 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAADNet: An End-to-End Deep Learning Model for Auditory Attention Decoding
Oct 16, 2024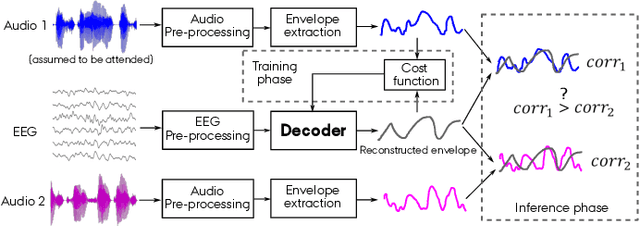
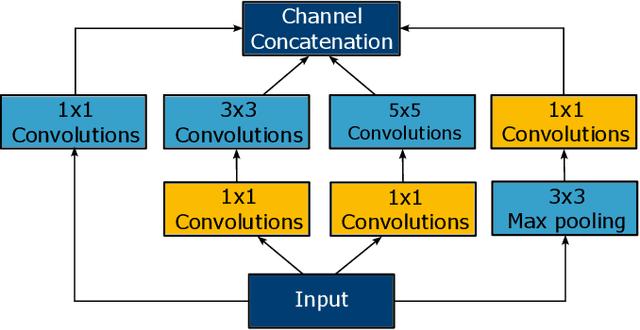
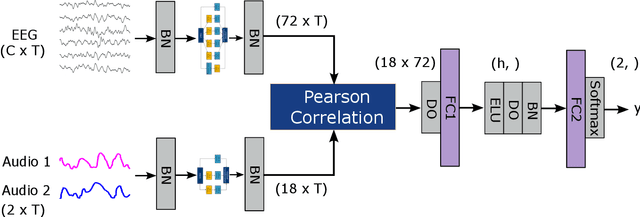
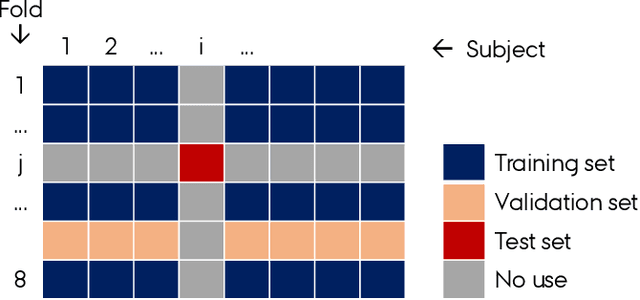
Auditory attention decoding (AAD) is the process of identifying the attended speech in a multi-talker environment using brain signals, typically recorded through electroencephalography (EEG). Over the past decade, AAD has undergone continuous development, driven by its promising application in neuro-steered hearing devices. Most AAD algorithms are relying on the increase in neural entrainment to the envelope of attended speech, as compared to unattended speech, typically using a two-step approach. First, the algorithm predicts representations of the attended speech signal envelopes; second, it identifies the attended speech by finding the highest correlation between the predictions and the representations of the actual speech signals. In this study, we proposed a novel end-to-end neural network architecture, named AADNet, which combines these two stages into a direct approach to address the AAD problem. We compare the proposed network against the traditional approaches, including linear stimulus reconstruction, canonical correlation analysis, and an alternative non-linear stimulus reconstruction using two different datasets. AADNet shows a significant performance improvement for both subject-specific and subject-independent models. Notably, the average subject-independent classification accuracies from 56.1 % to 82.7 % with analysis window lengths ranging from 1 to 40 seconds, respectively, show a significantly improved ability to generalize to data from unseen subjects. These results highlight the potential of deep learning models for advancing AAD, with promising implications for future hearing aids, assistive devices, and clinical assessments.
