 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Feedback Alignment Algorithms to train Neural Networks: Why do they Align?
Jun 04, 2023Feedback alignment algorithms are an alternative to backpropagation to train neural networks, whereby some of the partial derivatives that are required to compute the gradient are replaced by random terms. This essentially transforms the update rule into a random walk in weight space. Surprisingly, learning still works with those algorithms, including training of deep neural networks. This is generally attributed to an alignment of the update of the random walker with the true gradient - the eponymous gradient alignment -- which drives an approximate gradient descend. The mechanism that leads to this alignment remains unclear, however. In this paper, we use mathematical reasoning and simulations to investigate gradient alignment. We observe that the feedback alignment update rule has fixed points, which correspond to extrema of the loss function. We show that gradient alignment is a stability criterion for those fixed points. It is only a necessary criterion for algorithm performance. Experimentally, we demonstrate that high levels of gradient alignment can lead to poor algorithm performance and that the alignment is not always driving the gradient descend.
Directional Direct Feedback Alignment: Estimating Backpropagation Paths for Efficient Learning on Neural Processors
Dec 16, 2022The error Backpropagation algorithm (BP) is a key method for training deep neural networks. While performant, it is also resource-demanding in terms of computation, memory usage and energy. This makes it unsuitable for online learning on edge devices that require a high processing rate and low energy consumption. More importantly, BP does not take advantage of the parallelism and local characteristics offered by dedicated neural processors. There is therefore a demand for alternative algorithms to BP that could improve the latency, memory requirements, and energy footprint of neural networks on hardware. In this work, we propose a novel method based on Direct Feedback Alignment (DFA) which uses Forward-Mode Automatic Differentiation to estimate backpropagation paths and learn feedback connections in an online manner. We experimentally show that Directional DFA achieves performances that are closer to BP than other feedback methods on several benchmark datasets and architectures while benefiting from the locality and parallelization characteristics of DFA. Moreover, we show that, unlike other feedback learning algorithms, our method provides stable learning for convolution layers.
Exact Error Backpropagation Through Spikes for Precise Training of Spiking Neural Networks
Dec 15, 2022Event-based simulations of Spiking Neural Networks (SNNs) are fast and accurate. However, they are rarely used in the context of event-based gradient descent because their implementations on GPUs are difficult. Discretization with the forward Euler method is instead often used with gradient descent techniques but has the disadvantage of being computationally expensive. Moreover, the lack of precision of discretized simulations can create mismatches between the simulated models and analog neuromorphic hardware. In this work, we propose a new exact error-backpropagation through spikes method for SNNs, extending Fast \& Deep to multiple spikes per neuron. We show that our method can be efficiently implemented on GPUs in a fully event-based manner, making it fast to compute and precise enough for analog neuromorphic hardware. Compared to the original Fast \& Deep and the current state-of-the-art event-based gradient-descent algorithms, we demonstrate increased performance on several benchmark datasets with both feedforward and convolutional SNNs. In particular, we show that multi-spike SNNs can have advantages over single-spike networks in terms of convergence, sparsity, classification latency and sensitivity to the dead neuron problem.
