 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnstable Features, Reproducible Subspaces: Understanding Seed Dependence in Sparse Autoencoders
Jun 10, 2026Sparse autoencoders (SAEs) are widely used to interpret neural network representations, but their utility depends on whether the learned features are reproducible across training runs. We study this question through \emph{feature stability}: for each SAE feature, we estimate the probability that a similar feature reappears in an independently trained SAE. This yields a scalable per-feature signal that separates stable from unstable features. In a large-scale study across seeds, models, layers, dictionary sizes, and SAE variants, we find a pronounced functional asymmetry: stable features carry most of the reconstruction- and prediction-relevant signal, while unstable features have weak marginal impact and are dominated by low-frequency surface-form triggers in both activation statistics and automatic explanations. Geometrically, unstable features are individually non-reproducible but concentrate in reproducible lower-rank subspaces, suggesting that seed dependence often reflects basis ambiguity within a shared region of activation space rather than pure noise. A controlled synthetic model makes this mechanism explicit, showing that low-rank ground-truth features can be recovered at the subspace level while remaining non-identifiable as individual SAE latents across seeds. Finally, by pooling unique cross-seed features, we construct more stable SAEs while preserving explained variance in this setting. Together, these results show that unstable features are not merely failed or noisy latents: they have weak individual functional impact, but reflect reproducible low-dimensional structure that standard SAEs resolve differently across seeds.
Interpreting and Steering a Text-to-Speech Language Model with Sparse Autoencoders
Jun 08, 2026Language models increasingly serve as the backbone of text-to-speech (TTS) systems, yet we understand little about the representations they build when text and generated speech tokens share a single residual stream. We train BatchTopK sparse autoencoders on the LM backbone of CosyVoice3 and introduce a modality-aware auto-interp pipeline that labels each feature from where it fires-text-prefix context, 1-second speech clips, or both. The recovered features are interpretable, spanning phonemes, laughter, accent prompts and speaker gender. Steering through the SAE latent space shows these features are causal rather than merely descriptive: targeted interventions raise laughter probability from 0.02 to 0.79, flip perceived speaker gender, and control speech rate while preserving spoken content. SAE features thus serve both as interpretability objects and as control directions for TTS synthesis.
Trust-Region Behavior Blending for On-Policy Distillation
May 29, 2026On-policy distillation (OPD) trains a student on prefixes sampled from its own policy while matching a stronger teacher. This addresses the prefix mismatch of offline distillation, but early student rollouts can still be poor, placing teacher supervision on weak or low-quality prefixes. We propose Trust-Region behavior Blending (TRB), a warmup method that replaces the early rollout policy with the closest-to-teacher behavior policy inside a student-centered KL trust region, while keeping the per-prefix reverse-KL OPD loss unchanged. The KL budget is annealed to zero, so training returns to pure student rollouts after warmup. Across two math-reasoning distillation settings, TRB attains the strongest average among the compared methods.
Next Embedding Prediction Makes World Models Stronger
Mar 03, 2026Capturing temporal dependencies is critical for model-based reinforcement learning (MBRL) in partially observable, high-dimensional domains. We introduce NE-Dreamer, a decoder-free MBRL agent that leverages a temporal transformer to predict next-step encoder embeddings from latent state sequences, directly optimizing temporal predictive alignment in representation space. This approach enables NE-Dreamer to learn coherent, predictive state representations without reconstruction losses or auxiliary supervision. On the DeepMind Control Suite, NE-Dreamer matches or exceeds the performance of DreamerV3 and leading decoder-free agents. On a challenging subset of DMLab tasks involving memory and spatial reasoning, NE-Dreamer achieves substantial gains. These results establish next-embedding prediction with temporal transformers as an effective, scalable framework for MBRL in complex, partially observable environments.