Study of cognitive component of auditory attention to natural speech events
Dec 19, 2023
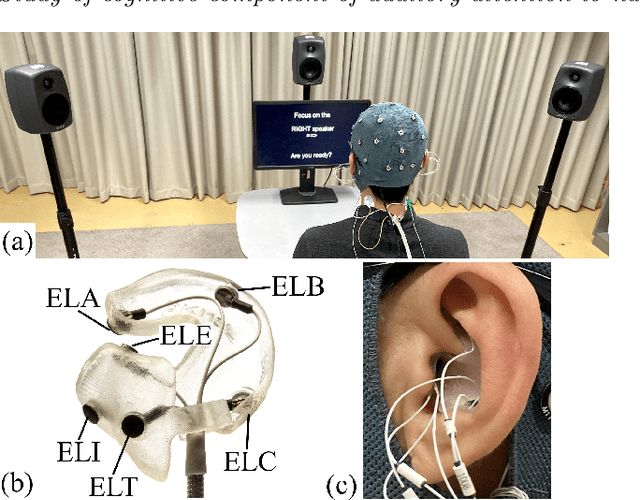
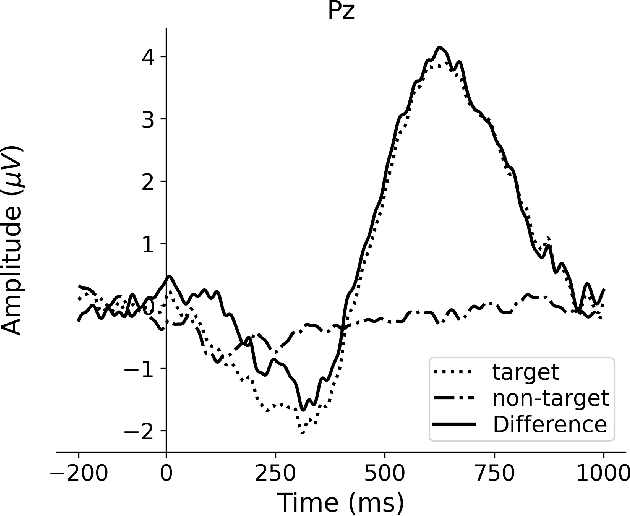
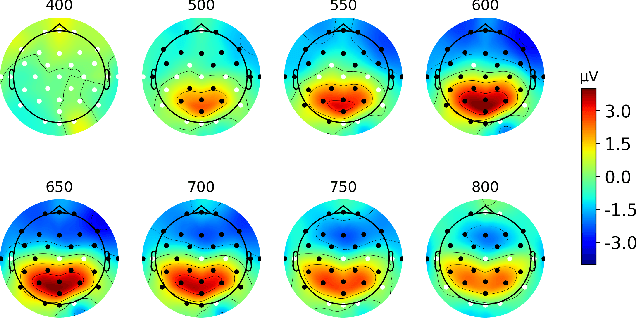
Event-related potentials (ERP) have been used to address a wide range of research questions in neuroscience and cognitive psychology including selective auditory attention. The recent progress in auditory attention decoding (AAD) methods is based on algorithms that find a relation between the audio envelope and the neurophysiological response. The most popular approach is based on the reconstruction of the audio envelope based on EEG signals. However, these methods are mainly based on the neurophysiological entrainment to physical attributes of the sensory stimulus and are generally limited by a long detection window. This study proposes a novel approach to auditory attention decoding by looking at higher-level cognitive responses to natural speech. To investigate if natural speech events elicit cognitive ERP components and how these components are affected by attention mechanisms, we designed a series of four experimental paradigms with increasing complexity: a word category oddball paradigm, a word category oddball paradigm with competing speakers, and competing speech streams with and without specific targets. We recorded the electroencephalogram (EEG) from 32 scalp electrodes and 12 in-ear electrodes (ear-EEG) from 24 participants. A cognitive ERP component, which we believe is related to the well-known P3b component, was observed at parietal electrode sites with a latency of approximately 620 ms. The component is statistically most significant for the simplest paradigm and gradually decreases in strength with increasing complexity of the paradigm. We also show that the component can be observed in the in-ear EEG signals by using spatial filtering. The cognitive component elicited by auditory attention may contribute to decoding auditory attention from electrophysiological recordings and its presence in the ear-EEG signals is promising for future applications within hearing aids.
