 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage as the Medium: Multimodal Video Classification through text only
Sep 19, 2023Despite an exciting new wave of multimodal machine learning models, current approaches still struggle to interpret the complex contextual relationships between the different modalities present in videos. Going beyond existing methods that emphasize simple activities or objects, we propose a new model-agnostic approach for generating detailed textual descriptions that captures multimodal video information. Our method leverages the extensive knowledge learnt by large language models, such as GPT-3.5 or Llama2, to reason about textual descriptions of the visual and aural modalities, obtained from BLIP-2, Whisper and ImageBind. Without needing additional finetuning of video-text models or datasets, we demonstrate that available LLMs have the ability to use these multimodal textual descriptions as proxies for ``sight'' or ``hearing'' and perform zero-shot multimodal classification of videos in-context. Our evaluations on popular action recognition benchmarks, such as UCF-101 or Kinetics, show these context-rich descriptions can be successfully used in video understanding tasks. This method points towards a promising new research direction in multimodal classification, demonstrating how an interplay between textual, visual and auditory machine learning models can enable more holistic video understanding.
Efficient Multi-Modal Embeddings from Structured Data
Oct 06, 2021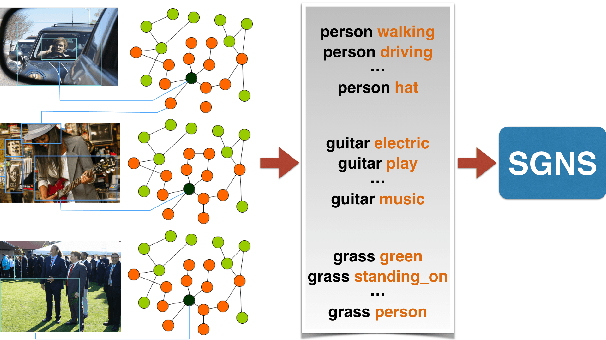

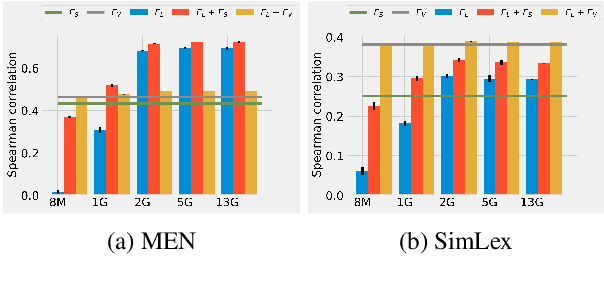
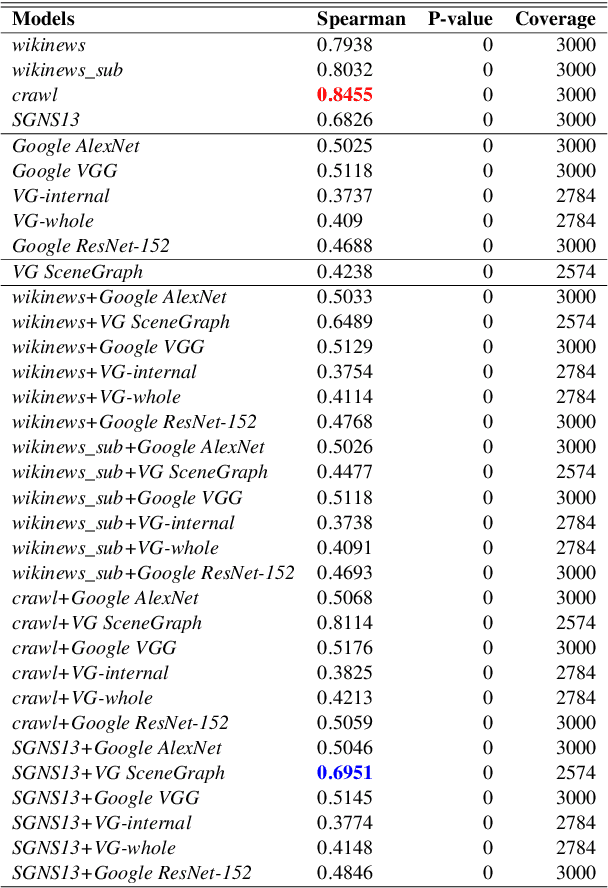
Multi-modal word semantics aims to enhance embeddings with perceptual input, assuming that human meaning representation is grounded in sensory experience. Most research focuses on evaluation involving direct visual input, however, visual grounding can contribute to linguistic applications as well. Another motivation for this paper is the growing need for more interpretable models and for evaluating model efficiency regarding size and performance. This work explores the impact of visual information for semantics when the evaluation involves no direct visual input, specifically semantic similarity and relatedness. We investigate a new embedding type in-between linguistic and visual modalities, based on the structured annotations of Visual Genome. We compare uni- and multi-modal models including structured, linguistic and image based representations. We measure the efficiency of each model with regard to data and model size, modality / data distribution and information gain. The analysis includes an interpretation of embedding structures. We found that this new embedding conveys complementary information for text based embeddings. It achieves comparable performance in an economic way, using orders of magnitude less resources than visual models.