 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXSleepNet: Multi-View Sequential Model for Automatic Sleep Staging
Paper and Code
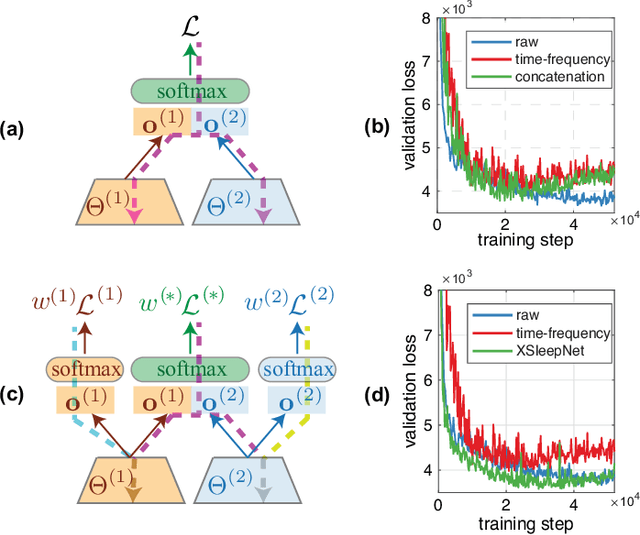

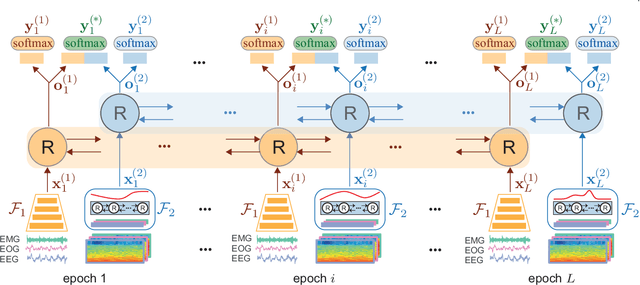
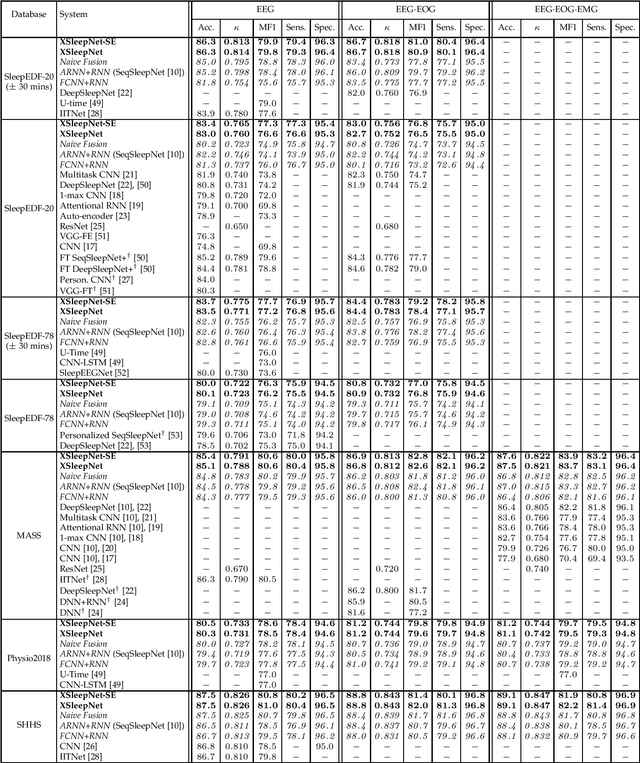
Automating sleep staging is vital to scale up sleep assessment and diagnosis to millions of people experiencing sleep deprivation and disorders and to enable longitudinal sleep monitoring in home environments. Learning from raw polysomnography signals and their derived time-frequency images has been prevalent. However, learning from multi-view inputs (e.g. both the raw signals and the time-frequency images) for sleep staging is difficult and not well understood. This work proposes a sequence-to-sequence sleep staging model, XSleepNet, that is capable of learning a joint representation from both raw signals and time-frequency images effectively. Since different views often generalize (and overfit) at different rates, the proposed network is trained in such a way that the learning pace on each view is adapted based on their generalization/overfitting behavior. In simple terms, the learning on a particular view is speeded up when it is generalizing well and slowed down when it is overfitting. View-specific generalization/overfitting measures are computed on-the-fly during the training course and used to derive weights to blend the gradients from different views. As a result, the network is able to retain representation power of different views in the joint features which represent the underlying distribution better than those learned by each individual view alone. Furthermore, the XSleepNet architecture is principally designed to gain robustness to the amount of training data and to increase the complementarity between the input views. Experimental results on five databases of different size show that XSleepNet consistently results in better performance than the single-view baselines as well as the multi-view baseline with a simple fusion strategy. Finally, XSleepNet outperforms all prior sleep staging methods and sets new state-of-the-art results on the experimental databases.