 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CLC-UKET Dataset: Benchmarking Case Outcome Prediction for the UK Employment Tribunal
Sep 12, 2024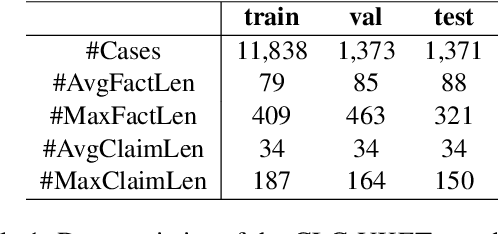
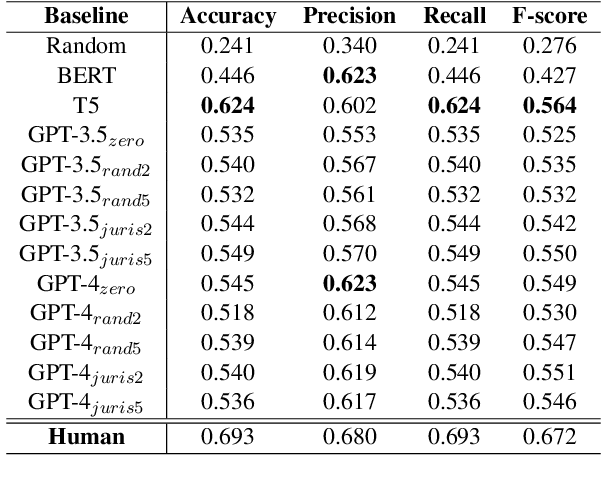
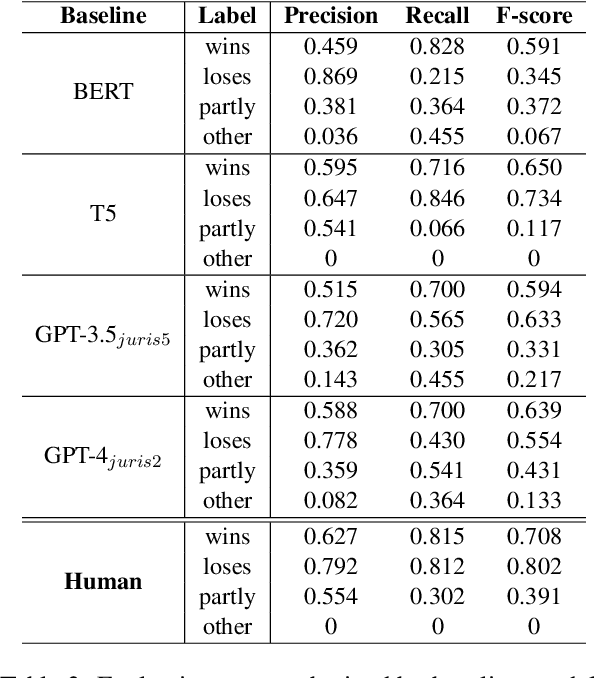
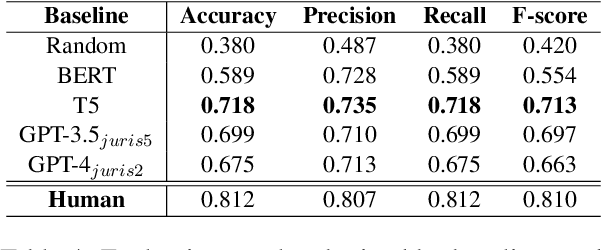
This paper explores the intersection of technological innovation and access to justice by developing a benchmark for predicting case outcomes in the UK Employment Tribunal (UKET). To address the challenge of extensive manual annotation, the study employs a large language model (LLM) for automatic annotation, resulting in the creation of the CLC-UKET dataset. The dataset consists of approximately 19,000 UKET cases and their metadata. Comprehensive legal annotations cover facts, claims, precedent references, statutory references, case outcomes, reasons and jurisdiction codes. Facilitated by the CLC-UKET data, we examine a multi-class case outcome prediction task in the UKET. Human predictions are collected to establish a performance reference for model comparison. Empirical results from baseline models indicate that finetuned transformer models outperform zero-shot and few-shot LLMs on the UKET prediction task. The performance of zero-shot LLMs can be enhanced by integrating task-related information into few-shot examples. We hope that the CLC-UKET dataset, along with human annotations and empirical findings, can serve as a valuable benchmark for employment-related dispute resolution.
Automatic Information Extraction From Employment Tribunal Judgements Using Large Language Models
Mar 19, 2024Court transcripts and judgments are rich repositories of legal knowledge, detailing the intricacies of cases and the rationale behind judicial decisions. The extraction of key information from these documents provides a concise overview of a case, crucial for both legal experts and the public. With the advent of large language models (LLMs), automatic information extraction has become increasingly feasible and efficient. This paper presents a comprehensive study on the application of GPT-4, a large language model, for automatic information extraction from UK Employment Tribunal (UKET) cases. We meticulously evaluated GPT-4's performance in extracting critical information with a manual verification process to ensure the accuracy and relevance of the extracted data. Our research is structured around two primary extraction tasks: the first involves a general extraction of eight key aspects that hold significance for both legal specialists and the general public, including the facts of the case, the claims made, references to legal statutes, references to precedents, general case outcomes and corresponding labels, detailed order and remedies and reasons for the decision. The second task is more focused, aimed at analysing three of those extracted features, namely facts, claims and outcomes, in order to facilitate the development of a tool capable of predicting the outcome of employment law disputes. Through our analysis, we demonstrate that LLMs like GPT-4 can obtain high accuracy in legal information extraction, highlighting the potential of LLMs in revolutionising the way legal information is processed and utilised, offering significant implications for legal research and practice.