L-SeqSleepNet: Whole-cycle Long Sequence Modelling for Automatic Sleep Staging
Jan 25, 2023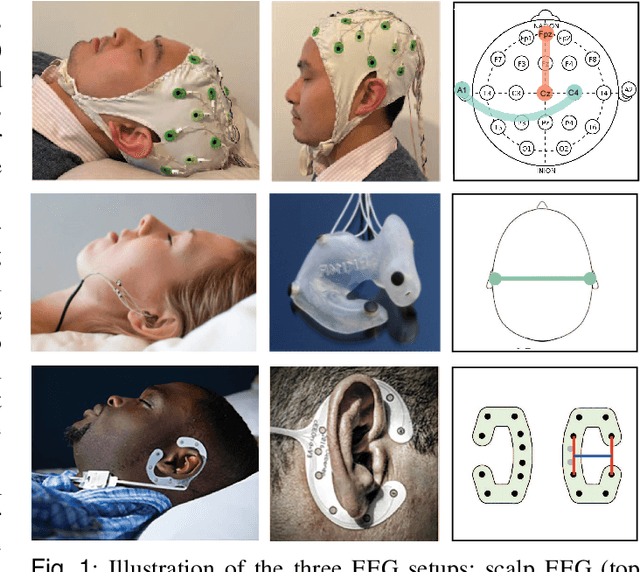
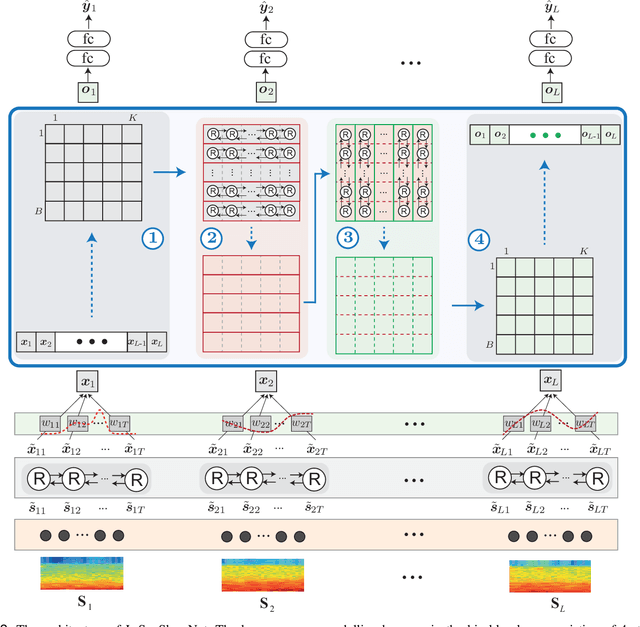
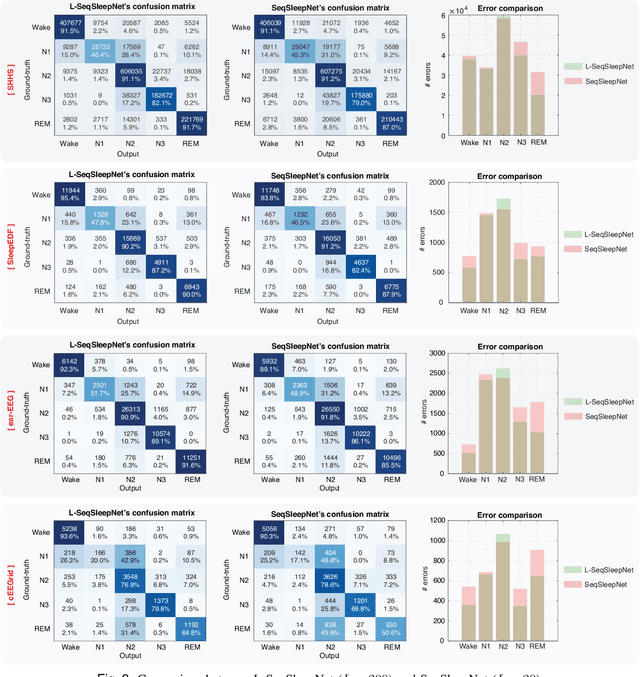
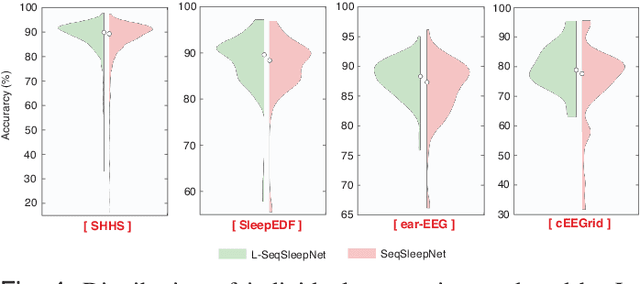
Human sleep is cyclical with a period of approximately 90 minutes, implying long temporal dependency in the sleep data. Yet, exploring this long-term dependency when developing sleep staging models has remained untouched. In this work, we show that while encoding the logic of a whole sleep cycle is crucial to improve sleep staging performance, the sequential modelling approach in existing state-of-the-art deep learning models are inefficient for that purpose. We thus introduce a method for efficient long sequence modelling and propose a new deep learning model, L-SeqSleepNet, which takes into account whole-cycle sleep information for sleep staging. Evaluating L-SeqSleepNet on four distinct databases of various sizes, we demonstrate state-of-the-art performance obtained by the model over three different EEG setups, including scalp EEG in conventional Polysomnography (PSG), in-ear EEG, and around-the-ear EEG (cEEGrid), even with a single EEG channel input. Our analyses also show that L-SeqSleepNet is able to alleviate the predominance of N2 sleep (the major class in terms of classification) to bring down errors in other sleep stages. Moreover the network becomes much more robust, meaning that for all subjects where the baseline method had exceptionally poor performance, their performance are improved significantly. Finally, the computation time only grows at a sub-linear rate when the sequence length increases.