Teach Old SAEs New Domain Tricks with Boosting
Jul 17, 2025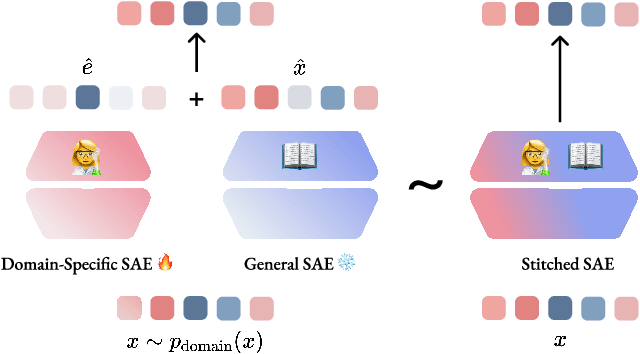
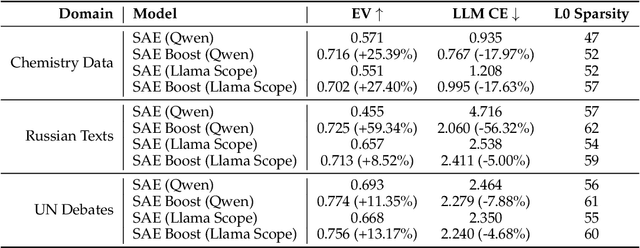
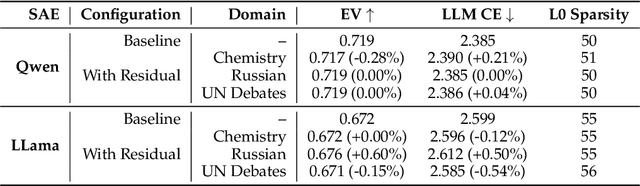
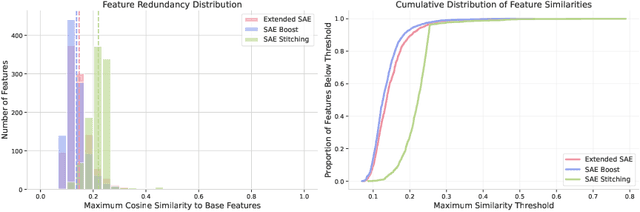
Sparse Autoencoders have emerged as powerful tools for interpreting the internal representations of Large Language Models, yet they often fail to capture domain-specific features not prevalent in their training corpora. This paper introduces a residual learning approach that addresses this feature blindness without requiring complete retraining. We propose training a secondary SAE specifically to model the reconstruction error of a pretrained SAE on domain-specific texts, effectively capturing features missed by the primary model. By summing the outputs of both models during inference, we demonstrate significant improvements in both LLM cross-entropy and explained variance metrics across multiple specialized domains. Our experiments show that this method efficiently incorporates new domain knowledge into existing SAEs while maintaining their performance on general tasks. This approach enables researchers to selectively enhance SAE interpretability for specific domains of interest, opening new possibilities for targeted mechanistic interpretability of LLMs.
Train One Sparse Autoencoder Across Multiple Sparsity Budgets to Preserve Interpretability and Accuracy
May 30, 2025Sparse Autoencoders (SAEs) have proven to be powerful tools for interpreting neural networks by decomposing hidden representations into disentangled, interpretable features via sparsity constraints. However, conventional SAEs are constrained by the fixed sparsity level chosen during training; meeting different sparsity requirements therefore demands separate models and increases the computational footprint during both training and evaluation. We introduce a novel training objective, \emph{HierarchicalTopK}, which trains a single SAE to optimise reconstructions across multiple sparsity levels simultaneously. Experiments with Gemma-2 2B demonstrate that our approach achieves Pareto-optimal trade-offs between sparsity and explained variance, outperforming traditional SAEs trained at individual sparsity levels. Further analysis shows that HierarchicalTopK preserves high interpretability scores even at higher sparsity. The proposed objective thus closes an important gap between flexibility and interpretability in SAE design.
Train Sparse Autoencoders Efficiently by Utilizing Features Correlation
May 28, 2025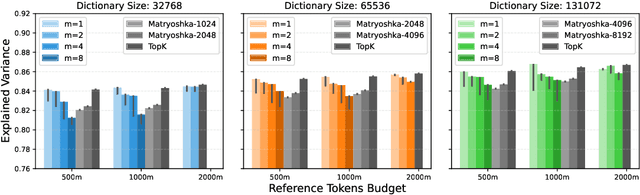
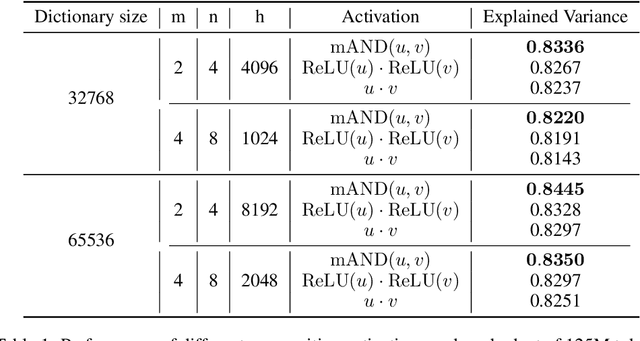
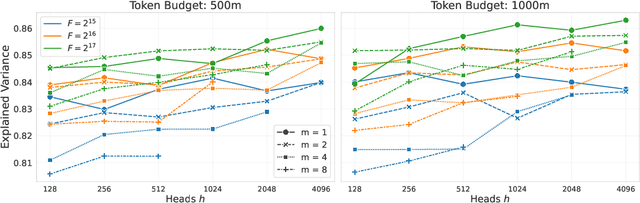
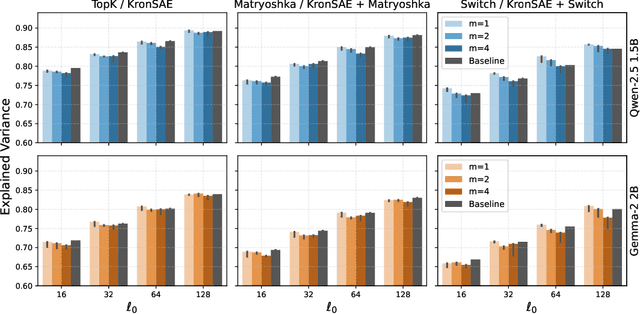
Sparse Autoencoders (SAEs) have demonstrated significant promise in interpreting the hidden states of language models by decomposing them into interpretable latent directions. However, training SAEs at scale remains challenging, especially when large dictionary sizes are used. While decoders can leverage sparse-aware kernels for efficiency, encoders still require computationally intensive linear operations with large output dimensions. To address this, we propose KronSAE, a novel architecture that factorizes the latent representation via Kronecker product decomposition, drastically reducing memory and computational overhead. Furthermore, we introduce mAND, a differentiable activation function approximating the binary AND operation, which improves interpretability and performance in our factorized framework.
