However, theoretical understanding remains limited, with existing expressiveness theory either overpredicting or underpredicting realistic learning abilities. We prove that, under the transformer architecture, the loss landscape is constrained by the input-space sensitivity: Transformers whose output is sensitive to many parts of the input string inhabit isolated points in parameter space, leading to a low-sensitivity bias in generalization. We show theoretically and empirically that this theory unifies a broad array of empirical observations about the learning abilities and biases of transformers, such as their generalization bias towards low sensitivity and low degree, and difficulty in length generalization for PARITY. This shows that understanding transformers' inductive biases requires studying not just their in-principle expressivity, but also their loss landscape.
Linear Interpolation In Parameter Space is Good Enough for Fine-Tuned Language Models
Nov 22, 2022The simplest way to obtain continuous interpolation between two points in high dimensional space is to draw a line between them. While previous works focused on the general connectivity between model parameters, we explored linear interpolation for parameters of pre-trained models after fine-tuning. Surprisingly, we could perform linear interpolation without a performance drop in intermediate points for fine-tuned models. For controllable text generation, such interpolation could be seen as moving a model towards or against the desired text attribute (e.g., positive sentiment), which could be used as grounds for further methods for controllable text generation without inference speed overhead.
Vote'n'Rank: Revision of Benchmarking with Social Choice Theory
Oct 13, 2022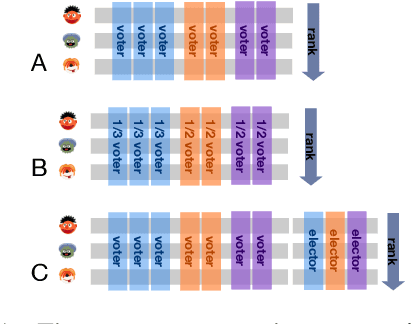
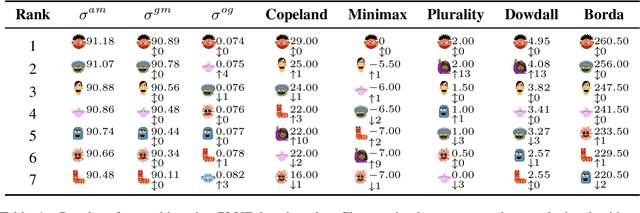

The development of state-of-the-art systems in different applied areas of machine learning (ML) is driven by benchmarks, which have shaped the paradigm of evaluating generalisation capabilities from multiple perspectives. Although the paradigm is shifting towards more fine-grained evaluation across diverse tasks, the delicate question of how to aggregate the performances has received particular interest in the community. In general, benchmarks follow the unspoken utilitarian principles, where the systems are ranked based on their mean average score over task-specific metrics. Such aggregation procedure has been viewed as a sub-optimal evaluation protocol, which may have created the illusion of progress. This paper proposes Vote'n'Rank, a framework for ranking systems in multi-task benchmarks under the principles of the social choice theory. We demonstrate that our approach can be efficiently utilised to draw new insights on benchmarking in several ML sub-fields and identify the best-performing systems in research and development case studies. The Vote'n'Rank's procedures are more robust than the mean average while being able to handle missing performance scores and determine conditions under which the system becomes the winner.