 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage as the Medium: Multimodal Video Classification through text only
Sep 19, 2023Despite an exciting new wave of multimodal machine learning models, current approaches still struggle to interpret the complex contextual relationships between the different modalities present in videos. Going beyond existing methods that emphasize simple activities or objects, we propose a new model-agnostic approach for generating detailed textual descriptions that captures multimodal video information. Our method leverages the extensive knowledge learnt by large language models, such as GPT-3.5 or Llama2, to reason about textual descriptions of the visual and aural modalities, obtained from BLIP-2, Whisper and ImageBind. Without needing additional finetuning of video-text models or datasets, we demonstrate that available LLMs have the ability to use these multimodal textual descriptions as proxies for ``sight'' or ``hearing'' and perform zero-shot multimodal classification of videos in-context. Our evaluations on popular action recognition benchmarks, such as UCF-101 or Kinetics, show these context-rich descriptions can be successfully used in video understanding tasks. This method points towards a promising new research direction in multimodal classification, demonstrating how an interplay between textual, visual and auditory machine learning models can enable more holistic video understanding.
VTC: Improving Video-Text Retrieval with User Comments
Oct 19, 2022
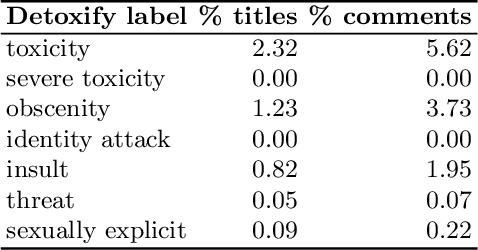
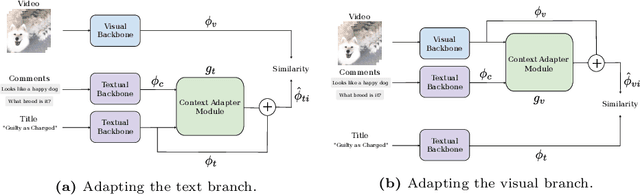
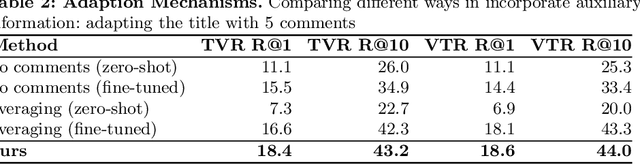
Multi-modal retrieval is an important problem for many applications, such as recommendation and search. Current benchmarks and even datasets are often manually constructed and consist of mostly clean samples where all modalities are well-correlated with the content. Thus, current video-text retrieval literature largely focuses on video titles or audio transcripts, while ignoring user comments, since users often tend to discuss topics only vaguely related to the video. Despite the ubiquity of user comments online, there is currently no multi-modal representation learning datasets that includes comments. In this paper, we a) introduce a new dataset of videos, titles and comments; b) present an attention-based mechanism that allows the model to learn from sometimes irrelevant data such as comments; c) show that by using comments, our method is able to learn better, more contextualised, representations for image, video and audio representations. Project page: https://unitaryai.github.io/vtc-paper.