Steering LLM Reasoning Through Bias-Only Adaptation
May 24, 2025


Recent work on reasoning-oriented language models, exemplified by o1-like systems, suggests that reinforcement-learning (RL) finetuning does not create new capabilities but instead strengthens reasoning patterns already latent in the pretrained network. We test this claim by training steering vectors: layer-wise biases that additively amplify selected hidden features while leaving all original weights unchanged. Experiments on four base models across the GSM8K and MATH benchmarks show that steering vectors recover, and in several cases exceed, the accuracy of fully-tuned counterparts. This result supports the view that the required reasoning skills pre-exist in the base model. Further, logit-lens analysis reveals that the trained vectors consistently boost token groups linked to structured languages and logical connectors, providing an interpretable account that aligns with the demands of quantitative reasoning tasks.
You Do Not Fully Utilize Transformer's Representation Capacity
Feb 13, 2025



In contrast to RNNs, which compress previous tokens into a single hidden state, Transformers can attend to all previous tokens directly. However, standard Transformers only use representations from the immediately preceding layer. In this paper, we show that this design choice causes representation collapse and leads to suboptimal performance. To address this issue, we introduce Layer-Integrated Memory (LIMe), a simple yet powerful approach that preserves the model's overall memory footprint while expanding its representational capacity by allowing access to hidden states from earlier layers. Through extensive experiments across various architectures and different lookup mechanisms, we demonstrate consistent performance improvements on a wide range of tasks. Moreover, our analysis of the learned representation dynamics and our exploration of depthwise circuits reveal how LIMe integrates information across layers, pointing to promising directions for future research.
Analyze Feature Flow to Enhance Interpretation and Steering in Language Models
Feb 06, 2025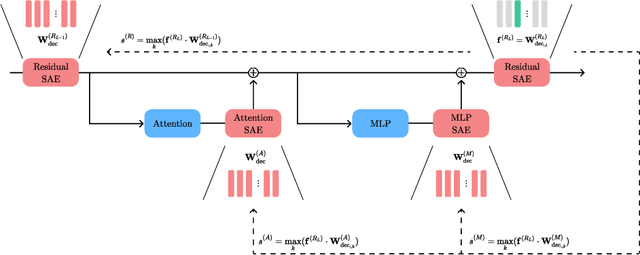

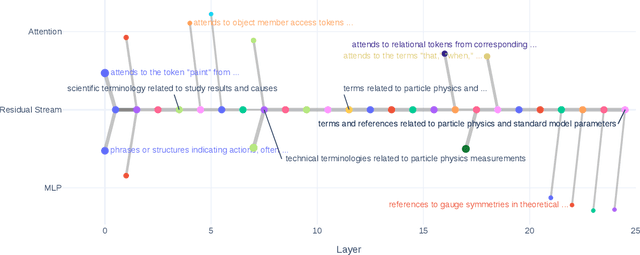

We introduce a new approach to systematically map features discovered by sparse autoencoder across consecutive layers of large language models, extending earlier work that examined inter-layer feature links. By using a data-free cosine similarity technique, we trace how specific features persist, transform, or first appear at each stage. This method yields granular flow graphs of feature evolution, enabling fine-grained interpretability and mechanistic insights into model computations. Crucially, we demonstrate how these cross-layer feature maps facilitate direct steering of model behavior by amplifying or suppressing chosen features, achieving targeted thematic control in text generation. Together, our findings highlight the utility of a causal, cross-layer interpretability framework that not only clarifies how features develop through forward passes but also provides new means for transparent manipulation of large language models.