Automatic Sleep Staging: Recent Development, Challenges, and Future Directions
Nov 03, 2021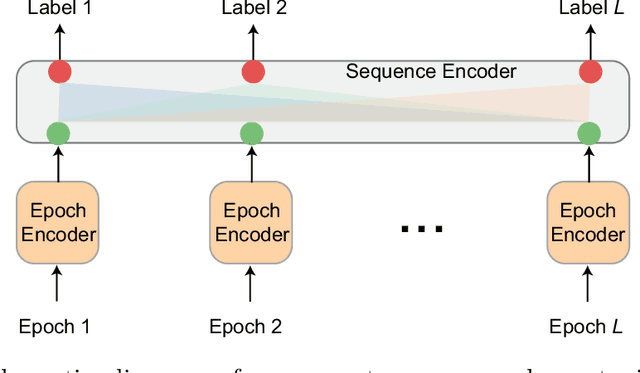
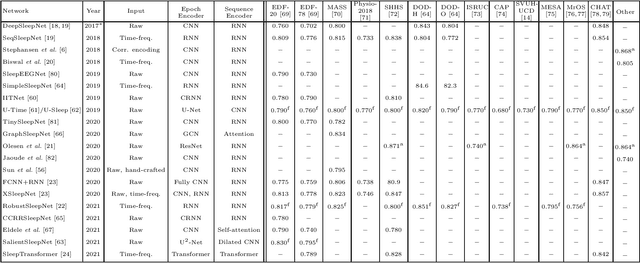
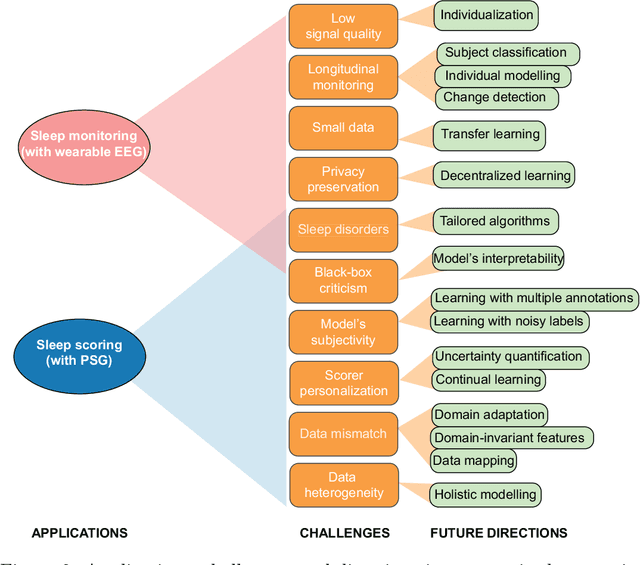
Modern deep learning holds a great potential to transform clinical practice on human sleep. Teaching a machine to carry out routine tasks would be a tremendous reduction in workload for clinicians. Sleep staging, a fundamental step in sleep practice, is a suitable task for this and will be the focus in this article. Recently, automatic sleep staging systems have been trained to mimic manual scoring, leading to similar performance to human sleep experts, at least on scoring of healthy subjects. Despite tremendous progress, we have not seen automatic sleep scoring adopted widely in clinical environments. This review aims to give a shared view of the authors on the most recent state-of-the-art development in automatic sleep staging, the challenges that still need to be addressed, and the future directions for automatic sleep scoring to achieve clinical value.
SleepTransformer: Automatic Sleep Staging with Interpretability and Uncertainty Quantification
May 23, 2021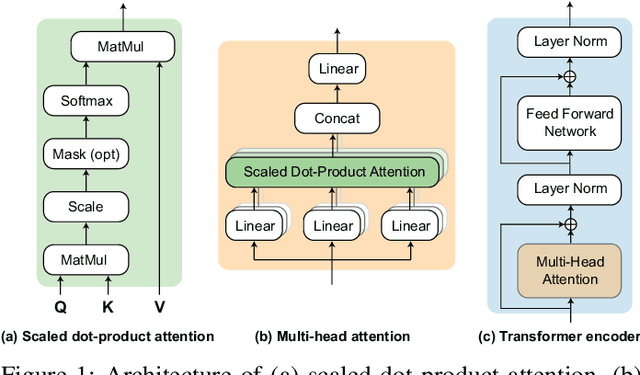
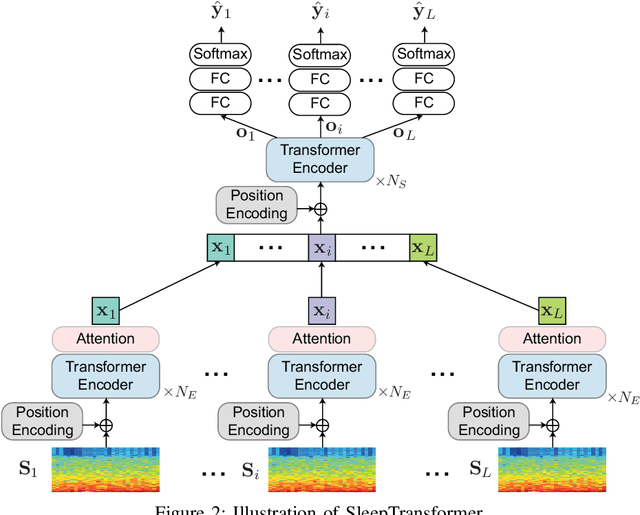

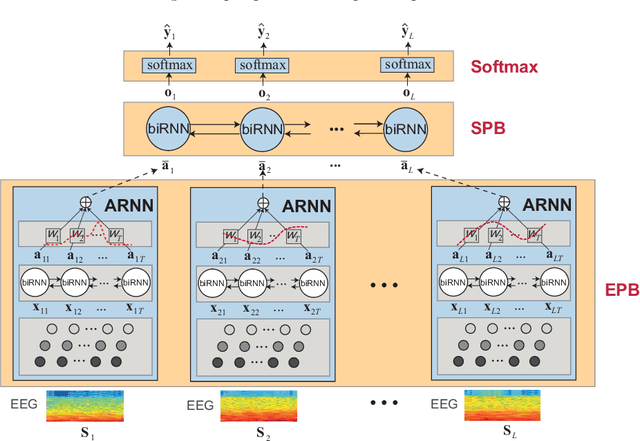
