 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering LLM Reasoning Through Bias-Only Adaptation
May 24, 2025Recent work on reasoning-oriented language models, exemplified by o1-like systems, suggests that reinforcement-learning (RL) finetuning does not create new capabilities but instead strengthens reasoning patterns already latent in the pretrained network. We test this claim by training steering vectors: layer-wise biases that additively amplify selected hidden features while leaving all original weights unchanged. Experiments on four base models across the GSM8K and MATH benchmarks show that steering vectors recover, and in several cases exceed, the accuracy of fully-tuned counterparts. This result supports the view that the required reasoning skills pre-exist in the base model. Further, logit-lens analysis reveals that the trained vectors consistently boost token groups linked to structured languages and logical connectors, providing an interpretable account that aligns with the demands of quantitative reasoning tasks.
The Differences Between Direct Alignment Algorithms are a Blur
Feb 03, 2025Direct Alignment Algorithms (DAAs) simplify language model alignment by replacing reinforcement learning (RL) and reward modeling (RM) in Reinforcement Learning from Human Feedback (RLHF) with direct policy optimization. DAAs can be classified by their ranking losses (pairwise vs. pointwise), by the rewards used in those losses (e.g., likelihood ratios of policy and reference policy, or odds ratios), or by whether a Supervised Fine-Tuning (SFT) phase is required (two-stage vs. one-stage). We first show that one-stage methods underperform two-stage methods. To address this, we incorporate an explicit SFT phase and introduce the $\beta$ parameter, controlling the strength of preference optimization, into single-stage ORPO and ASFT. These modifications improve their performance in Alpaca Eval 2 by +$3.46$ (ORPO) and +$8.27$ (ASFT), matching two-stage methods like DPO. Further analysis reveals that the key factor is whether the approach uses pairwise or pointwise objectives, rather than the specific implicit reward or loss function. These results highlight the importance of careful evaluation to avoid premature claims of performance gains or overall superiority in alignment algorithms.
Learn Your Reference Model for Real Good Alignment
Apr 15, 2024The complexity of the alignment problem stems from the fact that existing methods are unstable. Researchers continuously invent various tricks to address this shortcoming. For instance, in the fundamental Reinforcement Learning From Human Feedback (RLHF) technique of Language Model alignment, in addition to reward maximization, the Kullback-Leibler divergence between the trainable policy and the SFT policy is minimized. This addition prevents the model from being overfitted to the Reward Model (RM) and generating texts that are out-of-domain for the RM. The Direct Preference Optimization (DPO) method reformulates the optimization task of RLHF and eliminates the Reward Model while tacitly maintaining the requirement for the policy to be close to the SFT policy. In our paper, we argue that this implicit limitation in the DPO method leads to sub-optimal results. We propose a new method called Trust Region DPO (TR-DPO), which updates the reference policy during training. With such a straightforward update, we demonstrate the effectiveness of TR-DPO against DPO on the Anthropic HH and TLDR datasets. We show that TR-DPO outperforms DPO by up to 19%, measured by automatic evaluation with GPT-4. The new alignment approach that we propose allows us to improve the quality of models across several parameters at once, such as coherence, correctness, level of detail, helpfulness, and harmlessness.
Linear Transformers with Learnable Kernel Functions are Better In-Context Models
Feb 16, 2024



Advancing the frontier of subquadratic architectures for Language Models (LMs) is crucial in the rapidly evolving field of natural language processing. Current innovations, including State Space Models, were initially celebrated for surpassing Transformer performance on language modeling tasks. However, these models have revealed deficiencies in essential In-Context Learning capabilities - a domain where the Transformer traditionally shines. The Based model emerged as a hybrid solution, blending a Linear Transformer with a kernel inspired by the Taylor expansion of exponential functions, augmented by convolutional networks. Mirroring the Transformer's in-context adeptness, it became a strong contender in the field. In our work, we present a singular, elegant alteration to the Based kernel that amplifies its In-Context Learning abilities evaluated with the Multi-Query Associative Recall task and overall language modeling process, as demonstrated on the Pile dataset.
Reinforcement learning for question answering in programming domain using public community scoring as a human feedback
Jan 19, 2024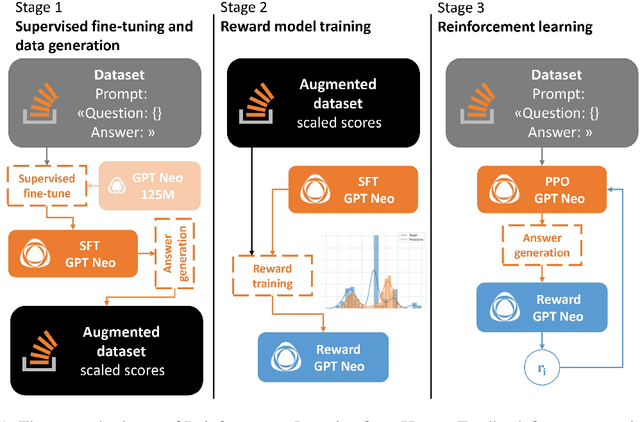



In this study, we investigate the enhancement of the GPT Neo 125M performance in Community Question Answering (CQA) with a focus on programming, through the integration of Reinforcement Learning from Human Feedback (RLHF) and the utilization of scores from Stack Overflow. Two distinct reward model training strategies are employed for fine-tuning with Proximal Policy Optimization (PPO). Notably, the improvements in performance achieved through this method are comparable to those of GPT Neo 2.7B parameter variant. Additionally, an auxiliary scoring mechanism is introduced, which demonstrates the limitations of conventional linguistic metrics in evaluating responses in the programming domain. Through accurate analysis, this paper looks at the divergence between traditional linguistic metrics and our human-preferences-based reward model, underscoring the imperative for domain-specific evaluation methods. By elucidating the complexities involved in applying RLHF to programming CQA and accentuating the significance of context-aware evaluation, this study contributes to the ongoing efforts in refining Large Language Models through focused human feedback.
Bayesian Networks for Named Entity Prediction in Programming Community Question Answering
Feb 26, 2023Within this study, we propose a new approach for natural language processing using Bayesian networks to predict and analyze the context and how this approach can be applied to the Community Question Answering domain. We discuss how Bayesian networks can detect semantic relationships and dependencies between entities, and this is connected to different score-based approaches of structure-learning. We compared the Bayesian networks with different score metrics, such as the BIC, BDeu, K2 and Chow-Liu trees. Our proposed approach out-performs the baseline model at the precision metric. We also discuss the influence of penalty terms on the structure of Bayesian networks and how they can be used to analyze the relationships between entities. In addition, we examine the visualization of directed acyclic graphs to analyze semantic relationships. The article further identifies issues with detecting certain semantic classes that are separated in the structure of directed acyclic graphs. Finally, we evaluate potential improvements for the Bayesian network approach.