Integrate-and-Fire Neurons for Low-Powered Pattern Recognition
Jun 28, 2021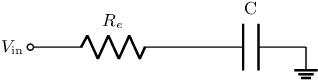


Embedded systems acquire information about the real world from sensors and process it to make decisions and/or for transmission. In some situations, the relationship between the data and the decision is complex and/or the amount of data to transmit is large (e.g. in biologgers). Artificial Neural Networks (ANNs) can efficiently detect patterns in the input data which makes them suitable for decision making or compression of information for data transmission. However, ANNs require a substantial amount of energy which reduces the lifetime of battery-powered devices. Therefore, the use of Spiking Neural Networks can improve such systems by providing a way to efficiently process sensory data without being too energy-consuming. In this work, we introduce a low-powered neuron model called Integrate-and-Fire which exploits the charge and discharge properties of the capacitor. Using parallel and series RC circuits, we developed a trainable neuron model that can be expressed in a recurrent form. Finally, we trained its simulation with an artificially generated dataset of dog postures and implemented it as hardware that showed promising energetic properties. This paper is the full text of the research, presented at the 20th International Conference on Artificial Intelligence and Soft Computing Web System (ICAISC 2021)
Linear Constraints Learning for Spiking Neurons
Mar 10, 2021


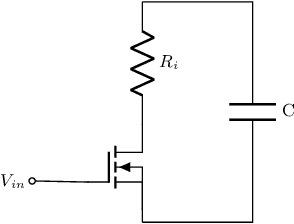
Encoding information with precise spike timings using spike-coded neurons has been shown to be more computationally powerful than rate-coded approaches. However, most existing supervised learning algorithms for spiking neurons are complicated and offer poor time complexity. To address these limitations, we propose a supervised multi-spike learning algorithm which reduces the required number of training iterations. We achieve this by formulating a large number of weight updates as a linear constraint satisfaction problem, which can be solved efficiently. Experimental results show this method offers better efficiency compared to existing algorithms on the MNIST dataset. Additionally, we provide experimental results on the classification capacity of the LIF neuron model, relative to several parameters of the system.
Constraints on Hebbian and STDP learned weights of a spiking neuron
Dec 14, 2020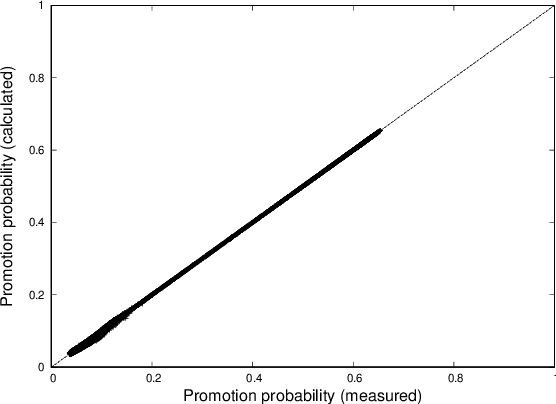
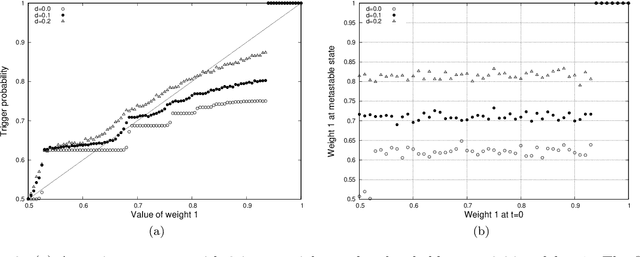
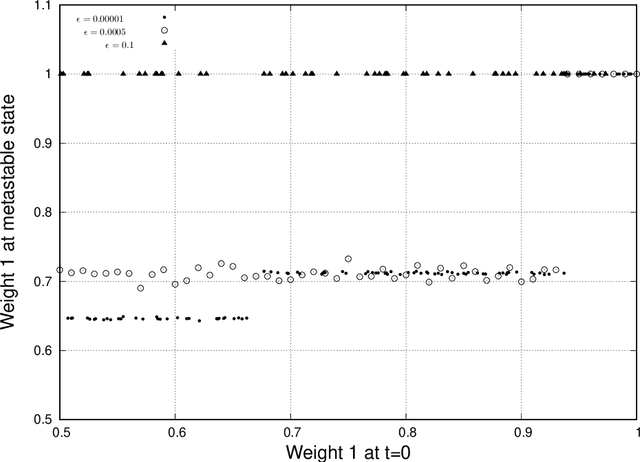
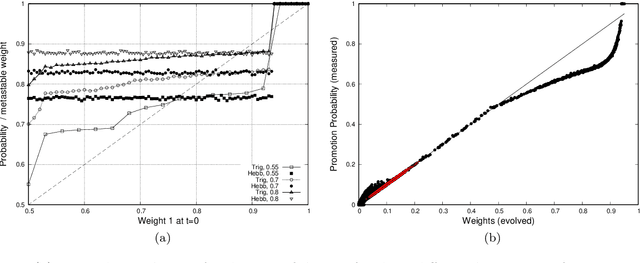
We analyse mathematically the constraints on weights resulting from Hebbian and STDP learning rules applied to a spiking neuron with weight normalisation. In the case of pure Hebbian learning, we find that the normalised weights equal the promotion probabilities of weights up to correction terms that depend on the learning rate and are usually small. A similar relation can be derived for STDP algorithms, where the normalised weight values reflect a difference between the promotion and demotion probabilities of the weight. These relations are practically useful in that they allow checking for convergence of Hebbian and STDP algorithms. Another application is novelty detection. We demonstrate this using the MNIST dataset.