Black-box skepticism is one of the main hindrances impeding deep-learning-based automatic sleep scoring from being used in clinical environments. Towards interpretability, this work proposes a sequence-to-sequence sleep-staging model, namely SleepTransformer. It is based on the transformer backbone whose self-attention scores offer interpretability of the model's decisions at both the epoch and sequence level. At the epoch level, the attention scores can be encoded as a heat map to highlight sleep-relevant features captured from the input EEG signal. At the sequence level, the attention scores are visualized as the influence of different neighboring epochs in an input sequence (i.e. the context) to recognition of a target epoch, mimicking the way manual scoring is done by human experts. We further propose a simple yet efficient method to quantify uncertainty in the model's decisions. The method, which is based on entropy, can serve as a metric for deferring low-confidence epochs to a human expert for further inspection. Additionally, we demonstrate that the proposed SleepTransformer outperforms existing methods at a lower computational cost and achieves state-of-the-art performance on two experimental databases of different sizes.
Personalized Automatic Sleep Staging with Single-Night Data: a Pilot Study with KL-Divergence Regularization
May 11, 2020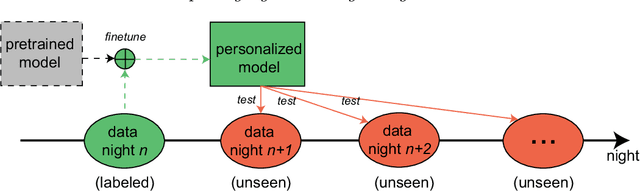
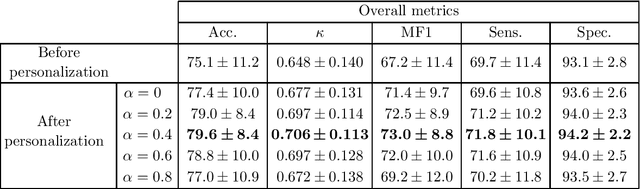
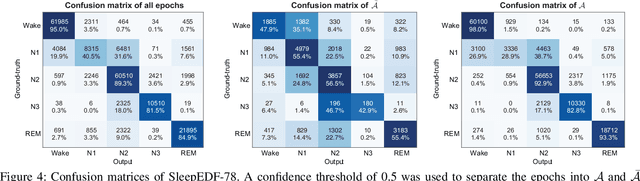
Brain waves vary between people. An obvious way to improve automatic sleep staging for longitudinal sleep monitoring is personalization of algorithms based on individual characteristics extracted from the first night of data. As a single night is a very small amount of data to train a sleep staging model, we propose a Kullback-Leibler (KL) divergence regularized transfer learning approach to address this problem. We employ the pretrained SeqSleepNet (i.e. the subject independent model) as a starting point and finetune it with the single-night personalization data to derive the personalized model. This is done by adding the KL divergence between the output of the subject independent model and the output of the personalized model to the loss function during finetuning. In effect, KL-divergence regularization prevents the personalized model from overfitting to the single-night data and straying too far away from the subject independent model. Experimental results on the Sleep-EDF Expanded database with 75 subjects show that sleep staging personalization with a single-night data is possible with help of the proposed KL-divergence regularization. On average, we achieve a personalized sleep staging accuracy of 79.6%, a Cohen's kappa of 0.706, a macro F1-score of 73.0%, a sensitivity of 71.8%, and a specificity of 94.2%. We find both that the approach is robust against overfitting and that it improves the accuracy by 4.5 percentage points compared to non-personalization and 2.2 percentage points compared to personalization without regularization.