 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement learning for question answering in programming domain using public community scoring as a human feedback
Paper and Code
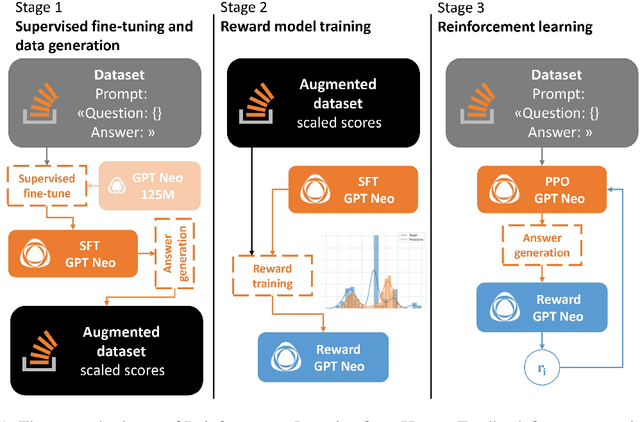



In this study, we investigate the enhancement of the GPT Neo 125M performance in Community Question Answering (CQA) with a focus on programming, through the integration of Reinforcement Learning from Human Feedback (RLHF) and the utilization of scores from Stack Overflow. Two distinct reward model training strategies are employed for fine-tuning with Proximal Policy Optimization (PPO). Notably, the improvements in performance achieved through this method are comparable to those of GPT Neo 2.7B parameter variant. Additionally, an auxiliary scoring mechanism is introduced, which demonstrates the limitations of conventional linguistic metrics in evaluating responses in the programming domain. Through accurate analysis, this paper looks at the divergence between traditional linguistic metrics and our human-preferences-based reward model, underscoring the imperative for domain-specific evaluation methods. By elucidating the complexities involved in applying RLHF to programming CQA and accentuating the significance of context-aware evaluation, this study contributes to the ongoing efforts in refining Large Language Models through focused human feedback.