A thermodynamically consistent chemical spiking neuron capable of autonomous Hebbian learning
Sep 28, 2020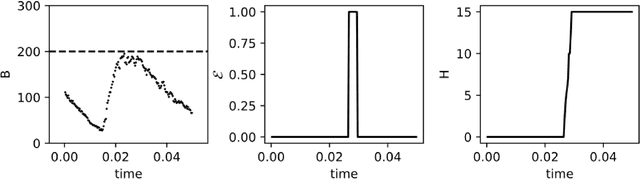

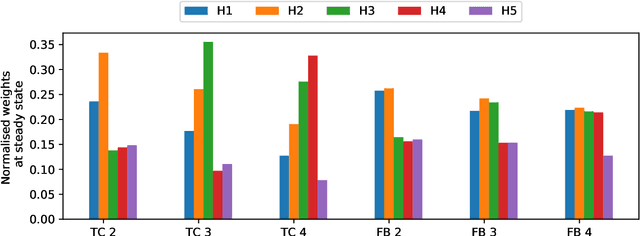
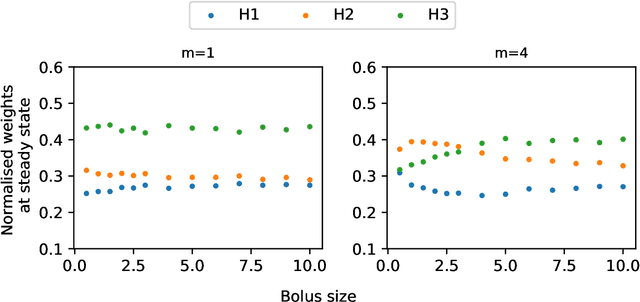
We propose a fully autonomous, thermodynamically consistent set of chemical reactions that implements a spiking neuron. This chemical neuron is able to learn input patterns in a Hebbian fashion. The system is scalable to arbitrarily many input channels. We demonstrate its performance in learning frequency biases in the input as well as correlations between different input channels. Efficient computation of time-correlations requires a highly non-linear activation function. The resource requirements of a non-linear activation function are discussed. In addition to the thermodynamically consistent model of the CN, we also propose a biologically plausible version that could be engineered in a synthetic biology context.
