 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArkTS-CodeSearch: A Open-Source ArkTS Dataset for Code Retrieval
Feb 05, 2026ArkTS is a core programming language in the OpenHarmony ecosystem, yet research on ArkTS code intelligence is hindered by the lack of public datasets and evaluation benchmarks. This paper presents a large-scale ArkTS dataset constructed from open-source repositories, targeting code retrieval and code evaluation tasks. We design a single-search task, where natural language comments are used to retrieve corresponding ArkTS functions. ArkTS repositories are crawled from GitHub and Gitee, and comment-function pairs are extracted using tree-sitter-arkts, followed by cross-platform deduplication and statistical analysis of ArkTS function types. We further evaluate all existing open-source code embedding models on the single-search task and perform fine-tuning using both ArkTS and TypeScript training datasets, resulting in a high-performing model for ArkTS code understanding. This work establishes the first systematic benchmark for ArkTS code retrieval. Both the dataset and our fine-tuned model will be released publicly and are available at https://huggingface.co/hreyulog/embedinggemma_arkts and https://huggingface.co/datasets/hreyulog/arkts-code-docstring,establishing the first systematic benchmark for ArkTS code retrieval.
Style2Code: A Style-Controllable Code Generation Framework with Dual-Modal Contrastive Representation Learning
May 26, 2025Controllable code generation, the ability to synthesize code that follows a specified style while maintaining functionality, remains a challenging task. We propose a two-stage training framework combining contrastive learning and conditional decoding to enable flexible style control. The first stage aligns code style representations with semantic and structural features. In the second stage, we fine-tune a language model (e.g., Flan-T5) conditioned on the learned style vector to guide generation. Our method supports style interpolation and user personalization via lightweight mixing. Compared to prior work, our unified framework offers improved stylistic control without sacrificing code correctness. This is among the first approaches to combine contrastive alignment with conditional decoding for style-guided code generation.
Multi-Agent Norm Perception and Induction in Distributed Healthcare
Dec 24, 2024



This paper presents a Multi-Agent Norm Perception and Induction Learning Model aimed at facilitating the integration of autonomous agent systems into distributed healthcare environments through dynamic interaction processes. The nature of the medical norm system and its sharing channels necessitates distinct approaches for Multi-Agent Systems to learn two types of norms. Building on this foundation, the model enables agents to simultaneously learn descriptive norms, which capture collective tendencies, and prescriptive norms, which dictate ideal behaviors. Through parameterized mixed probability density models and practice-enhanced Markov games, the multi-agent system perceives descriptive norms in dynamic interactions and captures emergent prescriptive norms. We conducted experiments using a dataset from a neurological medical center spanning from 2016 to 2020.
Reinforcement learning for question answering in programming domain using public community scoring as a human feedback
Jan 19, 2024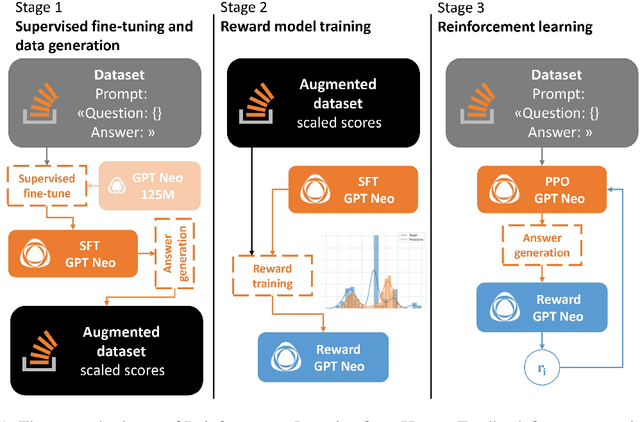



In this study, we investigate the enhancement of the GPT Neo 125M performance in Community Question Answering (CQA) with a focus on programming, through the integration of Reinforcement Learning from Human Feedback (RLHF) and the utilization of scores from Stack Overflow. Two distinct reward model training strategies are employed for fine-tuning with Proximal Policy Optimization (PPO). Notably, the improvements in performance achieved through this method are comparable to those of GPT Neo 2.7B parameter variant. Additionally, an auxiliary scoring mechanism is introduced, which demonstrates the limitations of conventional linguistic metrics in evaluating responses in the programming domain. Through accurate analysis, this paper looks at the divergence between traditional linguistic metrics and our human-preferences-based reward model, underscoring the imperative for domain-specific evaluation methods. By elucidating the complexities involved in applying RLHF to programming CQA and accentuating the significance of context-aware evaluation, this study contributes to the ongoing efforts in refining Large Language Models through focused human feedback.
Bayesian Networks for Named Entity Prediction in Programming Community Question Answering
Feb 26, 2023Within this study, we propose a new approach for natural language processing using Bayesian networks to predict and analyze the context and how this approach can be applied to the Community Question Answering domain. We discuss how Bayesian networks can detect semantic relationships and dependencies between entities, and this is connected to different score-based approaches of structure-learning. We compared the Bayesian networks with different score metrics, such as the BIC, BDeu, K2 and Chow-Liu trees. Our proposed approach out-performs the baseline model at the precision metric. We also discuss the influence of penalty terms on the structure of Bayesian networks and how they can be used to analyze the relationships between entities. In addition, we examine the visualization of directed acyclic graphs to analyze semantic relationships. The article further identifies issues with detecting certain semantic classes that are separated in the structure of directed acyclic graphs. Finally, we evaluate potential improvements for the Bayesian network approach.
Automated Spelling Correction for Clinical Text Mining in Russian
Apr 10, 2020



The main goal of this paper is to develop a spell checker module for clinical text in Russian. The described approach combines string distance measure algorithms with technics of machine learning embedding methods. Our overall precision is 0.86, lexical precision - 0.975 and error precision is 0.74. We develop spell checker as a part of medical text mining tool regarding the problems of misspelling, negation, experiencer and temporality detection.
Negation Detection for Clinical Text Mining in Russian
Apr 10, 2020



Developing predictive modeling in medicine requires additional features from unstructured clinical texts. In Russia, there are no instruments for natural language processing to cope with problems of medical records. This paper is devoted to a module of negation detection. The corpus-free machine learning method is based on gradient boosting classifier is used to detect whether a disease is denied, not mentioned or presented in the text. The detector classifies negations for five diseases and shows average F-score from 0.81 to 0.93. The benefits of negation detection have been demonstrated by predicting the presence of surgery for patients with the acute coronary syndrome.