Minimal spiking neuron for solving multi-label classification tasks
Mar 05, 2020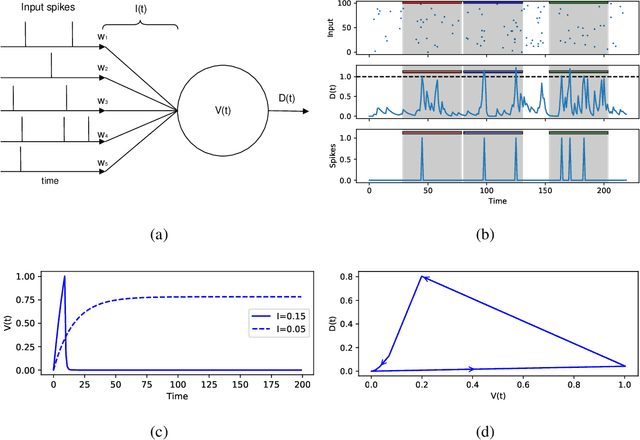
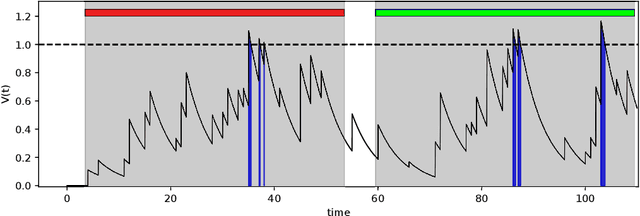
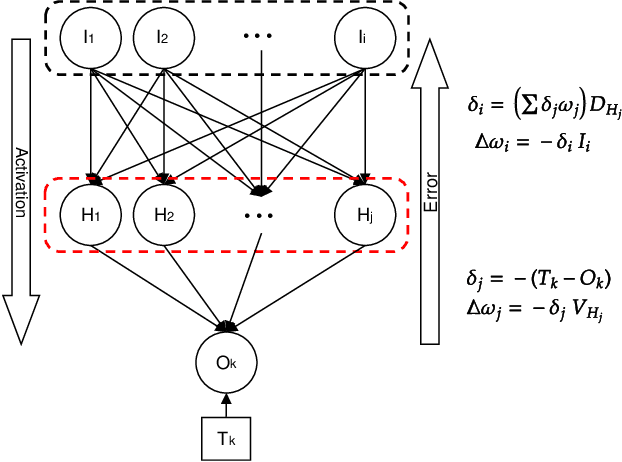
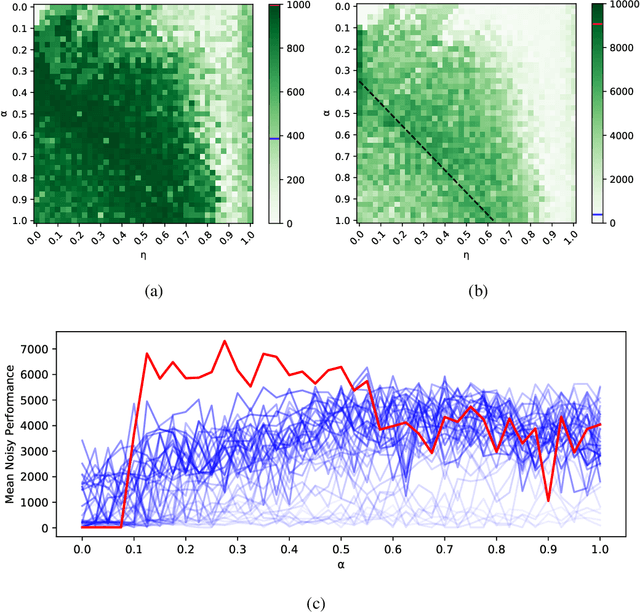
The Multi-Spike Tempotron (MST) is a powerful single spiking neuron model that can solve complex supervised classification tasks. While powerful, it is also internally complex, computationally expensive to evaluate, and not suitable for neuromorphic hardware. Here we aim to understand whether it is possible to simplify the MST model, while retaining its ability to learn and to process information. To this end, we introduce a family of Generalised Neuron Models (GNM) which are a special case of the Spike Response Model and much simpler and cheaper to simulate than the MST. We find that over a wide range of parameters the GNM can learn at least as well as the MST. We identify the temporal autocorrelation of the membrane potential as the single most important ingredient of the GNM which enables it to classify multiple spatio-temporal patterns. We also interpret the GNM as a chemical system, thus conceptually bridging computation by neural networks with molecular information processing. We conclude the paper by proposing alternative training approaches for the GNM including error trace learning and error backpropagation.